- 前言
- 关键词
- 本书结构
- 第 1 章 计算机的三大原则
- 第 2 章 试着制造一台计算机吧
- 第 3 章 体验一次手工汇编
- 第 4 章 程序像河水一样流动着
- 第 5 章 与算法成为好朋友的七个要点
- 第 6 章 与数据结构成为好朋友的七个要点
- 第 7 章 成为会使用面向对象编程的程序员吧
- 第 8 章 一用就会的数据库
- 第 9 章 通过七个简单的实验理解 TCP/IP 网络
- 第 10 章 试着加密数据吧
- 第 11 章 XML 究竟是什么
- 第 12 章 SE 负责监管计算机系统的构建
- 结束语
- 谢辞
- 程序是怎样跑起来的
- 参考资料
前言
我从 10 年前开始担任企业培训的讲师。培训的对象有时是新入职的员工,有时是入职了多年的骨干员工。 这期间通过与一些勉强算是计算机专家的年轻工程师接触,我感到与过去的工程师(计算机发烧友)相比,他们对技术的兴趣少得可怜。 并不是说所有的培训对象都如此,但这样的工程师确实占多数。这并不是大吼着命令他们继续学习或用激将法嘲讽他们的专业性就能解决的问题。 究其根源,是因为计算机对他们来说,并没有有意思到可以令他们废寝忘食的地步。为什么他们会觉得计算机没意思呢? 通过和多名培训对象的交流,我渐渐找到了答案。因为他们不了解计算机。然而,又是什么造成了他们的“不了解”呢?
今天,计算机正在以惊人的速度发展变化着,变得越来越复杂,而这期间产生了许多技术, 但是人们并没有过多的时间去深入学习每一门技术,这就是问题的根源。稍微看了看技术手册,只学到了表层的使用方法, 觉得自己“反正已经达到目的了”,这就是现状。如果仅仅把技术当作一个黑盒,只把时间花在学习其表面上, 而并没有探索到其本质,就绝不应该认为自己已经“懂”了。不懂的话,做起来就会感到没意思,也就更不会产生想要深入学习的欲望了。 若每日使用的都是些不知其所以然的技术,就会渐渐不安起来。令人感到遗憾的是,还有一些人在计算机行业遇到挫折后, 就选择了离开这个行业。身为一名教授计算机技术的讲师,我由衷地感到自己应该想办法改变这种现状。
对于笔者以及昔日的计算机发烧友而言,虽然大家现在都已经 40 岁左右了,但即使是面对复杂的最新技术, 似乎也还是可以轻松掌握的。其原因在于,从可以轻松买到最初的 8 比特微型计算机的那个时候开始,我们就幸运地接触到了计算机。 面对为数不多的技术,我们可以从容地把时间花在学习计算机的基础知识上。而这些基础知识,即使到了今天也完全没有变化。 因此,即便面对的是复杂的最新技术,一旦把它们回归到计算机的基础知识上,就变得可以轻松理解了。 就算是和年轻的工程师们阅读同样的技术手册,我们领会其中的要点、抓住其本质的速度也要快得多。
其实不仅是计算机,其他学问亦是如此。首先要划出一个“知识的范围”,精通一门学问所必知必会的知识都在这个范围内。 其次是掌握该范围内每个知识点中“基础中的基础知识”。最后是能独当一面的“目标”,即掌握了这些知识可以做什么。 下面就以学习音乐为例说明这三点。首先,划出的“知识范围”是节奏、旋律、和弦这三个知识点。所谓“基础中的基础知识”, 对于节奏来说就是四拍子(大、大、大、大),对于旋律来说就是 C 大调(do re mi fa so la si do), 对于和弦来说就是大三和弦(do mi so)。以四拍子为基础就能理解更加复杂的三拍子或五拍子; 以 C 大调为基础就能理解更加复杂的降 B 小调;以大三和弦为基础就能理解更加复杂的减三和弦。 而最终的“目标”就是能够自己作曲并演奏,尽管这时仅能完成很简单的曲子。
本书的目的是想让诸位了解有关计算机技术的知识范围,掌握其基础中的基础知识,设定目标; 同时又想让那些打算用计算机做点什么,却又因难以下手而犹豫不决的人,以及虽然就职于计算机行业, 却又因追赶不上最新技术而苦恼的人,能够了解计算机的本质。其实计算机非常简单,谁都能掌握。 只要掌握了,计算机就会越来越有趣。
【矢泽久雄】
关键词
本书将要讲解的主要关键词
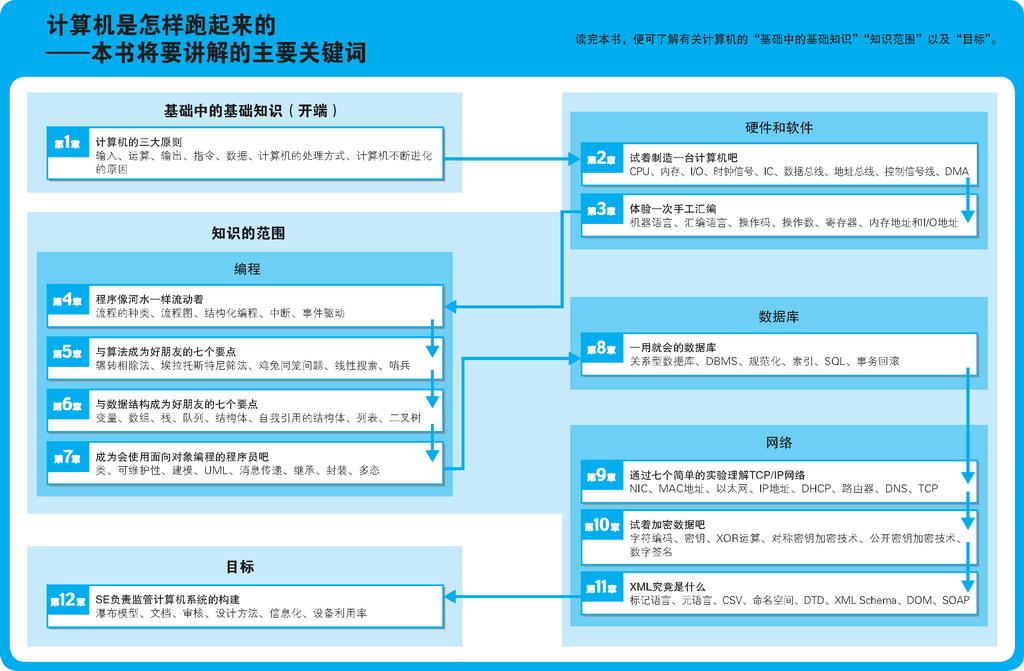
本书结构
本书共分为 12 章,每章由热身问答、本章要点和正文三部分构成。全书还穿插了 2 个专栏。
- 热身问答
在各章的开头部分设有简单的问题作为热身活动,请诸位务必挑战一下。设置这一部分的目的,是为了让诸位能带着问题阅读正文的内容。
- 本章重点
各章的本章要点部分揭示了正文的主题。诸位可以读一读,以确认这一章中是否有想要了解的内容。
- 正文
正文部分会以讲座的方式,从各章要点中提到的角度出发,对计算机的运行机制予以解释说明。 其中还会出现用 Visual Basic 或 C 语言等编程语言编写的示例程序,编写时已力求精简,即便是没有编程经验的读者也能看懂。
- 专栏“来自企业培训现场”
专栏部分将会与诸位分享笔者自担任讲师以来,从培训现场收集来的各种各样的轶事。 诸位可以时而站在讲师的角度、时而站在听众的角度读一读这部分。专栏部分不仅有严肃认真的话题,更有有趣逗乐的笑话,想必会对诸位有所帮助。
第 1 章 计算机的三大原则
- 热身问答
在阅读本章内容前,让我们先回答下面的几个问题来热热身吧。
问题:
初级问题:硬件和软件的区别是什么?
中级问题:存储字符串“中国”需要几个字节?
高级问题:什么是编码(Code)?
怎么样?被这么一问,是不是发现有一些问题无法简单地解释清楚呢?下面,笔者就公布答案并解释。
- 答案
初级问题:硬件是看得见摸得着的设备,比如计算机主机、显示器、键盘等。而软件是计算机所执行的程序,即指令和数据。软件本身是看不见的。
中级问题:在 GBK 字符编码下,存储“中国”需要 4 个字节。
高级问题:通常将为了便于计算机处理而经过数字化处理的信息称作编码。
- 解释
初级问题:硬件(Hardware)代表“硬的东西”,而软件(Software)代表“软的东西”。是硬的还是软的取决于眼睛能否看得到,或者实际上能否用手摸到。
中级问题:存储汉字时,字符编码不同,汉字所占用的字节数也就不同。在 GBK 字符编码下,一个汉字占用 2 个字节。而在 UTF-8 字符编码下,一个汉字占用 3 个字节。
高级问题:计算机内部会把所有的信息都当成数字来处理,尽管有些信息本来不是数字。用于表示字符的数字是“字符编码”,用于表示颜色的数字是“颜色编码”。
- 本章重点
现在的计算机看起来好像是种高度复杂的机器,可是其基本的构造却简单得令人惊讶。从大约 50 年前的第一代计算机到现在,计算机并没有发生什么改变。在认识计算机时,需要把握的最基础的要点只有三个,我们就将这三个要点称为“计算机的三大原则”吧。无论是多么高深、多么难懂的最新技术,都可以对照着这三大原则来解释说明。
只要了解了计算机的三大原则,就会感到眼前豁然开朗了,计算机也比以往更加贴近自己了,就连新技术接连不断诞生的原因也明白了。本书以本章介绍的计算机的三大原则为基础,内容延伸至硬件和软件、编程、数据库、网络以及计算机系统。在阅读之后的章节时,也请诸位时常将计算机的三大原则放在心上。
1.1 计算机的三个根本性基础
下面就赶紧开始介绍计算机的三大原则吧。
- 计算机是执行输入、运算、输出的机器
- 程序是指令和数据的集合
- 计算机的处理方式有时与人们的思维习惯不同
计算机是由硬件和软件组成的。诸位可以把硬件和软件的区别理解成游戏机(硬件)和收录在 CD-ROM 中的游戏(软件)的区别。这样就能理解硬件和软件各自的基础了(三大原则中的第一点和第二点)。
在此之上,计算机有计算机的处理方式也是一条重要的原则。而且请诸位注意,计算机的处理方式往往不符合人们的思维习惯(三大原则中的第三点)。
计算机三大原则中的每一条,都是从事计算机行业 20 余年的笔者深切领悟出来的。诸位可以把这本书拿给你周围了解计算机的朋友看,他们应该会对你说“确实是这样的啊”“当然是这样的了”这类话。过去的计算机发烧友们在不知不觉中就能逐渐领悟出计算机的三大原则。而对于那些打算从今日开始深入接触计算机的普通人来说,三大原则中的有些地方也许一时半会儿难以理解,但是不要担心,因为下面的解释会力求让诸位都能理解三大原则的具体含义。
1.2 输入、运算、输出是硬件的基础
首先从硬件的基础开始介绍。从硬件上来看,可以说计算机是执行输入、运算、输出三种操作的机器。 计算机的硬件由大量的 IC(Integrated Circuit,集成电路)组成(如图 1.1 所示)。每块 IC 上都带有许多引脚。 这些引脚有的用于输入,有的用于输出。IC 会在其内部对外部输入的信息进行运算,并把运算结果输出到外部。 运算这个词听起来也许有些难以理解,但实际上就是计算的意思。 计算机所做的事就是“输入”数据 1 和 2,然后对它们执行加法“运算”,最后“输出”计算结果 3。

图 1.1 IC 的引脚中有些用于输入,有些用于输出
小型的 IC 自不必说,就连在观察银行的在线系统这类巨型系统时,或是编写复杂的程序时,也要时常把输入、运算、输出这三者想成是一套流程,这一点很重要。其实计算机就是台简单的机器,因为它只能做这三件事。
“你说得不对,计算机能做的事远比这些多得多。”也许会有人这样反驳笔者。的确,计算机可以做各种各样的事,比如玩游戏、处理文字、核算报表、绘图、收发电子邮件、浏览网页,等等。但是无论是多么复杂的功能,都是通过组合一个又一个由输入、运算、输出构成的流程单位来实现的,这是毋庸置疑的事实。如果打算用计算机做点什么的话,就要考虑该如何进行输入、如何获取输出以及进行怎样的运算才能从输入得到输出。
输入、运算、输出三者必须成套出现,缺一不可。这样说的原因有几点。 首先,现在的计算机还没有发展到能通过自发的思考创造出信息的地步。因此不输入信息,计算机就不能工作。 所以,输入是必不可少的。其次,计算机不可能不执行任何运算。如果只是使输入的信息绕过运算环节直接输出, 那么这就是电线而不是计算机了。可以说不进行运算,计算机也就没有什么存在的意义。 最后,输入的信息如果经过了运算,那么运算结果就必然要输出。如果不输出结果, 那么这也不是计算机而只是堆积信息的垃圾箱了。因此,输出也必不可少。
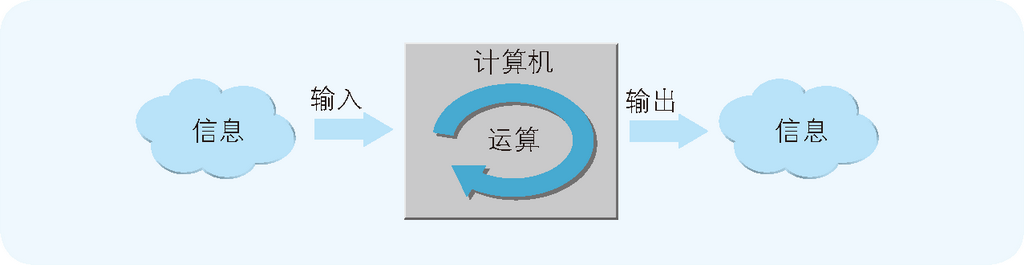
图 1.2 计算机只会输入、运算、输出
1.3 软件是指令和数据的集合
下面介绍软件,即程序的基础。所谓程序,其实非常简单,只不过是指令和数据的集合。无论程序多么高深、多么复杂,其内容也都是指令和数据。所谓指令,就是控制计算机进行输入、运算、输出的命令。把向计算机发出的指令一条条列出来,就得到了程序。这里成套出现的输入、运算、输出,就是之前在硬件的基础一节中说明过的流程。向计算机发出的指令与计算机硬件上的行为一一对应是理所当然的。
在程序设计中,会为一组指令赋予一个名字,可以称之为“函数”“语句”“方法”“子例程”“子程序”等。这里稍微说些题外话,在计算机行业,明明是同一个东西,却可以用各种各样的术语来指代它,这种现象请诸位注意。如果只想用一个名字的话,一般情况下笔者推荐称之为函数,因为这个名字通俗易懂。
程序中的数据分为两类,一类是作为指令执行对象的输入数据,一类是从指令的执行结果得到的输出数据。在编程时程序员会为数据赋予名字,称其为“变量”。看到变量和函数,诸位也许会联想到数学吧。正如数学中函数的表记方法那样,在很多编程语言中都使用着类似于下面的这种语法。
y = f(x)
这句话表示若把变量 x 输入到函数 f 中,经过函数内部的某种运算后,其结果就会输出到变量 y 中。因为计算机是先把所有的信息都表示成数字后才对其进行运算的,所以编程语言的语法类似数学算式也就不足为奇了。但是在程序中有一点与数学不同的是,变量和函数的名字都可以由一个以上的字符构成,比如下面这种情况。
output = operate(input)
也就是说,使用由多个字符构成的长名字也是可以的。甚至可以说,写成这样的情况更加普遍。
下面我们就举一个例子作为证据来证明程序是指令和数据的集合。请诸位看代码清单 1.1。
代码清单 1.1 C 语言的程序示例片段
int a, b ,c;
a = 10;
b = 20;
c = Average(a, b);
这里列出了一段用名为 C 语言的编程语言编写的程序。C 语言中要在每条指令的末尾写一个分号“;”。 第一行的“int a, b, c;”表示接下来要使用名为 a、b、c 的整数变量,其中 int 是 integer(整数)的缩写, 用于告诉计算机“要用的是整数”。下一行的“a = 10”表示把整数 10 赋值给变量 a。 同样地,“b = 20;”表示把整数 20 赋值给变量 b。等号“=”是赋值给变量的指令。 再来看最后一行的“c = Average(a, b);”,这一行表示把变量 a 和 b 传给函数的参数,并将运算结果赋值给变量 c。 其中使用了一个名为 Average 的神秘函数,它的作用是返回两个参数的平均值。 通过上面这个例子,诸位就应该能明白程序确实只是由指令和数据构成的了吧。
虽然程序就是这样,但是那些稍微有些编程经验的人也许会说:代码清单 1.1 所示的程序逻辑简单,而真正的程序是使用了各种各样的语法、比这复杂得多得多的东西,绝不是用指令和数据的集合就能解释清楚的。其实并不是像他们想的那样,无论是多么复杂的程序,都只不过是指令和数据的集合。下面我们再拿出一个证据。
在一般的编程过程中,都要先编译再执行。所谓编译就是把用 C 语言等编程语言编写的文件(源文件)转换成用机器语言(原生代码)编写的文件。假设我们先把代码清单 1.1 中的代码保存到文件 MyProg.c 中,然后经过编译就可以生成可执行的程序文件 MyProg.exe 了。接下来使用能查看文件内容的工具查看 MyProg.exe,其内容应该与代码清单 1.2 类似。可以看到里面仅仅是数值的罗列(这里用十六进制数表示)。
代码清单 1.2 机器语言的程序示例
C7 45 FC 01 00 00 00 C7 45 F8 02 00 00 00 8B 45
F8 50 8B 4D FC 51 E8 82 FF FF FF 83 C4 08 89 45
F4 8B 55 F4 52 68 1C 30 42 00 E8 B9 03 00 00 83
请选择一个代码清单 1.2 中的数值,随便哪个都可以。这个数值代表什么呢?是表示赋值或加法等指令的种类呢,还是表示将成为指令执行对象的数据呢?也有这样的可能(不过这终归是想象),第一个数值 C7 表示指令,第二个数值 45 表示数据。在诸位所使用的 Windows 个人计算机中,应该会有若干个以 .exe 为扩展名的可执行程序文件。无论是哪个程序,其内容都是数值的罗列,每个数值要么是指令,要么是数据。
1.4 对计算机来说什么都是数字
计算机有计算机的处理方法,这是三大原则中的最后一点。计算机本身只不过是为我们处理特定工作的机器。如果计算机能自己干活的话,那么笔者一定会买几百台,让它们先替自己完成一整年的工作。但是,并没有这种会挣钱的计算机,计算机终究只是受人支配的工具。
迄今为止,使用计算机的目的就是为了提高手工作业的效率。例如,文字处理软件可以提高编写文档的效率;电子邮件可以提高传统邮件寄送的效率。总之,作为可以提高工作效率的工具,有些靠手工作业完成的业务可以直接交给计算机处理。但是也有很多手工作业无法直接由计算机处理。也就是说,在用计算机替代手工作业的过程中,要想顺应计算机的处理方法,有时就要违背人们的思维习惯。请诸位特别留心这一点。
用数字表示所有信息,这就是一个很具有代表性的计算机式的处理方法,这一点也正是和人类的思维习惯最不一样的地方。例如,人们会用“蓝色”“红色”之类的词语描述有关颜色的信息。可是换作计算机的话,就不得不用数字表示颜色信息。例如,用“0,0,255”表示蓝色,用“255,0,0”表示红色,用“255,0,255”表示由蓝色和红色混合而成的紫色。不光是颜色,计算机对文字的处理也是如此。计算机内部会先把文字转换成相应的数字再做处理,这样的数字叫作“字符编码”。总之计算机会把什么都用数字来表示。
熟悉计算机的人经常会说出一些令人费解的话,例如“在这里打开文件,获得文件句柄”“把用公钥加密后的文件用私钥解密”。那么,他们所说的“文件句柄”是什么呢? —— 是数字。“公钥”是什么呢?——是数字。“私钥”呢?——当然还是数字。无论计算机所处理的信息是什么形式,只要把它们都当成是数字就可以了。虽然这有些违背人们的思维习惯,但是处理数字对计算机来说却是非常简单的。
下面笔者就讲一件自己年轻时的糗事吧。事情发生在一次与老程序员探讨问题时,我问他:“用某某程序处理的某某数据,在计算机内部也是用数字表示的吧?”老程序员听后,吃惊得张开了嘴,回了一句:“这不是明摆着吗 !”
1.5 只要理解了三大原则,即使遇到难懂的最新技术,也能轻松应对
有关计算机三大原则的说明到此结束。只要理解了这三大原则,即使遇到难懂的最新技术,也能轻松应对。下面就给诸位看一个具体的例子。这里摘录了一段有关 .NET 技术的介绍,.NET 是微软公司率先提出的一种新技术。如果要正式地介绍 .NET 技术,就会像下面这样进行说明。
【有关 .NET 的说明之一】
微软公司率先提出了作为新一代互联网平台的 .NET 技术。作为 .NET 核心的 XML Web 服务使用通用技术 SOAP、XML,促使企业间的计算机协同工作。
真是不好理解的一段话啊。可是如果把 .NET 的核心技术对照着计算机三大原则再介绍一遍的话,就会像下面这样进行说明。
【有关 .NET 的说明之二】
计算机是执行程序的机器。程序是指令和数据的集合。为了使互联网上相互连接的计算机能通过程序协同工作,微软公司采用了 SOAP 以及 XML 规范。SOAP 是关于调用指令的规范,XML 则是定义数据格式的规范。
只要定义出了指令和数据的规范,装有符合规范的程序的计算机自然就可以相互协作了。所谓计算机的协同工作指的是,输入到一台计算机中的数据,可以通过互联网传送到与这台计算机相连的其他计算机上执行运算,运算所输出的结果再返回给这台计算机。像这样部署在其他计算机上能执行某种运算的程序就叫作 XML Web 服务。
这回怎么样?应该变得容易理解了吧?如果又想到了其他的问题,比如“为什么不得不遵循 SOAP 和 XML 的规范呢?”或者“实际看了看 SOAP 和 XML 的规范,才发现也很复杂。”那么就可以把答案归结为“因为那些都是适合计算机的处理方式”。
1.6 为了贴近人类,计算机在不断地进化
围绕着计算机的技术正在以狂奔般的速度不断进化,与其说是日新月异,倒不如说是“秒新分异”。虽然也许有人会觉得眼前的已经够用了,希望能停留在现有的技术水平上。但是计算机的进化是不会停止的,因为计算机还远远没有到达完善的地步。
计算机进化的目的只有一个——与人类更加相近。要想贴近人类,就必须从计算机的处理方式中摒弃不符合人们思维习惯的部分。请对照着计算机三大原则之一的“计算机有自己的处理方式”来记忆这个结论。
举例来说,键盘这种不好用的输入设备进化成了好用的鼠标。平面的 2D(二维)游戏进化成了立体的 3D(三维)游戏。无论是哪一种进化,都是为了使计算机的处理方式更加贴近人类。
这样发展下去的话,也许计算机进化的最终形态就是机器人了,有着与人类一样的外表,可以使用人类的语言。例如在 1985 年茨城县筑波市举办的筑波世博会上,就展示出了一台用 CCD 照相机识别乐谱,弹奏钢琴的机器人。也许有人会觉得:“数码音乐什么的用个人计算机不是也能完成吗?”但是这个发明的意义在于机器人能和人类做相同的事了。就在不久前,本田公司开发出的两足步行机器人也成为了热议的话题。也许又有人会觉得:“为什么非要特地用两只脚行走呢,装上轮子能动起来不也一样吗?”但是这个发明的意义还是在于机器人能和人类做相同的事了。有乐谱和钢琴就能演奏,人能走的道路或台阶它也能走,这样的机器人无疑才能更加方便地应用于人类社会。
若与十几年前相比,诸位身边的个人计算机也在逐渐贴近人类。20 世纪 80 年代中期盛行的个人计算机操作系统是 MS-DOS, 其操作方法是靠在全黑的画面上敲入字符,把命令传给计算机。进入 90 年代后,MS-DOS 进化成了 Windows, 用户可以在图形界面上通过鼠标的操作直观地下达命令(如图 1.3 所示)。
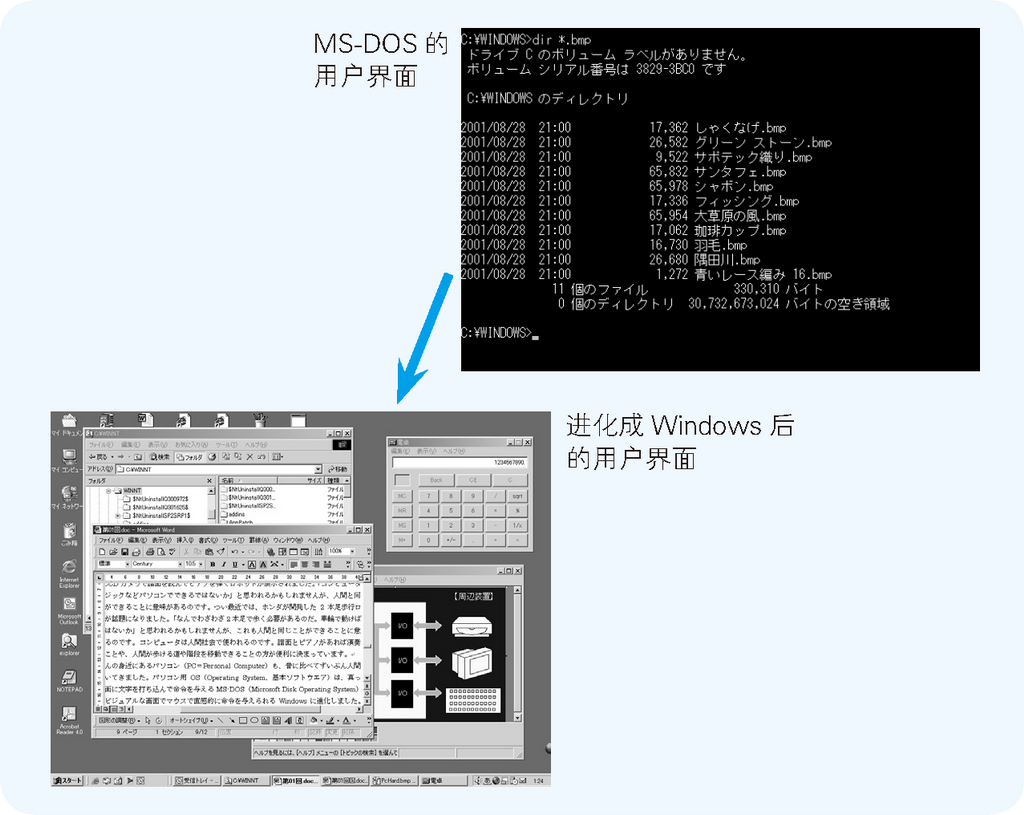
图 1.3 为了贴近人类,个人计算机操作系统也在进化
开发出 Windows 的美国微软公司, 正将目标锁定在用户体验(User Experience)上,旨在开发出超过现有 Windows、更加贴近人类的用户界面(计算机的操作方法)。 Windows XP 和 Office XP 末尾的 XP,代表的就是 Experience(体验)。Windows 若能这样不断进化下去, 早晚会有一天,面向个人计算机的语音输入和手写输入等技术将变得极为普及。
诸位读者当中应该也有对编程感兴趣的人吧。编程方法也在进化,进化的成果是诞生了两种编程方法,面向组件编程(Component Based Programming)和面向对象编程(Object Oriented Programming)。这两者的进化目标一致,都是使程序员可以在编程中继续沿用人类创造事物时的方法。面向组件编程的方法是通过将组件(程序的零件)组装到一起完成程序;面向对象编程的方法是先如实地对现实世界的业务建模,之后再把模型搬到程序中。使用符合人类思维习惯的编程方法,可以实现高效率的开发。
但是,偏偏有这类程序员,他们对面向组件编程敬而远之,明明有各种各样现成的组件可供使用,却什么功能都要自己亲手做,仿佛不这样编程就不舒心。还有的程序员误认为面向对象编程难以理解。像这样的程序员人数还不少,特别是在昔日的计算机发烧友当中。总之就是因为他们太习惯于配合计算机的处理方式了,反倒认为计算机贴近人类这一发展趋势是在添乱。
笔者则认为,无论是刚入行的技术人员,还是有资历的老工程师,都应该由衷地欢迎技术的进化,坦率地接受新技术。如果是用祖传技艺制作出来的传统手工艺品的话,也许还有价值,但是没有人会稀罕靠一成不变的方法编写出的程序。
1.7 稍微预习一下第 2 章
作为第 2 章的预习,在本章的最后先来简单地介绍一下计算机(特别是个人计算机)硬件的组成要素。 这里讲得不会很难,请先看一下图 1.4,体会一下图中的要点。
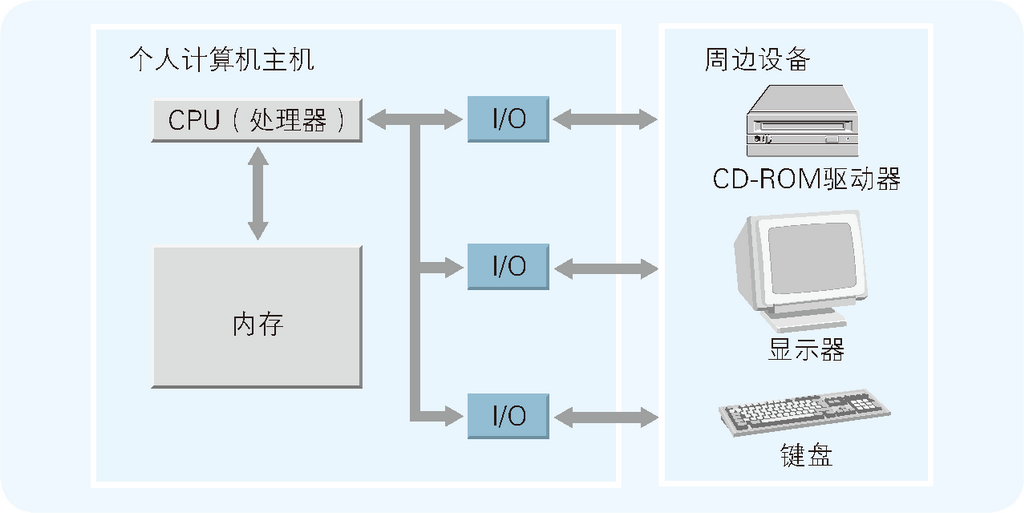
图 1.4 计算机硬件的组成要素
如图所示,计算机内部主要由被称作 IC 的元件组成。虽然在 IC 家族当中有功能各异的各种 IC, 但是在这里希望诸位记住的只有三种:CPU(处理器)、内存以及 I/O。
CPU 是计算机的大脑,在其内部可对数据执行运算并控制内存和 I/O。内存用于存储指令和数据。I/O 负责把键盘、鼠标、显示器等周边设备和主机连接在一起,实现数据的输入与输出。
在诸位所使用的 Windows 个人计算机中,多数都只装有一枚名为 Pentium(奔腾)的 CPU 吧。内存的数量则会根据所需存储的大小(少则 32MB,多则 256MB)装有多条。I/O 也会根据周边设备的多少装配有多个。可以认为个人计算机背板上有多少个插孔就有多少个 I/O。
只要用电路把 CPU、内存以及 I/O 上的引脚相互连接起来,为每块 IC 提供电源,再为 CPU 提供时钟信号, 硬件上的计算机就组装起来了,还是非常简单的吧。所谓时钟信号, 就是由内含晶振(一种利用石英晶体(又称水晶)的压电效应产生高精度振荡频率的电子元件)的、被称作时钟发生器的元件发出的滴答滴答的电信号。 如果是 Pentium CPU 的话,所使用的时钟信号会从几百 MHz 到 2GHz 不等。
☆ ☆ ☆
诸位辛苦了,至此第 1 章就结束了。想必诸位都已经理解了计算机的三大原则以及计算机为什么要进化了吧。因为这些知识真的非常重要,所以如果第一遍没有读懂,就请再反复多读几遍。也可以叫上公司的同事、学校的同学一起讨论本章的内容。如果能让有资历的老工程师也加入讨论,那么效果会更加显著。
在接下来的第 2 章中,我们将尝试着动手“制造”一台计算机。说是制造,也只不过是在纸上进行的“模拟体验”,而且笔者会带着诸位做,所以请不要担心。敬请期待!
第 2 章 试着制造一台计算机吧
- 问题
初级问题:CPU 是什么的缩写?
中级问题:Hz 是表示什么的单位?
高级问题:Z80 CPU 是多少比特的 CPU ?
- 答案
初级问题:CPU 是 Central Processing Unit(中央处理器)的缩写。
中级问题:Hz(赫兹)是频率的单位。
高级问题:Z80 CPU 是 8 比特的 CPU。
- 解释
初级问题:CPU 是计算机的大脑,负责解释、执行程序的内容。有时也将 CPU 称作“处理器”。
中级问题:通常用 Hz 来表示驱动 CPU 运转的时钟信号的频率。1 秒发出 1 次时钟信号就是 1Hz,所以 100MHz(兆赫兹)的话就是 100×100 万 = 1 亿次/秒。M(兆)代表 100 万。
高级问题:CPU 上数据总线的条数,或者 CPU 内部参与运算的寄存器的容量,都可以作为衡量 CPU 性能的比特数。在 Z80 CPU 中,无论是数据总线的条数还是寄存器的容量都是 8 比特,所以 Z80 CPU 是一款 8 比特的 CPU。而在 Windows 个人计算机中广泛使用的 Pentium(奔腾)CPU 则是 32 比特的 CPU。
- 本章重点
要想彻底掌握计算机的工作原理,最好的方法就是自己搜集零件,试着组装一台微型计算机。 微型计算机(MicroCom)是 Micro Computer 的缩写,字面含义是微小的计算机, 但一般也可用于指代 IC 元件外露的、用于控制的计算机。因为要制作一台真正的微型计算机既花时间又花金钱, 所以本章就在纸上体验一下微型计算机的制作过程吧。需要让诸位准备的只有如图 2.1 所示的电路图和一根红铅笔。 将电路图复印下来后,请诸位一边想象着元件之间传输的信号的作用,一边用红铅笔描画出笔者所介绍的电路, 以此来代替实际的布线环节。当所有的电路都描红了,微型计算机也就完成了。
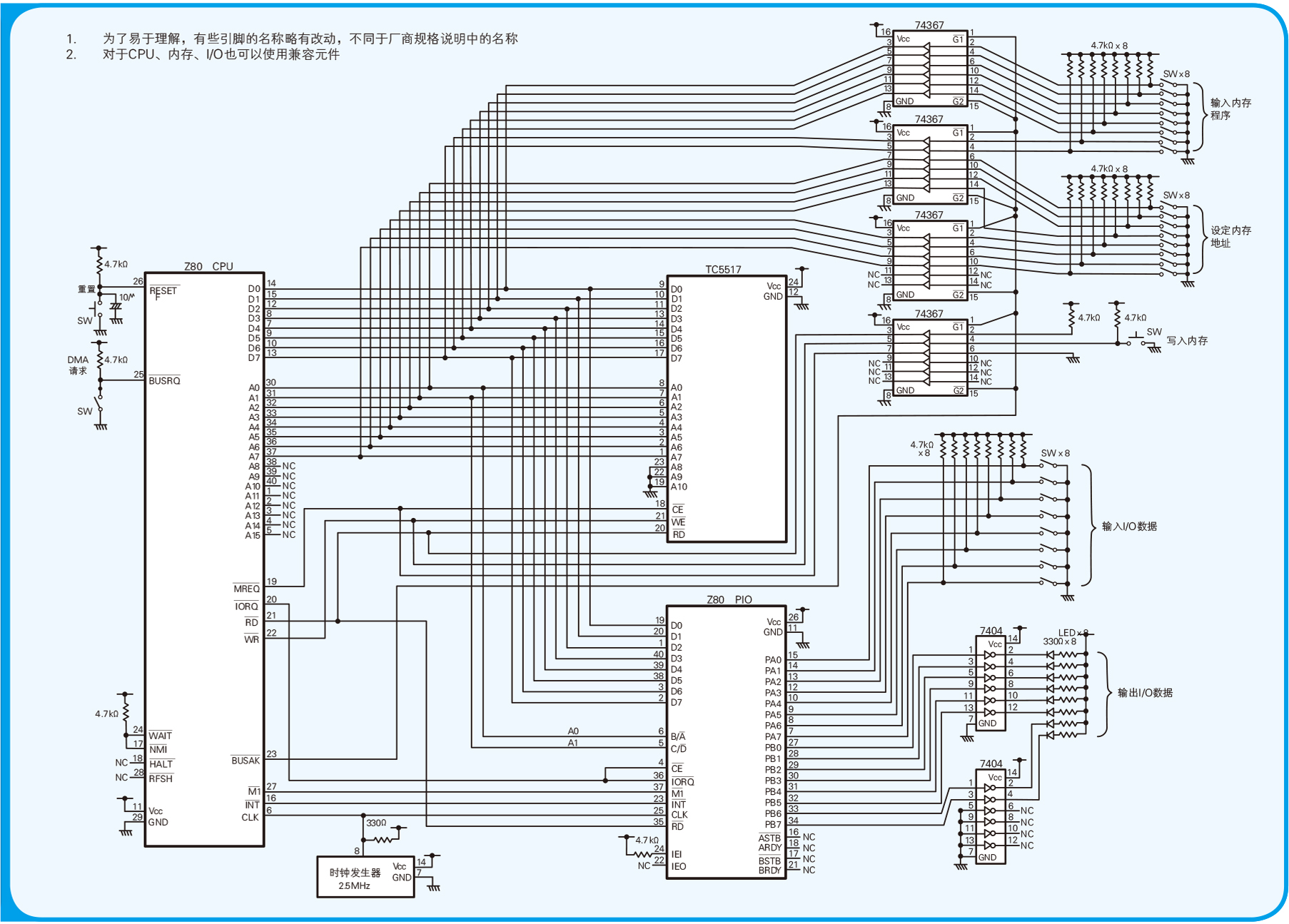
图 2.1 Z80 微型计算机的电路图
别看只是描了描线,却一样能学到很多知识,甚至可以说不费吹灰之力就能了解计算机的工作原理。从此之后不但消除了对硬件的恐惧感,而且还会感到和计算机更加亲近了。请诸位一定要借此机会体验微型计算机的制作过程。
2.1 制作微型计算机所必需的元件
首先让我们来收集元件吧。制作微型计算机所需的基础元件只有 3 个,CPU、内存和 I/O,每种元件都是作为一块独立的 IC 在市场上出售的。CPU 是计算机的大脑,负责解释、执行程序。内存负责存储程序和数据。I/O 是 Input/Output(输入/输出)的缩写,负责将计算机和外部设备(周边设备)连接在一起。
这里我们使用 Z80 CPU 作为微型计算机的 CPU、TC5517 作为内存、Z80 PIO 作为 I/O。Z80 CPU 是一款古老的 CPU, 在 NEC 的 PC-8801、SHARP 的 MZ-80 等 8 比特计算机广泛应用的时代,曾以爆炸般的速度普及过。 TC5517 是可以存储 2K 的 8 比特数据的内存。在计算机的世界里,K 表示 2^10 = 1024。 TC5517 的容量是 8 比特 ×2×1024 = 16384 比特,即 2K 字节。虽然这点容量与诸位所使用的个人计算机比起来相差悬殊, 但是对于用于学习的微型计算机来说是绰绰有余了。Z80 PIO 作为 I/O,经常与 Z80 CPU 一起使用。 正如其名,PIO(Parallel I/O,并行输入/输出)可以在微型计算机和外部设备之间并行地(一排一排地)输入输出 8 比特的数据。 在计算机爱好者们沉浸在制作微型计算机的那个年代,这些元件都是常见的 IC。这里要先跟诸位打声招呼, 这里制作的微型计算机终归只是用于学习的模型,并没有什么实用的价值。
为了制作微型计算机,除了 CPU、内存和 I/O,还需要若干辅助元件。
为了驱动 CPU 运转,称为“时钟信号”的电信号必不可少。这种电信号就好像带有一个时钟,滴答滴答地每隔一定时间就变换一次电压的高低(如图 2.2 所示)。输出时钟信号的元件叫作“时钟发生器”。时钟发生器中带有晶振,根据其自身的频率(振动的次数)产生时钟信号。时钟信号的频率可以衡量 CPU 的运转速度。这里使用的是 2.5MHz(兆赫兹)的时钟发生器。
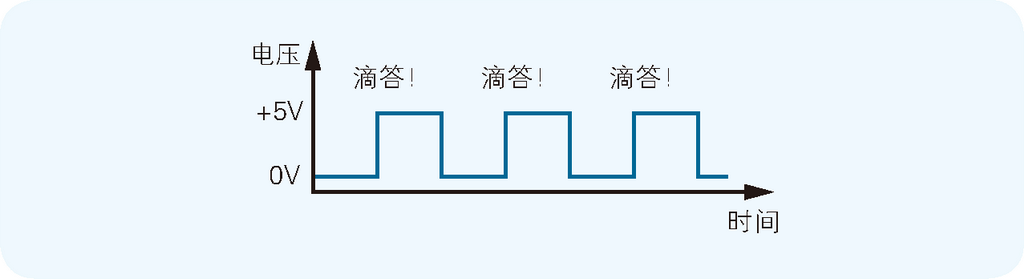
图 2.2 时钟信号的波形图
用于输入程序的装置也是必不可少的。在这里我们通过拨动指拨开关来输入程序,指拨开关是一种由 8 个开关并排连在一起构成的元件(如照片 2.1(a) 所示)。输出程序执行结果的装置是 8 个 LED(发光二极管)。到此为止,主要的元件就都备齐了。
剩下的就都是些细碎的元件了。表 2.1 是所需元件的一览表,里面也包含了之前介绍过的元件。请诸位粗略地浏览一遍。所需元件表中的 74367 和 7404 也是 IC,用于提高连接外部设备时的稳定性。
表 2.1 本次用到的制作微型计算机的元件
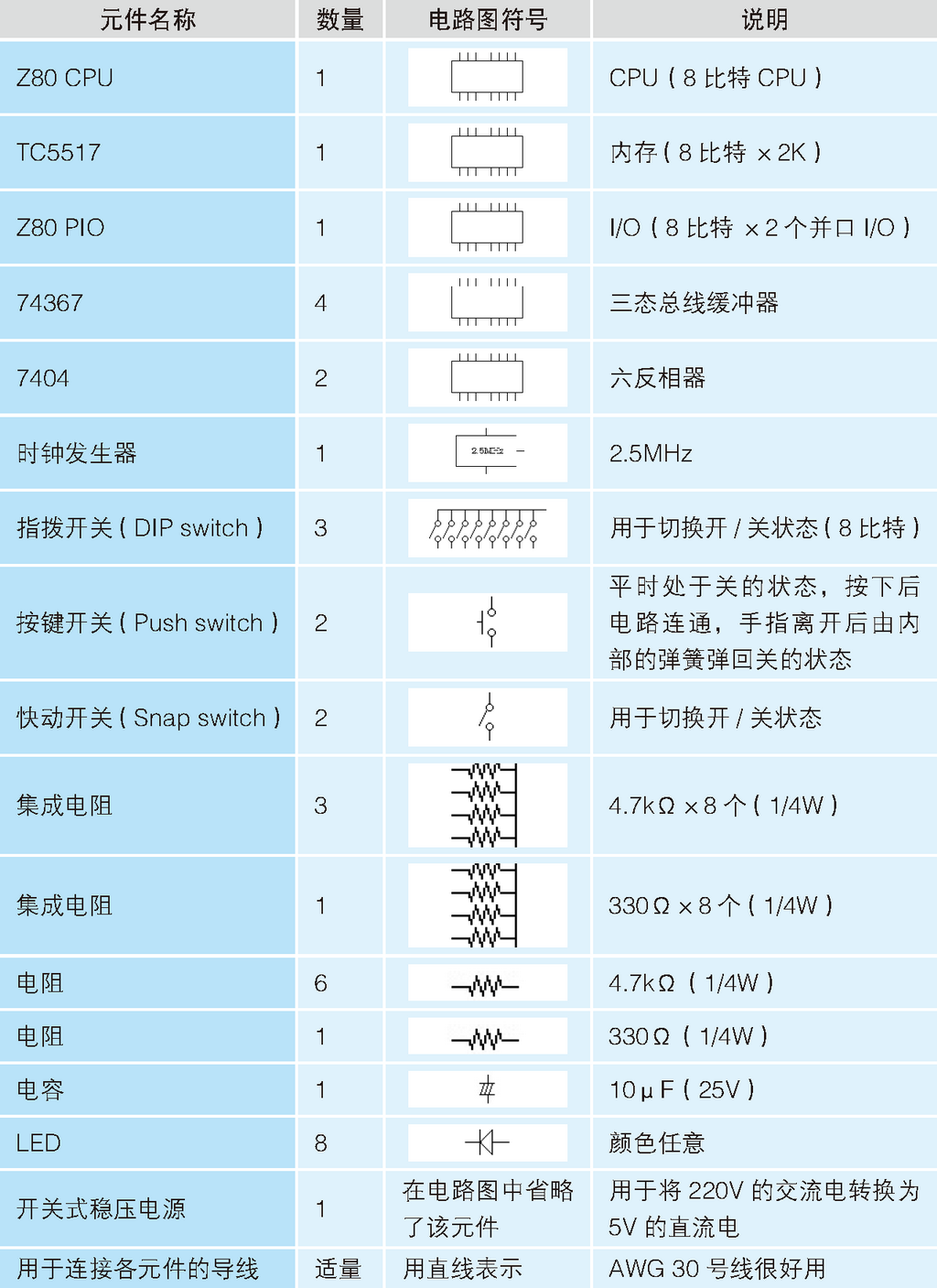
电阻是用于阻碍电流流动、降低电压值的元件。为了省去布线的麻烦,这里也会使用将 8 个电阻集成到 1 个元件中的集成电阻(如照片 2.1(b) 所示)。电阻的单位是 Ω(欧姆)。电容是存储电荷的元件,衡量存储电荷能力的单位是 F(法拉)。要让微型计算机运转起来,5V(伏特)的直流电源是必不可少的。于是还需要使用一个叫作“开关式稳压电源”的装置,将 220V 的交流电变成 5V 的直流电。

照片 2.1 指拨开关和集成电阻
2.2 电路图的读法
在开始布线之前,先来介绍一下电路图的读法。在电路图中,用连接着各种元件符号的直线表示如何布线。电路中有些地方有交叉,但若只是交叉在一起的话,并不表示电路在交叉处构成通路。只有在交叉处再画上一个小黑点才表示构成通路。
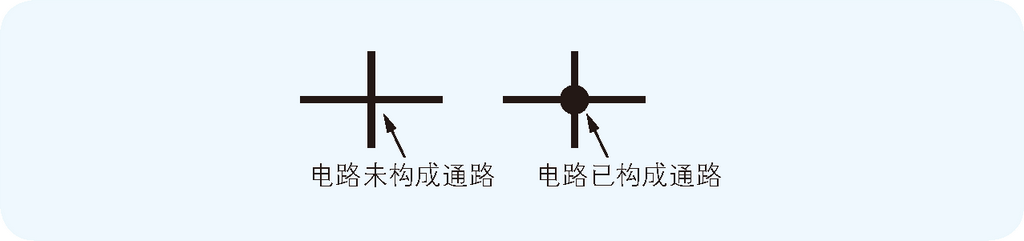
图 2.3 判断电路交叉时是否构成通路
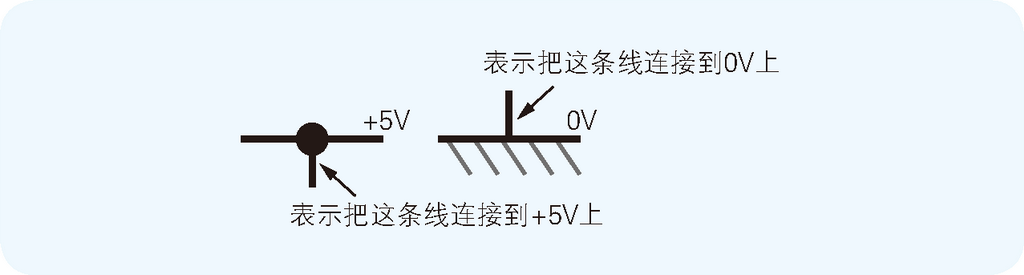
图 2.4 电源的表示方法
本次制作的微型计算机工作在 +5V 的直流电下。虽然在实际的电路中要把 +5V 和 0V 连接到各个元件的各个引脚上,但是如果在电路图中也把这些地方都一一标示出来的话,就会因为到处都是 +5V 和 0V 的布线而显得混乱不堪了。所以要使用如图 2.4 所示的两种电路图符号来分别表示电路连接到 +5V 和连接到 0V 的情况。
IC 的引脚(所谓引脚就是 IC 边缘露出的像蜈蚣腿一样的部分)按照逆时针方向依次带有一个从 1 开始递增的序号。数引脚序号时,要先把表示正方向的标志,比如半圆形的缺口,朝向左侧。举例来说,带有 14 个引脚的 7404,其引脚序号就如图 2.5 所示。
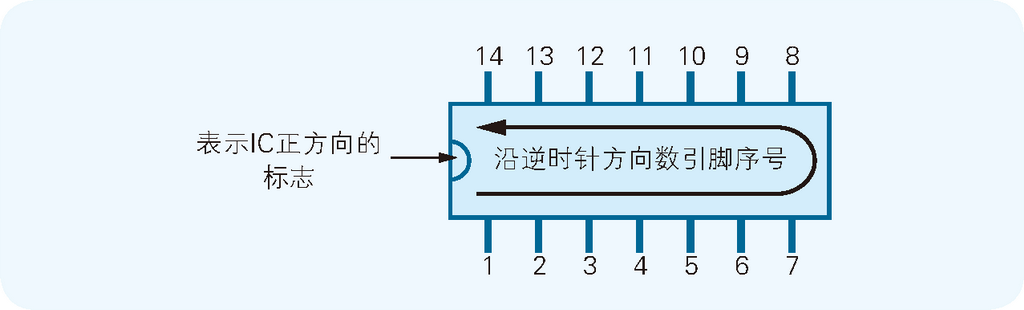
图 2.5 如何数 IC 的引脚序号
如果按照引脚序号的排列顺序来画 IC 的电路图符号,那么标示如何布线时就会很不方便。 所以通常所绘制的电路图都不受引脚实际排布的限制(有时也会遵循引脚序号的顺序绘制电路图,这样的电路图叫作实物布线图)。 画图时,在引脚的旁边写上引脚的序号,在表示 IC 的矩形符号中写上表明该引脚作用的代号。 代号就是像 RD(Read)表示执行读取操作,WR(Write)表示执行写入操作这样的代表了某种操作的符号。 各个代号的含义等到为引脚布线时再一一说明(写在引脚旁边的代号,其含义会写在 IC 生产厂商发布的资料中, 但在这里为了保持文章的通俗易懂,改变了一部分代号的写法,这一点还望诸位谅解。 例如,在厂商的资料中 TC5517 的第 20 个引脚的代号是 OE(Output Enable,输出使能),在这里则改为了含义相同的 RD(Read,读取))。
2.3 连接电源、数据和地址总线
下面就开始布线吧。请假想自己正在制作微型计算机,并按照如下的说明用红铅笔在电路图中描画相应的电路。
首先连接电源。IC 与普通的电器一样,只有接通了电源才能工作。Z80 CPU、TC5517 和 Z80 PIO 上都分别带有 Vcc 引脚和 GND 引脚。Vcc 和 GND 这一对儿引脚用于为 IC 供电。下面请先将 +5V 电源连接到各个 IC 的 Vcc 引脚上,然后将 0V 电源连接到各个 IC 的 GND 引脚上。接下来还需要将 +5V 和 0V 连接到时钟发生器上。接通电源后这些 IC 和时钟发生器就可以工作了。
微型计算机所使用的 IC 属于数字 IC。在数字 IC 中,每个引脚上的电压要么是 0V、要么是 +5V,通过这两个电压与其他的 IC 进行电信号的收发。用于给 IC 供电的 Vcc 引脚和 GND 引脚上的电压是恒定不变的 +5V 和 0V,但是其他引脚上的电压,会随着计算机的操作在 +5V 和 0V 之间不断地变化。
稍微说一点题外话,只要想成 0V 表示数字 0、+5V 表示数字 1,那么数字 IC 就是在用二进制数的形式收发信息。也正因为如此,二进制数在计算机当中才如此重要。有关二进制的内容,本书并不会详细介绍,但是请先记住以下知识点:通常将 1 个二进制数(也就是数字 IC 上 1 个引脚所能表示的 0 或者 1)所表示的信息称作“1 比特”,将 8 个二进制数(也就是 8 比特)称作“1 字节”。比特是信息的最小单位,字节是信息的基本单位。这里制作的微型计算机是一台 8 比特微型计算机,因此是以 8 比特为一个单位收发信息的。
下面回到正题。计算机以 CPU 为中心运转。CPU 可以与内存或 I/O 进行数据的输入输出。为了指定输入输出数据时的源头或目的地,CPU 上备有“地址总线引脚”。Z80 CPU 的地址总线引脚共有 16 个,用代号 A0~A15 表示,其中的 A 表示 Address(地址)。后面的数字 0~15 表示一个 16 位的二进制数中各个数字的位置,0 对应最后一位、15 对应第一位。16 个地址总线引脚所能指定的地址共有 65536 个,用二进制数表示的话就是 0000000000000000~1111111111111111。因此 Z80 CPU 可以指定 65536 个数据存取单元(内存存储单元或 I/O 地址),进行信息的输入输出。
一旦指定了存取数据的地址,就可以使用数据总线引脚进行数据的输入输出了。Z80 CPU 的数据总线引脚共有 8 个,用代号 D0~D7 表示。其中的 D 表示 Data(数据),后面的数字 0~7 与地址总线引脚代号的规则相同,也表示二进制数中各个数字的位置。Z80 CPU 可以一次性地输入输出 8 比特的数据,这就意味着如果想要输入输出位数(比特数)大于 8 比特的数据,就要以 8 比特为单位切分这个数据。
作为内存的 TC5517 上也有地址总线引脚(A0~A10)和数据总线引脚(D0~D7)。这些引脚需要同 Z80 CPU 上带有相同代号的引脚相连。一块 TC5517 上可以存储 2048 个 8 比特的数据(如图 2.6 所示)。可是由于用于输入程序的指拨开关是以 8 比特为一个单位指定内存地址的,所以我们只使用 TC5517 上的 A0~A7 这 8 个引脚,并把剩余的 A8~A10 引脚连接到 0V 上(这些引脚上的值永远是 0)。虽然总共有 2048 个存储单元,最终却只能使用其中的 256 个,稍微有些浪费。下面就请诸位用红铅笔把 Z80 CPU 和 TC5517 的 D0~D7 以 及 A0~A7 引脚分别连接起来。
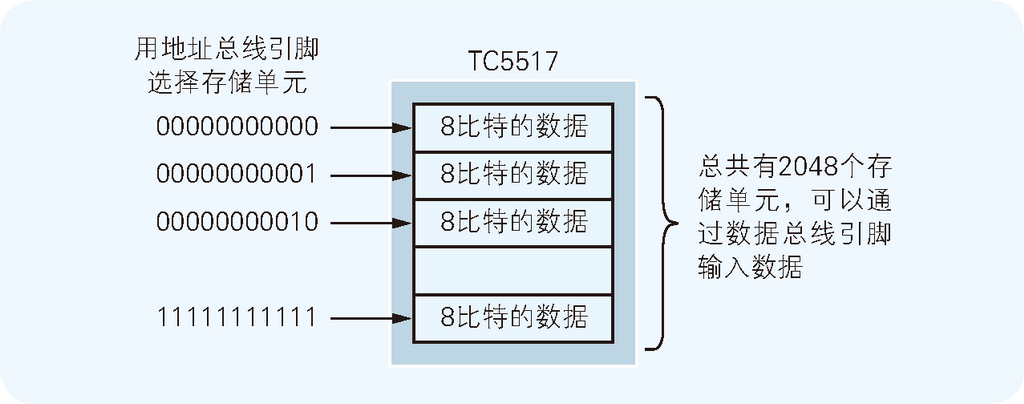
图 2.6 TC5517 的内部构造
2.4 连接 I/O
下面开始连接 I/O。只有了解了作为 I/O 的 Z80 PIO 的结构,才能理解为什么要这样布线。诸位都知道“寄存器”这个词吗?寄存器是位于 CPU 和 I/O 中的数据存储器。Z80 PIO 上共有 4 个寄存器。2 个用于设定 PIO 本身的功能,2 个用于存储与外部设备进行输入输出的数据。
这 4 个寄存器分别叫作端口 A 控制、端口 A 数据、端口 B 控制和端口 B 数据。所谓端口就是 I/O 与外部设备之间输入输出数据的场所,可以把端口(Port)想象成是轮船装卸货物的港口。Z80 PIO 有 2 个端口,端口 A 和端口 B,最多可以连接 2 个用于输入输出 8 比特数据的外部设备(如图 2.7 所示)。
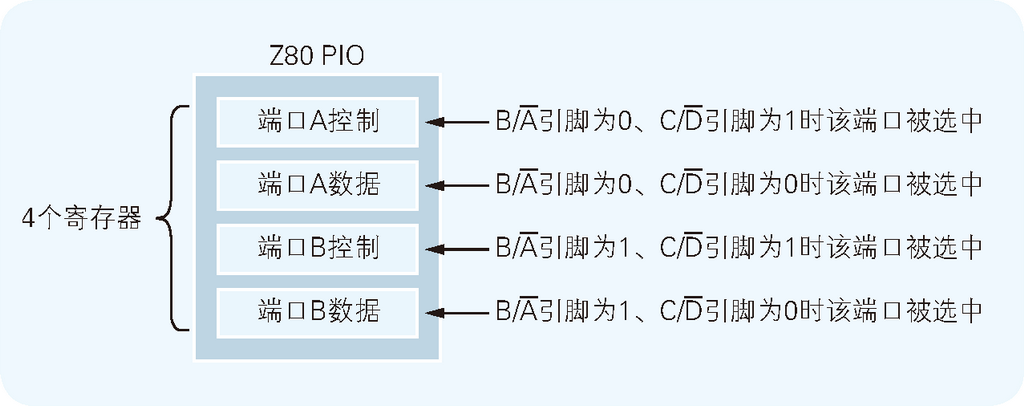
图 2.7 Z80 PIO 的内部构造
既然已经大体上了解了 Z80 PIO 的结构,下面就开始布线吧。因为 Z80 PIO 上也有 D0~D7 的数据总线引脚,所以先把它们和 Z80 CPU 中带有同样代号的引脚连接起来。这样 CPU 和 PIO 就能使用这 8 个引脚交换数据了。
接下来要把 Z80 PIO 的 B/A和 C/D引脚 分别连接到 Z80 CPU 的地址总线引脚 A0 和 A1 上。 若表示 IC 引脚作用的代号上划有横线,则表示通过赋予该引脚 0(0V)可使之有效,反之若没有横线, 则表示通过赋予该引脚 1(+5V)可使之有效。因此若赋予 B/A引脚 1 则表示选中 B,反之赋予 0 则表示选中 A。 同样地,若赋予 C/D引脚 1 则表示选中的是 C(C 即 Control,表示控制模式);反之赋予 0 则表示选中的是 D(D 即 Data,表示数据模式)。
通过 Z80 CPU 的 A0~A7(00000000~11111111 共 256 个地址)地址总线引脚可以选择内存(TC5517)中的存储单元。 同样地,使用 Z80 CPU 的 A0~A1(00~11 共 4 个地址)地址总线引脚也可以选择 I/O(Z80 PIO)中的寄存器。
Z80 CPU 的 A8~A15 地址总线引脚尚未使用,所以什么都不连接。 在电路图中可以用代号 NC(No Connection,未连接)表示引脚什么都不连接。 IC 上的引脚有些只用于输出,有些只用于输入,还有些是输入输出两用的。对于只用于输出的引脚,不需要使用时的处理方法是这个引脚什么都不连接;而对于只用于输入或输入输出两用的引脚,不需要使用时的处理方法则是把这个引脚上的电压固定成是 +5V 或 0V。
2.5 连接时钟信号
正如前文所述,Z80 CPU 和 Z80 PIO 的运转离不开时钟信号。为了传输时钟信号,就需要把时钟发生器的 8 号引脚和 Z80 CPU 的 CLK(CLK 即 Clock,时钟)引脚、Z80 PIO 的 CLK 引脚分别连接起来。时钟发生器的 8 号引脚与 +5V 之间的电阻用于清理时钟信号。
再插入一段题外话。诸位可以把 Z80 CPU 和 Z80 PIO 在时钟信号下运转的情景,想象成是它们在跟随着滴答滴答响的时钟同步做动作。据说 19 世纪英国的查尔斯·巴贝奇(Charles Babbage)曾向制造计算机的原型——分析机发起过挑战。分析机由齿轮组成,因当时科技水平的限制并未制造完成。可是如果把分析机改用电子元件制造出来的话,就是今天的计算机。
2.6 连接用于区分读写对象是内存还是 I/O 的引脚
至此,我们已经先后把 Z80 CPU 连接到了 TC5517 和 Z80 PIO 上,这两次连接都使用了地址总线引脚 A0 和 A1。如果仅仅这样连接,就会导致一个问题,当地址的最后两位是 00、01、10 和 11 时,CPU 就无法区分访问的是 TC5517 中的存储单元,还是 Z80 PIO 中的寄存器了。
Z80 CPU 上的 MREQ(即 Memory Request,内存请求)引脚和 IORQ(即 I/O Request,I/O 请求)引脚解决了这个问题。 当 Z80 CPU 和内存之间有数据输入输出时, MREQ引脚上的值是 0,反之则是 1。 当 Z80 CPU 和 I/O 之间有数据输入输出时, IORQ引脚上的值是 0,反之则是 1。
若把 TC5517 的 (即 Chip Enable,选通芯片)CE引脚设成 0,则 TC5517 在电路中被激活, 若设成 1 则从电路中隔离,因为此时 TC5517 进入了高阻抗状态,所以即便它上面的引脚已经接入了电路也不会接收任何电信号。 在 Z80 PIO 中,则是通过将 CE引脚和 IORQ引脚同时设为 0 或 1,来达到与 TC5517 的 CE引脚相同的效果。 若同时设为 0,则 Z80 PIO 在电路中被激活,若同时设为 1 则从电路中隔离(之所以使用两个引脚是因为这样更适合使用了多个 I/O 的情况)。
按照上面的讲解,下面需要把 Z80 CPU 的 MREQ引脚连接到 TC5517 的 CE引脚上。 然后把 Z80 CPU 的 IORQ引脚连接到 Z80 PIO 的 CE引脚和 IORQ引脚上。请诸位先用红铅笔把这些引脚分别连接起来吧。
对内存和 I/O 而言,还必须要分清 CPU 是要输入数据还是输出数据。 为此就要用到 Z80 CPU 的 RD引脚(即 Read,表示输入,为 0 时执行输入操作)和 WR引脚(即 Write,表示输出,为 0 时执行输出操作)了。 请把 Z80 CPU 的 RD引脚和 TC 5517 的 RD引脚,Z80 CPU 的 WR引脚和 TC 5517 的 WR引脚分别连接起来。 Z80 PIO 虽然只有 RD引脚,但由于数字 IC 引脚上的值要么是 0 要么是 1,所以只用 1 个 RD引脚也能区分是输入还是输出, 0 的话是输入,1 的话就是输出(如表 2.2 所示)。
表 2.2 与读写内存、I/O 相关的引脚上的值

2.7 连接剩余的控制引脚
CPU、内存、I/O 中不但有地址总线引脚、数据总线引脚,还有其他引脚,通常把这些引脚统称为“控制引脚”。之所以这样命名是因为这些引脚上输入输出的电信号具有控制 IC 的功能。现在 Z80 CPU 上只剩下 9 个控制引脚没有连接了,那么就再加把劲,继续用红铅笔把它们也连接到电路中吧。
首先把 Z80 CPU 的 M1引脚(即 Machine Cycle 1,机器周期 1)和 INT引脚(即 Interrupt,中断)与 Z80 PIO 上标有相同代号的引脚连接起来。 M1 是用于同步的引脚, INT引脚是用于从 Z80 PIO 向 Z80 CPU 发出中断请求的引脚。 所谓中断就是让 CPU 根据外部输入的数据执行特定的程序。有关中断的详细内容将在第 4 章介绍,这里只需要先记住 I/O 可以中断 CPU 正在执行的程序的处理流程就可以了。
一旦把 Z80 CPU 的 RESET引脚(即 Reset,重置)上的值先设成 0 再还原成 1,CPU 就会被重置, 重新从内存 0 号地址上的指令开始顺序往下执行。重置 CPU 可以通过按键开关完成。 按键开关需要经过电阻接在 +5V 和 0V 之间。请仔细地观察这一部分的电路图,可以看出 引脚上平时是 +5V(即 1)。 当按下按键开关时, RESET引脚就变成了 0V(即 0),而放开按键开关后又会回到 +5V(即 1)。 电阻是为了防止短路而加入的,否则一旦按下了按键开关,+5V 和 0V 就会直接接到一起发生短路。 像这样通过加入电阻把 +5V 和 0V 连接起来的方法在电路图中随处可见(如图 2.8 所示)。
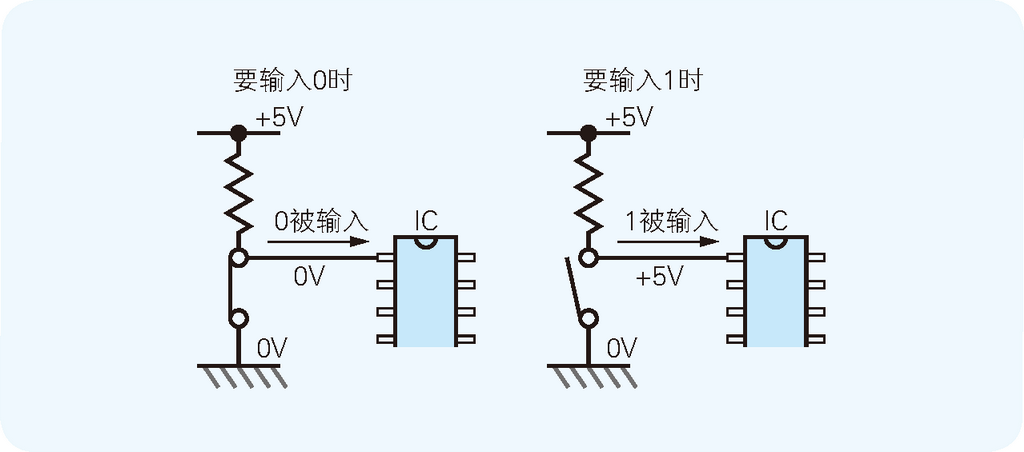
图 2.8 如何用开关输入 0 或 1
连接在 RESET引脚上的电容,用于在电路接通电源时自动重置 CPU。电容就好像一个充电电池,具有储存电荷的功能。 在通电后的一刹那,由于电容正在充电,所以 引脚上的电压并不会立刻上升到 +5V。 而完成充电后, RESET引脚的电压会变为 +5V,这样就相当于 RESET引脚上的值从 0 变成了 1,重置了一次 CPU。
总线是连接到 CPU 中数据引脚、地址引脚、控制引脚上的电路的统称。 使用快动开关可以使 Z80 CPU 的 BUSRQ引脚(即 Bus Request,总线请求)上的值在 0 和 1 之间切换。 若将 BUSRQ引脚的值设为 0,则 Z80 CPU 从电路中隔离。当处于这种隔离状态时,就可以不通过 CPU,手动地向内存写入程序了。像这样不经过 CPU 而直接从外部设备读写内存的行为叫作 DMA(Direct Memory Access,直接存储器访问)。在诸位所使用的个人计算机里,硬盘等设备要读写内存时使用的就是 DMA。
当 Z80 CPU 从电路中隔离后, BUSAK引脚(即 Bus Acknowledge,响应总线请求)上的值就会变成 0。 也就是说,把 BUSRQ引脚上的值设成 0 以后,还要确认 BUSAK引脚上的值已经变成了 0,然后才能进行 DMA。 请把 BUSAK引脚分别连接到 4 个 74367 的 G1 和 G2 引脚上。有关 74367 的作用将在后面说明。
Z80 CPU 的其他控制引脚并未使用。所以要把 WAIT引脚和 NMI引脚上的值设为 1,即连接到 +5V 上。 之所以在连接时加入电阻,是为了便于今后加入开关等元件。请诸位先记住一个词——上拉(Pull-up), 指的就是像这样通过加入电阻把元件的引脚和 +5V 连接起来。剩下的 HALT引脚和 RFSH引脚什么都不连接。
Z80 PIO 的 PA0~PA7(PA 表示 Port A)以及 PB0~PB7(PB 表示 Port B)用于与外部设备进行输入输出, 所以稍后要把它们分别连接到指拨开关和 LED 上。对于剩下的几个引脚可以这样处理: 将 IEI 引脚上拉,IEO 引脚、 ASTB引脚、ARDY 引脚、 BSTB引脚和 BRDY 引脚则什么都不连接。
到此为止,Z80 CPU、TC5517、Z80 PIO 以及时钟发生器上要用到的引脚就都接入电路了。 这意味着计算机主机系统的功能完成了。作为总结,表 2.3 汇总了这几块 IC 上引脚的作用以及电信号的输入输出方向(从各个 IC 的角度看)。
表 2.3 Z80 CPU、TC5517、Z80 PIO 的引脚作用以及输入输出方向

用红铅笔尝试布线的诸位觉得怎么样呢?虽然需要连接的电路有点多,但也并不是太复杂吧?其实计算机的工作原理非常简单。CPU 在时钟信号的控制下解释、执行内存中存储的程序,按照程序中的指令从内存或 I/O 中把数据输入到 CPU 中,在 CPU 内部进行运算,再把运算结果输出到内存或 I/O 中。无论是小型的微型计算机,还是高性能的个人计算机,其工作原理都是相同的。
2.8 连接外部设备,通过 DMA 输入程序
下面我们继续布线,这次将计算机主机系统和外部设备连接起来。我们要使用 2 个指拨开关和 1 个按键开关,向地址总线引脚和数据总线引脚发送电信号,然后通过 DMA 将数据总线上的数据存储到内存。下面我们就先将这些元件连接到电路中。
首先将图 2.1 中右侧最上方的一个指拨开关连接到作为内存的 TC5517 的数据总线引脚 D0~D7 上。 再将它下面紧挨着它的指拨开关连接到 TC5517 的地址总线引脚 A0~A7 上。 接下来将用于控制内存写入的按键开关连接到 TC5517 的 WE引脚上。 为了写入数据,还要将 TC5517 的 RD引脚上拉起来,连接到 +5V 上,然后把 CE引脚连接到 0V 上。 把这些元件都连接起来以后,就可以拨动指拨开关,用二进制数设定地址总线引脚和数据总线引脚上的数据了。 设定完后按下按键开关,数据就会被写入 TC5517 中。在 2 个指拨开关下方还有一个指拨开关, 它通过电阻接到 +5V 上,这样拨动这个指拨开关就可以输入 +5V 或 0V 的信号了。
但是如果这些开关直接连接到了 TC5517 的各个引脚上,在程序执行时,开关的状态就会对电路产生影响。 因此要使用 74367,在程序执行时把开关从电路中隔离出来。74367 是一种叫作“三态总线缓冲器”的 IC。 在这个 IC 的电路图符号中,有用三角形标志代表的缓冲器,表示使电信号从右向左直接通过。 但是,只有在 74367 的 G1引脚和 G2引脚同时为 0 的时候,电信号才能通过。 而当 G1引脚和 G2引脚同时 为 1 时,74367 就会与电路隔离。
一旦打开了 Z80 CPU 的 BUSRQ引脚连接着的开关,就可以通过 BUSAK引脚输出 0 得知 CPU 进入了 DMA 状态。 因此只要把 BUSAK 引脚连接到 4 个 74367 的 G1引脚和 G2引脚上,就可以实现通过 DMA 向内存写入数据了。
2.9 连接用于输入输出的外部设备
布线终于快结束了。下面该轮到把最下方用于输入数据的指拨开关和 LED 连接到 Z80 PIO 上了。当微型计算机运行起来后,指拨开关可用于从外部输入数据,LED 可用于向外部输出数据。
用于输入数据的指拨开关,要连接到 Z80 PIO 的 PA0~PA7 引脚上。连接时没有使用 74367 是为了在程序运行中可以通过 Z80 PIO 从指拨开关获得输入的数据。
表示输出数据的 LED 要通过电阻连接到 +5V 上。这里的布线方法依据惯例,输入 0V 点亮 LED(如图 2.9 所示)。LED 要通过 7404 这样的 IC 连接到 Z80 PIO 的 PB0~PB7 引脚上。在 7404 的电路图符号中,末端带有一个小圆圈的三角形符号表示反相器,作用是将左侧输入的电信号反转后(即 0 变 1、1 变 0)输出到右侧。通过这样的设计,当 Z80 PIO 的 PB0~PB7 引脚上的值为 0 时 LED 就会熄灭,为 1 时 LED 就会点亮。
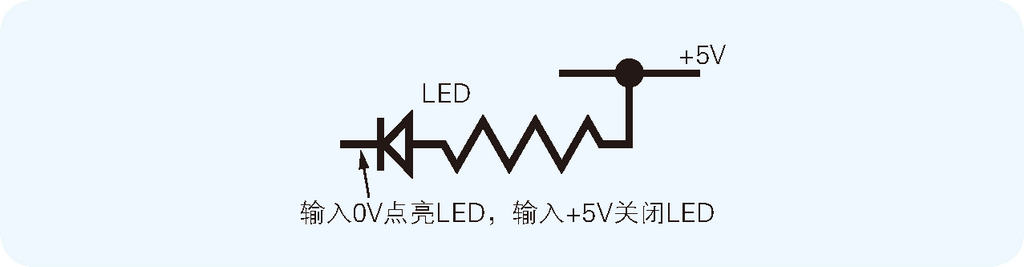
图 2.9 点亮 LED 的方法
是不是觉得忘记了什么呢?没错! 74367 和 7404 上也都有 Vcc 引脚和 GND 引脚。请将它们分别连接到 +5V 和 0V 上。对于 74367 和 7404 中未使用的引脚(标有 NC 的引脚),或者什么都不连接,或者将它们连接到 GND 上。
2.10 输入测试程序并进行调试
微型计算机终于顺利地制作出来了,诸位辛苦了!微型计算机接上电源就能用了吗?其实还不能,因为尽管硬件组装好了,但若没有输入软件,计算机还是不能工作的。所以即使为微型计算机接通了电源,它也什么都执行不了。
下面就编写一段测试程序吧。编写时可以使用哪种编程语言呢?是 BASIC、C 语言,还是 Java 呢?其实这些语言都无法使用,因为作为计算机大脑的 CPU 只能解释执行一种编程语言,那就是靠罗列二进制数构成的机器语言(原生代码)。代码清单 2.1 展示了一段用机器语言编写的测试程序。程序是指令和数据的集合,表示指令或数据的数值是以 8 比特为一个单位存储到内存中的。这段程序只实现了一个简单的功能,那就是通过拨动连接到 Z80 PIO 上的指拨开关控制 LED 的亮或灭。有关机器语言的细节将在接下来的第 3 章中介绍。
代码清单 2.1 用机器语言编写的测试程序
地址 程序
00000000 00111110
00000001 11001111
00000010 11010011
00000011 00000010
00000100 00111110
00000101 11111111
00000110 11010011
00000111 00000010
00001000 00111110
00001001 11001111
00001010 11010011
00001011 00000011
00001100 00111110
00001101 00000000
00001110 11010011
00001111 00000011
00010000 11011011
00010001 00000000
00010010 11010011
00010011 00000001
00010100 11000011
00010101 00010000
00010110 00000000
接通了微型计算机的电源后,请按下 Z80 CPU 上的 DMA 请求开关。在这个状态下,拨动用于输入内存程序和指定内存输入地址的两个指拨开关,把代码清单 2.1 所示的程序一行接一行地输入内存。先来输入第一行代码,拨动用于指定地址的指拨开关,设定出第一行代码所在的内存地址 00000000,然后拨动用于输入程序的指拨开关,设定出程序代码 00111110。再然后按下用于向内存写入程序的按键开关。接下来输入第二行代码,设定出内存地址 00000001,设定出程序代码 11001111,再次按下按键开关。反复进行这三步操作,直至输入完程序代码的最后一行。所有的指令都输入完成后,按下用于重置 CPU 的按键开关,控制 DMA 请求的快动开关就会还原成关闭状态,与此同时程序也就运行起来了。“太棒了,终于成功了!”这真是令人激动的一瞬间 啊(如照片 2.2 所示)。

照片 2.2 运行中的微型计算机
程序一旦运行起来,就可以用用于输入数据的指拨开关控制 LED 的亮与灭。只要拨动指拨开关,LED 的亮灭就会随之改变。LED 并不会只亮一下,而是一直亮着,时刻保持着指拨开关上的状态。
☆ ☆ ☆
如今活跃在计算机行业第一线的工程师们,他们多数都在年轻的时候玩过微型计算机。诸位可以把这本书拿给他们看,他们也许会这样说:现在还有人玩这个?不过不管怎么说,对计算机理解程度的深浅还是和有没有制作过微型计算机有很大关系的。
笔者真的按照图 2.1 所示的电路图制作过微型计算机,收集零件就费了不少劲。而在单片机广泛应用的今天,CPU、I/O、内存都被集成到了一块 IC 上。可话又说回来,即便只是在纸上体验制作微型计算机的过程,也还是非常有益的。诸位在本章制作了微型计算机,想必这一体验定会加深诸位对计算机的理解,使诸位越来越喜欢计算机。
在接下来的第 3 章中,笔者会先用汇编语言为微型计算机编写程序,然后尝试“手工汇编”,即以手工作业的方式将这段程序转换成机器语言(原生代码)。敬请期待!
第 3 章 体验一次手工汇编
- 问题
初级问题:什么是机器语言?
中级问题:通常把标识内存或I/O 中存储单元的数字称作什么?
高级问题:CPU 中的标志寄存器(Flags Register)有什么作用?
- 答案
初级问题: 由二进制数字构成的程序,CPU 可以直接对其解释、执行。
中级问题: 标识内存或I/O 中存储单元的数字叫作“地址”。
高级问题: 用于在运算指令执行后,存储运算结果的某些状态。
- 解释
初级问题: 不仅是汇编语言,用C 语言、Java、BASIC 等编程语言编写的程序,也都需要先转换成机器语言才能被执行。 机器语言有时也叫作“原生代码”(Native Code)。
中级问题: 内存中有多个数据存储单元。计算机用从0 开始的编号标识每个存储单元,这些编号就是地址(Address)。 I/O 中的寄存器也可以用地址来标识。哪个寄存器对应哪个地址,取决于CPU 和I/O 之间的布线方式。
高级问题: Flag 的本意是“旗子”,这里引申为“标志”。一旦执行了算术运算、逻辑运算、比较运算等指令后, 标志寄存器并不会存放运算结果的值,而是会把运算后的某些状态存储起来, 例如运算结果是否为0、是否产生了负数、是否有溢出(Overflow)等。
- 本章重点
本章的目标是通过编写程序使诸位亲身体验计算机的运行机制。为了达到这个目的, 就需要使用一种叫作“汇编语言”的编程语言来编写程序,然后再把编好的程序通过手工作业转换成CPU 可以直接执行的机器语言。
这样的转换工作叫作“手工汇编”(Hand Assemble)。也许会有 人觉得听起来就好像挺麻烦的,事实上也的确如此,但是还是希望所 有和计算机相关的技术人员都能亲身体验一下用汇编语言编程和手工 汇编。
这次体验应该能加深诸位对计算机的理解,使诸位犹如拨云见日, 找到长期困惑着自己的问题的答案,不仅能因“我能看懂程序了”而 获得成就感,更能因发现“计算机原来很简单啊”而信心倍增。虽然 本章的主题稍有些复杂,但是笔者会放慢讲解的步伐,还请诸位努力 跟上。
3.1 从程序员的角度看硬件
为了体验手工汇编,下面我们就为在第2 章制作的微型计算机编写一个程序吧。因为程序的作用是驱动硬件工作,所以在编写程序之 前必须要先了解微型计算机的硬件信息。然而真正需要了解的硬件信 息只有以下7 种(如图3.1 所示),所以没有必要在编程时还总是盯着 详细的电路图看。
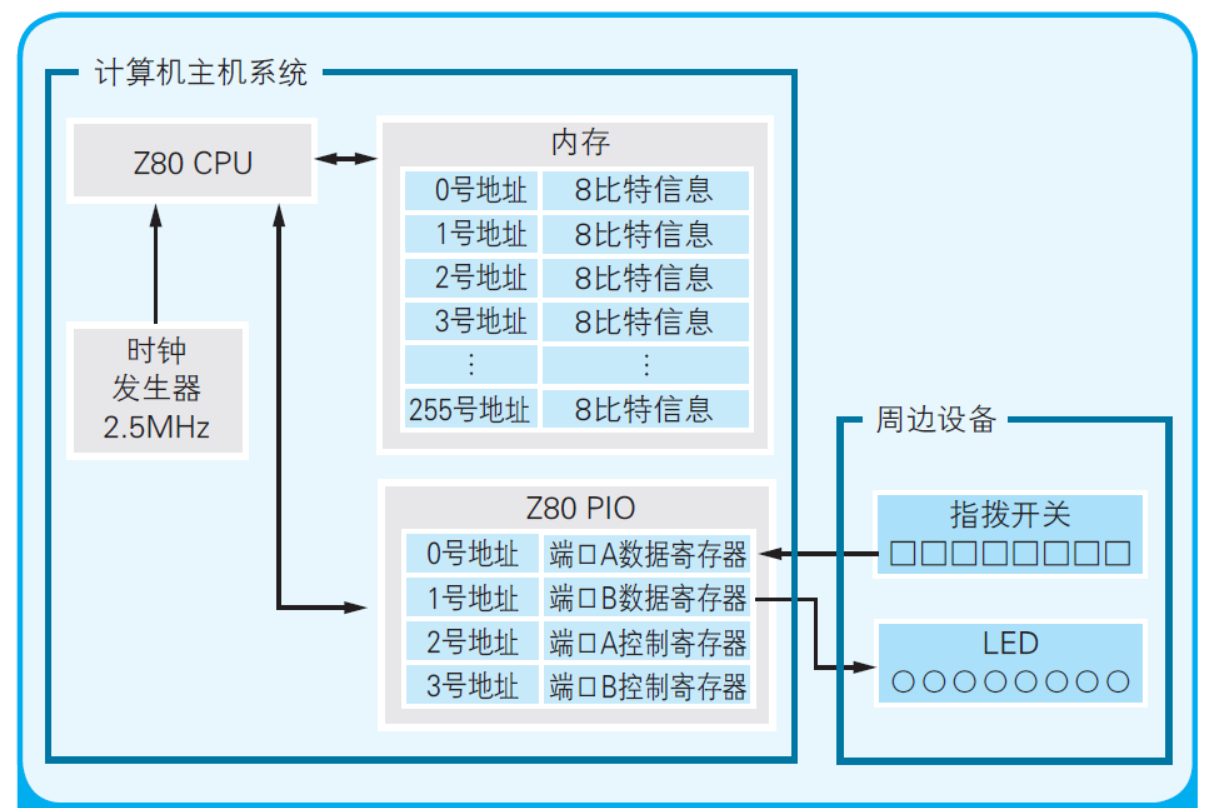
图3.1 编写程序之前需要了解的硬件信息
【CPU(处理器)信息】
- CPU的种类
- 时钟信号的频率
【内存信息】
- 地址空间
- 每个地址中可以存储多少比特的信息
【I/O 信息】
- I/O 的种类
- 地址空间
- 连接着何种周边设备
可以使用哪种机器语言取决于CPU(也称作处理器)的种类。所谓 机器语言就是只用0 和1 两个二进制数书写的编程语言。即便是相同 的机器语言,例如01010011,只要CPU 的种类不同,对它的解释也就 不同。有的CPU 会把它解释成是执行加法运算,有的CPU 会把它解释 成是向I/O 输出。这就好比同样是man 这个词,有的人会理解成“慢”, 有的人会理解成“男人”。
由于微型计算机上的CPU 是Z80 CPU,所以就要使用适用于Z80 CPU 的机器语言。顾名思义,机器语言就是处理器可以直接理解(与 生俱来就能理解)的编程语言。机器语言有时也叫作原生代码(Native Code)。
所谓时钟信号的频率,就是由时钟发生器发送给CPU 的电信号的 频率。表示时钟信号频率的单位是MHz(兆赫兹 = 100 万回/秒)。微 型计算机使用的是2.5MHz 的时钟信号。时钟信号是在0 和1 两个数之 间反复变换的电信号,就像滴答滴答左右摆动的钟摆一样。通常把发 出一次滴答的时间称作一个时钟周期。
在机器语言当中,指令执行时所需要的时钟周期数取决于指令的 类型。程序员不但可以通过累加时钟周期数估算程序执行的时间,还 可以仅在特定的时间执行点亮LED(发光二极管)等操作。
每个地址都标示着一个内存中的数据存储单元,而这些地址所构 成的范围就是内存的地址空间。在我们的微型计算机中,地址空间为 0~255,每一个地址中可以存储8 比特(1 字节)的指令或数据。
连接着的I/O 的种类,就是指连接着微型计算机和周边设备的I/O 的种类。在微型计算机中,只安装了一个I/O,即上面带有4 个8 比特 寄存器的Z80 PIO。只要用CPU 控制I/O 的寄存器,就可以设定I/O 的 功能,与周边设备进行数据的输入输出。
所谓I/O 的地址空间,是指用于指定I/O 寄存器的地址范围。在 Z80 PIO 上,地址空间为0~3,每一个地址对应一个寄存器。
在内存中,每个地址的功能都一样,既可用于存储指令又可用于 存储数据。而I/O 则不同,地址编号不同(即寄存器的类型不同),功 能也就不同。在微型计算机中,是这样分配Z80 PIO 上的寄存器的:端 口A 数据寄存器对应0 号地址,端口B 数据寄存器对应1 号地址,端 口A 控制寄存器对应2 号地址,端口B 控制寄存器对应3 号地址。端 口A 数据寄存器和端口B 数据寄存器存储的是与周边设备进行输入输 出时所需的数据。其中,端口A 连接用于输入数据的指拨开关,端口 B 连接用于输出数据的LED。而端口A 控制寄存器和端口B 控制寄存 器则存储的是用于设定Z80 PIO 功能的参数。
3.2 机器语言和汇编语言
请看代码清单3.1 中列出的机器语言程序,这段程序在第2 章中已 经介绍过了,功能是把由指拨开关输入的数据输入CPU,然后CPU 再 把这些数据原封不动地输出到LED。也就是说,可以通过拨动指拨开 关控制LED 的亮或灭。
代码清单3.1 点亮LED 的机器语言程序
地址 机器语言
00000000 00111110
00000001 11001111
00000010 11010011
00000011 00000010
00000100 00111110
00000101 11111111
00000110 11010011
00000111 00000010
00001000 00111110
00001001 11001111
00001010 11010011
00001011 00000011
00001100 00111110
00001101 00000000
00001110 11010011
00001111 00000011
00010000 11011011
00010001 00000000
00010010 11010011
00010011 00000001
00010100 11000011
00010101 00010000
00010110 00000000
这段由8 比特二进制数构成的机器语言程序总共23 个字节。若把 这些字节一个接一个地依次写入内存中,所占据的内存空间就是 00000000~00010110。一旦重置了CPU,CPU 就会从0 号地址开始顺 序执行这段程序。
在机器语言程序中,虽然到处都是0 和1 的组合,但是每个组合 都是有特定含义的指令或数据。可是对人来说,如果只看0 和1 的话, 恐怕很难判断各个组合都表示什么。
于是就有人发明出了一种编程方法,根据表示指令功能的英语单 词起一个相似的昵称,并将这个昵称赋予给0 和1 的组合。这种类似 英语单词的昵称叫作“助记符”,使用助记符的编程语言叫作“汇编语 言”。无论是使用机器语言还是汇编语言,所实现的功能都是一样的, 区别只在于程序是用数字表示,还是用助记符表示。也就是说,如果 理解了汇编语言,也就理解了机器语言,更进一步也就理解了计算机 的原始的工作方式。
代码清单3.1 中的机器语言可以转换成如代码清单3.2 所示的汇编 语言。汇编语言的语法十分简单,以至于语法只有一个,即把“标 签”“操作码(指令)”和“操作数(指令的对象)”并排写在一行上,仅此而已。
代码清单3.2 用汇编语言的代码表示代码清单3.1 中的机器语言
标签 操作码 操作数
LD A, 207
OUT (2), A
LD A, 255
OUT (2), A
LD A, 207
OUT (3), A
LD A, 0
OUT (3), A
LOOP: IN A, (0)
OUT (1), A
JP LOOP
标签的作用是为该行代码对应的内存地址起一个名字。编程时如 果总要考虑“这一行的内存地址是什么来着?”就会很不方便,所以在 汇编语言中用标签来代替地址。用汇编语言编程时可以在任何需要标 签的地方“贴上”名称任意的标签。在代码清单3.2 所示的程序中,使 用了名称为“LOOP:”的标签。
操作码就是表示“做什么”的指令。因为用助记符表示的指令是 英语单词的缩写,比如LD 是Load(加载)的缩写,所以多多少少能 猜出其中的含义。汇编语言中提供了多少种助记符,CPU 就有多少种 功能。Z80 CPU 的指令全部加起来有70 条左右。这里先把主要的指 令列在表3.1 中,请诸位粗略地浏览一下。在浏览的过程中请注意这 些指令的分类,按功能这些指令可以分成运算、与内存的输入输出和 与I/O 的输入输出三类。这是因为计算机能做的事也只有输入、运 算、输出这三种了。
表3.1 Z80 CPU 中的主要指令
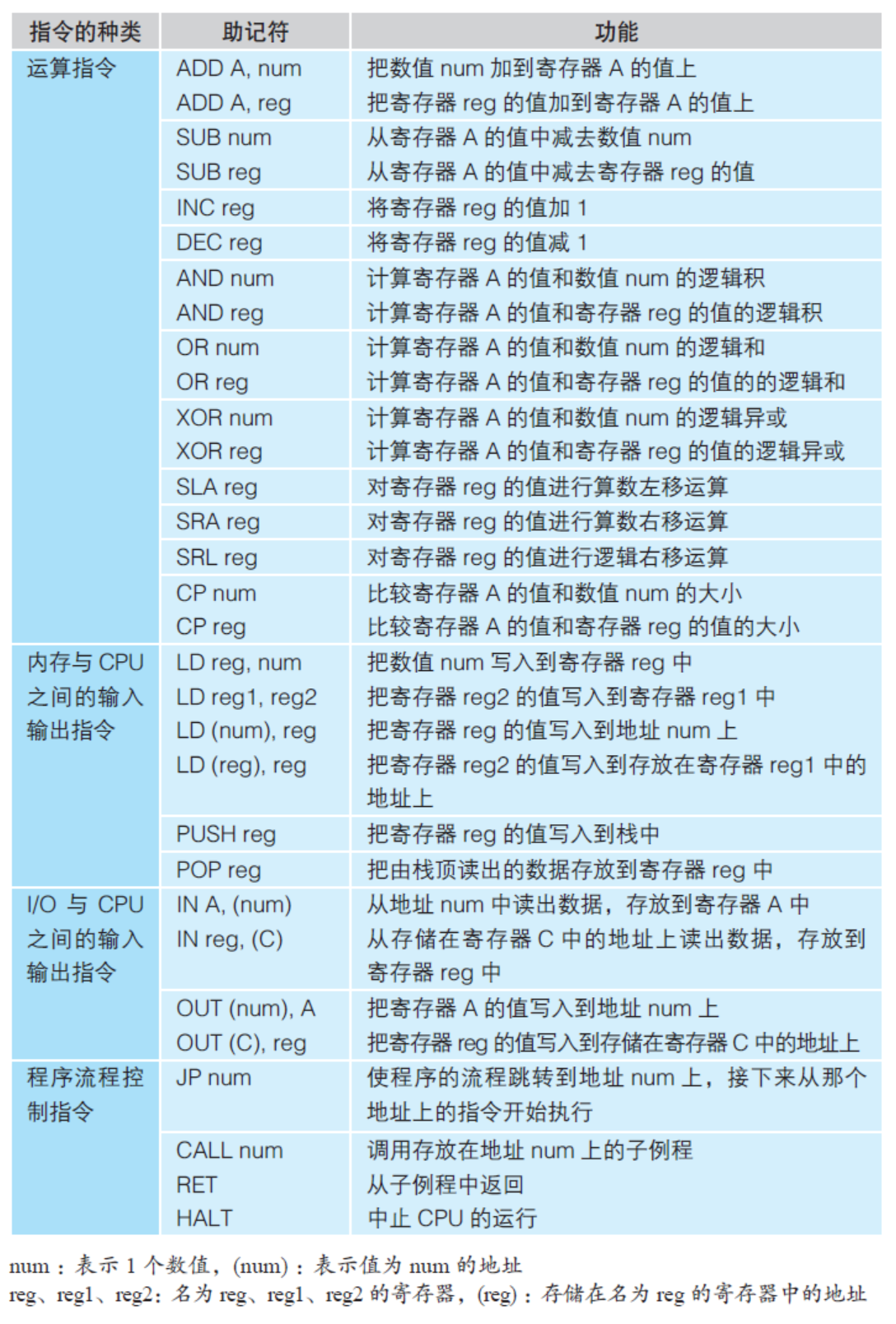
操作数表示的是指令执行的对象。CPU 的寄存器、内存地址、I/O 地址或者直接给出的数字都可以作为操作数。如果某条指令需要多个 操作数,那么它们之间就要用逗号分割。操作数的个数取决于指令的 种类。也有不需要操作数的指令,比如用于停止CPU 运转的HALT 指令。
汇编语言的语法和英语祈使句的语法很像。若对比英语的祈使句 Give me money 和汇编语言的语句,就可以看出在英语的祈使句中,一 开头放置了一个表示“做什么”的动词,这个动词就相当于汇编语言中 的操作码。在动词后面放置了一个表示“动作作用到什么上”的宾语, 这个宾语就相当于汇编语言中的操作数。因为程序的作用是向CPU 发 出指令,而且编程语言又是由说英语的人发明的,所以编程语言与英 语祈使句类似也就不足为奇了。
构成机器语言的是二进制数,而在汇编语言中,则使用十进制数 和十六进制数记录数据。若仅仅写出123 这样的数字,表示的就是十进 制数;而像123H 这样在数字末尾加上了一个H(H 表示Hexadecimal, 即十六进制数),表示的就是十六进制数。在代码清单3.2 所示的程序 中,使用的都是十进制数。
在表3.1 中有这样几条指令希望诸位注意。在第2 章中介绍过, Z80 CPU 的MREQ 引脚和IORQ 引脚实现了一种能区分输入输出对象 的机制,可以区分出使用着相同内存地址的内存和I/O。在汇编语言 中,读写内存的指令不同于读写I/O 的指令。一旦执行了读写内存的指 令,比如LD 指令,MREQ 引脚上的值就会变为0,于是内存被选为输 入输出的对象;而一旦执行了读写I/O 的指令,比如IN 或OUT 指令, IORQ 引脚上的值就会变为0,于是I/O(这里用的是Z80 PIO)被选为 输入输出的对象。
3.3 Z80 CPU 的寄存器结构
这里先稍微复习一下第2 章的内容。计算机的硬件有三个基本要 素,CPU、内存和I/O。CPU 负责解释、执行程序,从内存或I/O 输入 数据,在内部进行运算,再把运算结果输出到内存或I/O。内存中存放 着程序,程序是指令和数据的集合。I/O 中临时存放着用于与周边设备 进行输入输出的数据。
复习就到这里,下面就来扩充所学到的知识吧。既然数据的运算是在CPU 中进行的,那么在CPU 内部就应该有存储数据的地方。 这种存储数据的地方叫作“寄存器”。虽然也叫寄存器,但是与I/O 的寄存器不同,CPU 的寄存器不仅能存储数据, 还具备对数据进行运算的能力。CPU 带有什么样的寄存器取决于CPU 的种类。 Z80 CPU 所带有的寄存器如图3.2 所示。A、B、C、D 等字母是寄存器的名字。 在汇编语言当中,可以将寄存器的名字指定为操作数。
图3.2 Z80 CPU 的寄存器
Z80 CPU
A F
B C
D E
H L
I R
IX
IY
SP
PC
A、B、C、D、E、F、H、L 每个寄存器都带有一个辅助寄存器,本节省略了对它们的介绍。
IX、IY、SP、PC 这4 个寄存器的大小是16 比特,其余寄存器的大小都是8 比特。寄存器的用途取决于它的类型。 有的指令只能将特定的寄存器指定为操作数。
举例来说,A 寄存器也叫作“累加器”,是运算的核心。所以连接 到它上面的导线也一定会比其他寄存器的多。F 寄存器也叫作“标志寄 存器”,用于存储运算结果的状态,比如是否发生了进位,数字大小的 比较结果等。PC 寄存器也叫作“程序指针”,存储着指向CPU 接下来 要执行的指令的地址。PC 寄存器的值会随着滴答滴答的时钟信号自动 更新,可以说程序就是依靠不断变化的PC 寄存器的值运行起来的。SP 寄存器也叫作“栈顶指针”,用于在内存中创建出一块称为“栈”的临 时数据存储区域。
既然诸位已经熟悉了寄存器的功能,下面笔者就开始介绍代码清 单3.2 的内容。这段程序大体上可以分为两部分——“设定Z80 PIO” 和“与Z80 PIO 进行输入输出”。Z80 PIO 带有两个端口(端口A 和端 口B),用于与周边设备输入输出数据。首先必须为每个端口设定输入 输出模式。这里端口A 用于接收由指拨开关输入的数据,为了实现这 个功能,需要如下的代码。
LD A, 207
OUT (2), A
LD A, 255
OUT (2), A
这里的207 和255 是连续向Z80 PIO 的端口A 控制寄存器(对应 该I/O 的地址编号为2)写入的两个数据。虽然使用OUT 指令可以向 I/O 写入数据,但是不能直接把207、255 这样的数字作为OUT 指令的 操作数。操作数必须是已存储在CPU 寄存器中的数字,这是汇编语言 的规定。
于是,先通过指令“LD A, 207”把数字207 读入到寄存器A 中, 再通过指令“OUT (2), A”把寄存器A 中的数据写入到I/O 地址所对应 的寄存器中。像“(2)”这样用括号括起来的数字,表示的是地址编号。 端口A 控制寄存器的I/O 地址是2 号。
一旦把207 写入到端口A 控制寄存器,Z80 PIO 就明白了:“哦, 想要设定端口A 的输入输出模式啊。”而通过接下来写入的255,Z80 PIO 就又知道:“哦,要把端口A 设定为输入模式啊。”
同样地,通过下面的程序可以将端口B 设定为输出模式。
LD A, 207
OUT (3), A
LD A, 0
OUT (3), A
先把207 写入到端口B 控制寄存器(对应的I/O 地址为3 号),然 后写入0。这个0 表示要把端口B 设定为输出模式。应该使用什么样的 数字设定端口,在Z80 PIO 的资料上都有说明。用207、255、0 这样 的数字来表示功能设定参数,这也是为了适应计算机的处理方式。
完成了Z80 PIO 的设定后,就进入了一段死循环处理,用于把由指 拨开关输入的数据输出到LED。为了实现这个功能,需要如下的代码。
LOOP: IN A, (0)
OUT (1), A
JP LOOP
“IN A, (0)”的作用是把数据由端口A 数据寄存器(连接在指拨开 关上,对应的I/O 地址为0 号)输入到CPU 的寄存器A。“OUT (1), A” 的作用是把寄存器A 的值输出到端口B 数据寄存器上(连接在LED 上,对应的I/O 地址为1 号)。
“JP LOOP”的作用是使程序的流程跳转到LOOP(笔者随意起的 一个标签名)标签所标识的指令上。JP 是Jump 的缩写。“IN A, (0)”所 在行的开头有一个标签“LOOP:”,代表着这一行的内存地址。正如刚 才所讲的那样,在用汇编语言编程时,如果老想着“这一行对应的内存 地址是什么来着?”就会很不方便,所以就要用“LOOP:”这样的标签 代替内存地址。当把标签作为JP 指令的操作数时,标签名的结尾不需 要冒号“:”,但是在设定标签时,标签名的结尾则需要加上一个冒号, 这一点请诸位注意。
3.4 追踪程序的运行过程
用汇编语言编写的程序是不能直接运行的,必须先转换成机器语 言。机器语言是唯一一种CPU 能直接理解的编程语言。从汇编语言到 机器语言的转换方法将在稍后介绍,这里先来看一下代码清单3.3,里 面列出了事先转换出来的机器语言,以及对应的汇编语言。1 条汇编语 言的指令所对应的机器语言由多个字节构成。而且,同样是汇编语言 中的1 条指令,有的指令对应着1 个字节的机器语言,有的指令则对 应着多个字节的机器语言。汇编语言中的1 条指令能转换成多少条机 器语言取决于指令的种类以及操作数的个数。代码清单3.3 中第一个内 存地址是00000000(0 号地址),下一个地址是00000010(2 号地址), 中间隔了2 个地址,这说明如果从0 号地址开始存储一条2 字节的机 器语言,那么下一条机器语言就从2 号地址开始存储。
代码清单3.3 汇编语言与机器语言的对应关系
地址 机器语言 标签 操作码 操作数
00000000 00111110 11001111 LD A, 207
00000010 11010011 00000010 OUT (2), A
00000100 00111110 11111111 LD A, 255
00000110 11010011 00000010 OUT (2), A
00001000 00111110 11001111 LD A, 207
00001010 11010011 00000011 OUT (3), A
00001100 00111110 00000000 LD A, 0
00001110 11010011 00000011 OUT (3), A
00010000 11011011 00000000 LOOP: IN A, (0)
00010010 11010011 00000001 OUT (1), A
00010100 11000011 00010000 00000000 JP LOOP
下面就一边看着代码清单3.3,一边跟随着CPU 解释、执行机器 语言程序吧。在这里,我们假设机器语言的程序是像代码清单3.3 那样 被存储在内存中的。
一旦重置了CPU,00000000 就会被自动存储到PC 寄存器中,这 意味着接下来CPU 将要从00000000 号地址读出程序。首先CPU 会从 00000000 号地址读出指令00111110,判断出这是一条由2 个字节构成 的指令,于是接下来会从下一个地址(即00000001,1 号地址,代码清 单3.3 中并没有标记出该地址本身)读出数据11001111,把这两个数据 汇集到一起解释、执行。执行的指令是把数值207 写入到寄存器A, 用汇编语言表示的话就是“LD A, 207”。这时,由于刚刚从内存读出了 一条2 字节的指令(占用2 个内存地址),所以PC 寄存器的值要增加 2,并接着从00000010 号地址读出指令,解释并执行。
接下来的流程与此类似,通过反复进行“读取指令”“解释、执行 指令”“更新PC 寄存器的值”这3 个操作,程序就能运行起来了。一 旦执行完最后一行的JP LOOP 所对应的机器语言,PC 寄存器的值就会 被设为标签LOOP 对应的地址00010000,这样就可以循环执行同样的 操作。请诸位重点观察PC 寄存器是如何控制程序流程的。
3.5 尝试手工汇编
在CPU 的资料中,明确写有所有可以使用的助记符,以及助记符 转换成机器语言后的数值。只要查看这些资料,就可以把用汇编语言 编写的程序手工转换成机器语言的程序,这样的工作称为“手工汇编”。 进行手工汇编时,要一行一行地把用汇编语言编写的程序转换成机器 语言。下面就实际动手试一试吧。表3.2 列出了汇编语言中必要指令的 助记符、助记符所对应的机器语言,以及执行这些机器语言所需的时 钟周期数。
表3.2 从助记符到机器语言的转换方法
助记符 机器语言 时钟周期数
LD A, num 00111110 num 7
OUT (num), A 11010011 num 11
IN A, (num) 11011011 num 11
JP num 11000011 num 10
下面就从汇编语言的第1 行开始转换。第一行的“LD A, 207”匹 配“LD A, num”这个模式,所以可以先转换成“00111110 num”。然后 将十进制数的207 转换成8 比特的二进制数,用这个二进制数替换 num。使用Windows 自带的计算器程序就可以很方便地把十进制数转 换成二进制数。从Windows 的开始菜单中选择“运行”,输入calc 后点 击“确定”按钮,就可以启动计算器程序。
接下来,从计算器的“查看”菜单中选择“科学型”,这样就得到 了一个可以用十进制数或二进制数表示数字的计算器了。首先选中“十 进制”单选框,然后输入207,接下来选中“二进制”单选框,这样 207 就变成了二进制数的11001111(如图3.3 所示)。至此,“LD A, 207”就转换成了机器语言00111110 11001111。由于这条指令存储在内 存最开始的部分(00000000 号地址),所以要把这条指令和内存地址像 下面这样并排写下来。
地址 汇编语言 机器语言
00000000 LD A, 207 00111110 11001111

图3.3 用Windows 的计算器程序把十进制数转换成二进制数
第2 条指令“OUT (2), A”匹配“OUT (num), A”这个模式,所以 可以先转换成“11010011 num”。然后把num 的部分替换成00000010, 即用8 比特的二进制数表示的十进制数2,最终就得到了机器语言 “11010011 00000010”。因为内存中已经存储了2 字节的机器语言,所 以这条机器语言要从00000010 号地址(用十进制表示的话就是2 号地 址)开始记录。
地址 汇编语言 机器语言
00000010 OUT (2), A 11010011 00000010
这之后由于LD 指令和OUT 指令又以相同的模式出现了3 次,所 以可以用相同的步骤转换成机器语言。请诸位注意,机器语言中每条 语句的字节数是多少,内存地址就相应地增加多少。
地址 汇编语言 机器语言
00000100 LD A, 255 00111110 11111111
00000110 OUT (2), A 11010011 00000010
00001000 LD A, 207 00111110 11001111
00001010 OUT (3), A 11010011 00000011
00001100 LD A, 0 00111110 00000000
00001110 OUT (3), A 11010011 00000011
接下来是“IN A, (0)”匹配“IN A, (num)”这个模式,所以可以先转 换成“11011011 num”。然后把num 替换成00000000,即用8 比特的二 进制数表示的十进制数0,最终就得到了机器语言“11011011 00000000”。 对于接下来的“OUT (1), A”,也可以按照同样的方法转换。
地址 汇编语言 机器语言
00010000 IN A, (0) 11011011 00000000
00010010 OUT (1), A 11010011 00000001
最后一句的JP LOOP 匹配模式“JP num”, 所以可以先转换成 “11000011 num”。请注意这里要用16 比特的二进制数替代作为内存地 址的num。在微型计算机中是以8 比特为单位指定内存地址的,但在 Z80 CPU 中用于设定内存地址的引脚却有16 个,所以在机器语言中也 要用16 比特的二进制数设定内存地址。JP 指令跳转的目的地为 00010000,即“LOOP:”标签所标示的语句“LD A, 0”对应的内存地 址。把这个地址扩充为16 比特就是“00000000 00010000”。要扩充到 16 位,只需要把高8 位全部设为0 就可以了。
地址 汇编语言 机器语言
00010100 JP LOOP 11000011 00010000 00000000
还有一点希望诸位注意,在将一个2 字节的数据存储到内存时, 存储顺序是低8 位在前、高8 位在后(也就是逆序存储)。这样的存储 顺序叫作“小端序”(Little Endian),与此相反,将数据由高位到低位 顺序地存储到内存的存储顺序则叫作“大端序”(Big Endian)。根据 CPU 种类的不同,有的CPU 使用大端序,有的CPU 使用小端序。Z80 CPU 使用的是小端序,因此JP LOOP 对应的机器语言为“11000011 00010000 00000000”。
手工汇编至此就结束了。自己写的汇编语言程序,又通过自己的 双手转换成了机器语言,我们应该为此感到骄傲。
3.6 尝试估算程序的执行时间
在本章的最后,介绍一下如何通过时钟周期数估算程序的执行时 间。请先向前翻到表3.2,找出执行每条汇编语言指令所需的时钟周期 数。然后把代码清单3.2 中所用到的每条指令的时钟周期数累加起来。 于是可以算出到LOOP 标签为止的8 条指令共需要7+11+7+11+7+ 11+7+11 = 72 个时钟周期;LOOP 标签之后的3 条指令共需要11+11 +10 = 32 个时钟周期。因为微型计算机采用的是2.5MHz 的晶振,也 就是1 秒可以产生250 万个时钟周期,所以每个时钟周期是1 秒÷250 万 = 0.0000004 秒 = 0.4 微秒。72 个时钟周期就是72×0.4 = 28.8 微秒; 32 个时钟周期就是12.8 微秒。这段程序是用LED 的亮或灭来表示指 拨开关的开关状态,所以LOOP 标签之后所执行的操作“输入、输出、 跳转”每1 秒可以反复执行1 秒÷12.8 微秒/ 次 = 78125 次之多,可见 计算机的计算速度有多么惊人。
☆ ☆ ☆
比起C 语言或BASIC 等高级语言,汇编语言的语法简单、指令数少,说不定会更加容易学习,可是今天还在使用汇编语言的人却是凤 毛麟角了。使用汇编语言编程时,因为要事无巨细地列出计算机的行为,所以程序会变得冗长繁复。 因此诸位只在纸上体验汇编语言、机器语言以及手工汇编就足够了。只要具备了这些知识, 即便是用C 语言或BASIC 等编程语言编程时,也一样能感受到计算机底层的工作方式,也就是说变得更加了解计算机了。
在接下来的第4 章中,笔者将要介绍条件分支和循环等“程序的流程”,还会稍微介绍一些有关“算法”的内容。敬请期待!
第 4 章 程序像河水一样流动着
- 热身问答
初级问题:Flow Chart 的中文意思是什么?
中级问题:请说出自然界中河流的三种流动方式。
高级问题:事件驱动是什么?
- 答案
初级问题: 流程图。
中级问题: 向着一个方向流淌;流着流着产生支流;卷成漩涡。
高级问题: 用户的操作等产生事件后,由事件决定程序的流程。
- 解释
初级问题: 流程图(Flow Chart)是指用图的形式表示程序的流程。
中级问题: 与河流的流动方式一样,程序的流程也分为三种。在程序中,把犹如水流向着一个方向流淌的流程称作“顺序执行”; 把犹如水流流着流着产生了支流的流程称作“条件分支”;把犹如水流卷成漩涡的流程称作“循环”。
高级问题: Windows 应用程序的运行就是由事件驱动的。例如,选择“打开文件”菜单项就能打开一个窗口, 在里面可以指定要打开文件的名称和存储位置。之所以能够这样是因为一旦触发了“选中了菜单项”这个事件, 程序的流程就相应地流转到了处理打开窗口的那部分。
- 本章重点
本章的主题是程序的流程。程序员一般都是先考 虑程序的流程再开始编写程序的。只有编写过程序的 人才能体会到“程序是流动着的”。一个人编写的程序如果不能按照预 期运行,就说明他还没有很好地掌握“程序是流动着的”这一概念。 为什么说“程序是流动着的”呢?因为作为计算机大脑的CPU 在 同一时刻基本上只能够解释、执行一条指令。把指令和作为指令操作 对象的数据排列起来就形成了程序。请想象把若干条指令一条挨一条 地依次排列到一条长长的纸带上。然后把这条纸带展开抻平,从顶端 开始依次解释并执行上面的每条指令,这样看起来程序就好像流动起 来了。这就是程序的流程。但是程序的流程并不是只有这一种。那么 下面笔者就先介绍一下程序流程的种类吧。
- 4.1 程序的流程分为三种
诸位读到此处,应该能够从硬件上想像出计算机的运作方式了吧。 计算机的硬件系统由CPU、I/O 和内存三部分构成。内存中存储着程 序,也就是指令和数据。CPU 配合着由时钟发生器发出的滴答滴答的 时钟信号,从内存中读出指令,然后再依次对其进行解释和执行。 CPU 中有各种各样的各司其职的寄存器。其中有一个被称为PC (Program Counter,程序计数器)的寄存器,负责存储内存地址,该地 址指向下一条即将执行的指令。每解释执行完一条指令,PC 寄存器的 值就会自动被更新为下一条指令的地址。 PC 寄存器的值在大多数情况下只会增加。下面假设PC 寄存器正 指向内存中一个从10 号地址开始的3 字节指令。CPU 解释执行完这条 指令后,PC 寄存器中的值就变成10+3 = 13 了。也就是说,程序基本 上是从内存中的低地址(编号较小的地址)开始,向着高地址(编号较 大的地址)流下去的 。我们把程序的这种流动称为“顺序执行”(如图 4.1 所示)。
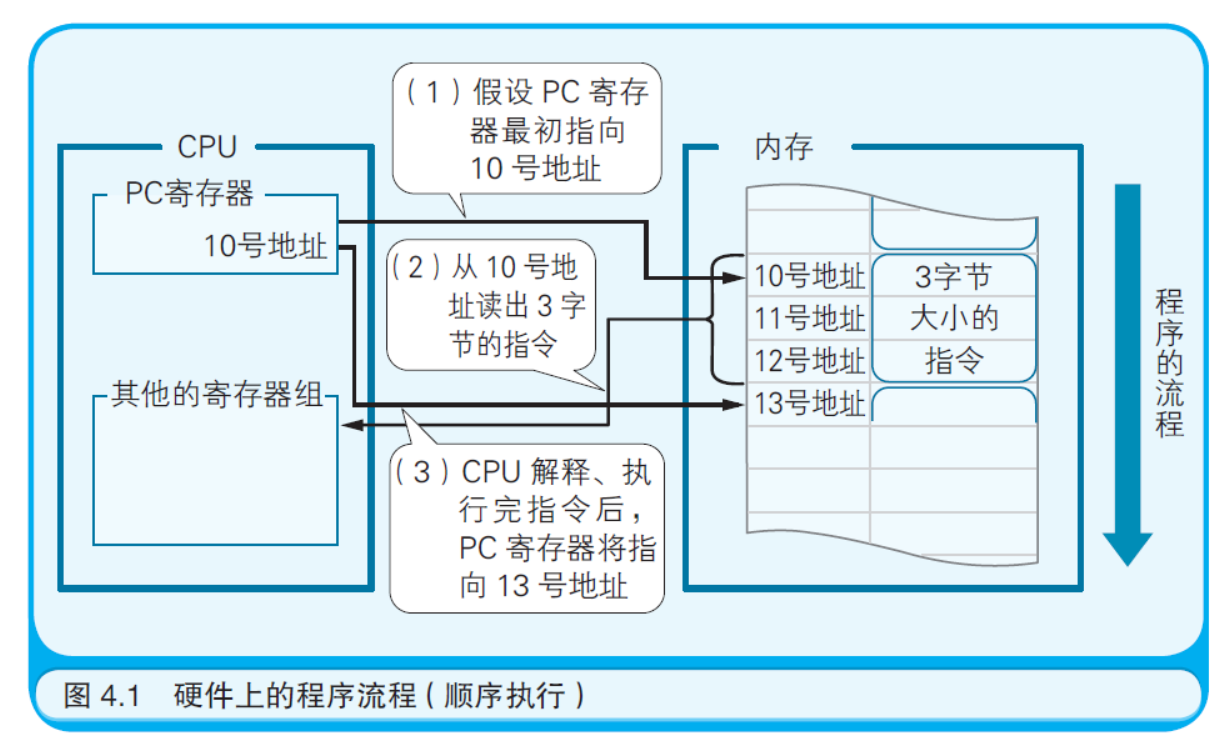
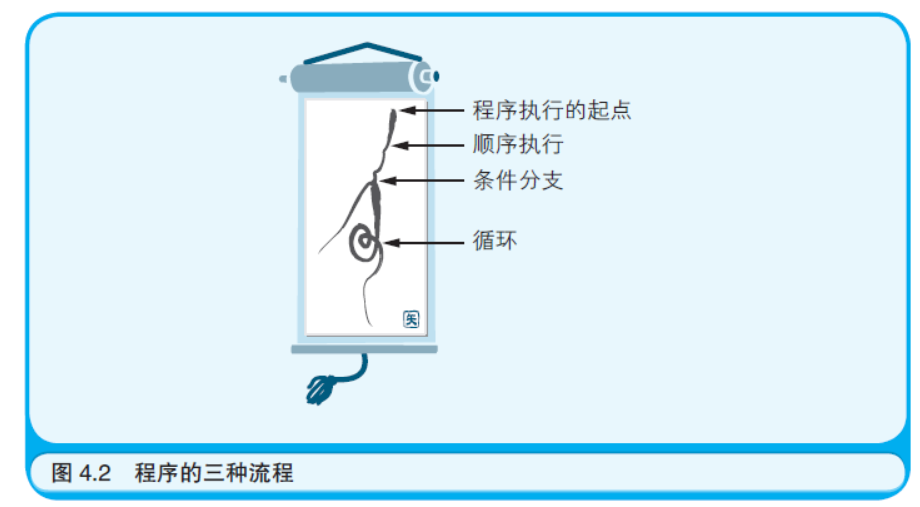
程序的流程总共有三种。除了顺序执行以外,还有“条件分支”和 “循环”。因为只有这三种,记忆起来还是很轻松的吧。 正如上文所述,顺序执行是按照指令记录在内存中的先后顺序依 次执行的一种流程。而循环则是在程序的特定范围内反复执行若干次 的一种流程。条件分支是根据若干个条件的成立与否,在程序的流程 中产生若干个分支的一种流程。无论规模多么大多么复杂的程序,都 是通过把以上三种流程组合起来实现的。 程序的三种流程正像是河流本身。从高山的泉眼中涌出的清泉形 成了河流的源头(程序执行的起点)。水流从山中缓缓流下,有时向着 一个方向流淌(顺序执行),有时中途分出了支流(条件分支),还有时 由于地势卷起了漩涡(循环)。难道诸位不认为程序的流程也很美吗? 完全就像是裱在画轴上的山水画一样(如图4.2 所示)。还有一种称作 “无条件分支”的流程,它就仿佛是大雨瓢泼引发的泥石流,突然就向 着某处流去了,可以认为这是一种特殊的条件分支。
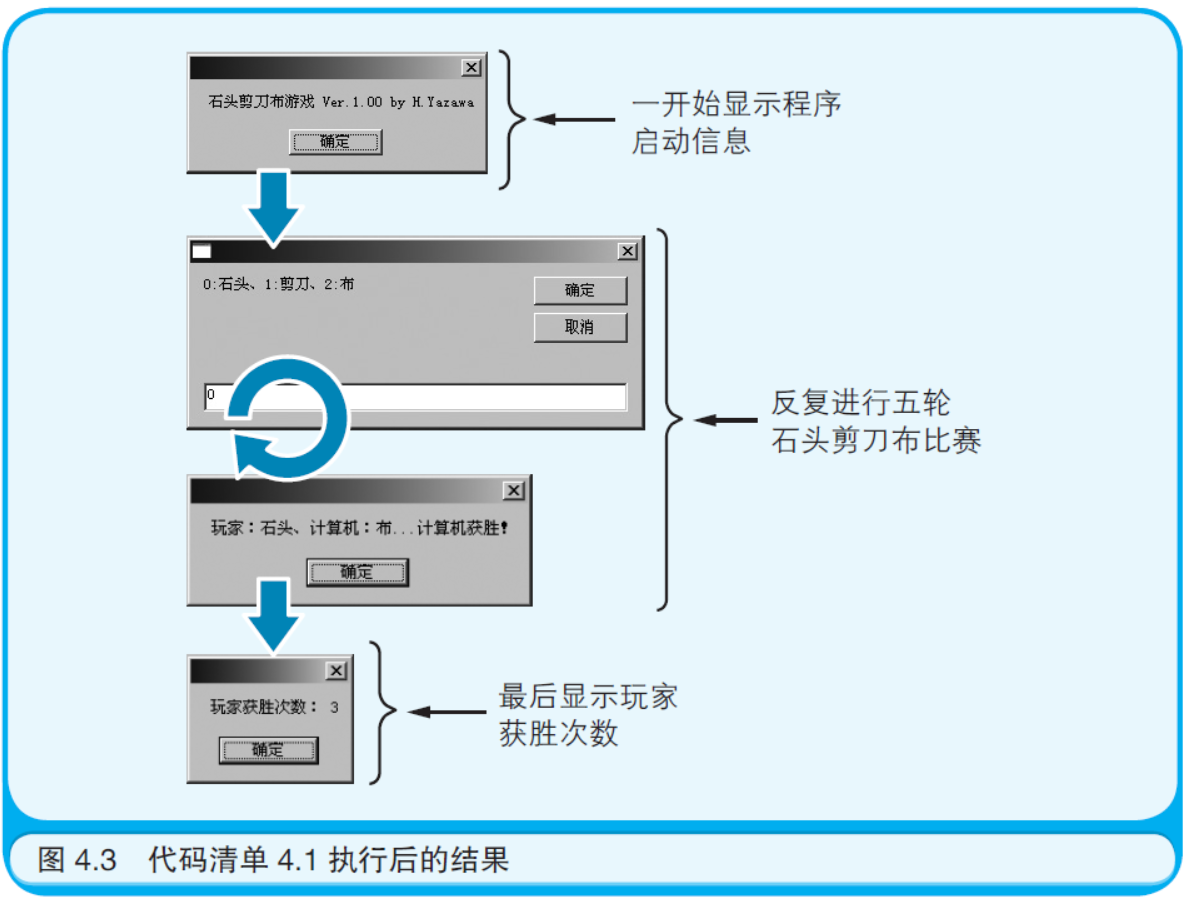
虽然可能不如山水画那样优美,但是我还是要给诸位展示一段简 单的程序。代码清单4.1 中列出了用VBScript(Visual Basic Scripting Edition)编写的“石头剪刀布游戏”的代码,VBScript 是BASIC 语言 的一个版本。该程序可以在Windows 98/Me/2000/XP 操作系统上运 行(用于执行VBScript 程序的WSH(Windows Script Host)已作为标准组件,被集成进Windows 98/Me/2000/XP 操作系统)。 玩家和计算机可以进行五轮石头剪刀布比赛,比完后会显示玩家 获胜的次数。 请诸位用记事本等文本编辑器编写这个程序,并存储到扩展名为 “.vbs”的文件中,比如ShitouJiandaoBu.vbs。只要双击保存后的文件, 程序就可以执行了(如图4.3 所示)。
代码清单4.1 用VBScript 编写的“石头剪刀布游戏”
' 初始化表示手势的变量
Dim gesture(2)
gesture(0) = " 石头"
gesture(1) = " 剪刀"
gesture(2) = " 布"
' 初始化对玩家获胜次数计数的变量
wins = 0
' 初始化随机数种子
Randomize
' 显示程序启动信息
MsgBox " 石头剪刀布游戏 Ver.1.00 by H.Yazawa"
' 进行五轮比试
For i = 1 To 5
' 输入玩家的手势
user = CInt(InputBox("0: 石头、1: 剪刀、2: 布"))
' 用随机数决定计算机的手势
computer = CInt(Rnd * 2)
' 生成提示双方出的手势的字符串
s = " 玩家:" & gesture(user) & "、计算机:" & gesture(computer)
' 判定胜负,显示结果
If user = computer Then
MsgBox s & "... 平局! "
ElseIf computer = (user + 1) Mod 3 Then
MsgBox s & "... 玩家获胜! "
wins = wins + 1
Else
MsgBox s & "... 计算机获胜! "
End If
Next
' 显示玩家的获胜次数
MsgBox " 玩家获胜次数: " & wins
- 4.2 用流程图表示程序的流程
代码清单4.1 所示的“石头剪刀布游戏”的程序是由顺序执行、条 件分支和循环三种流程组成的。对于没有学过VBScript 的人来说,也 许会觉得程序代码就好像是魔法的咒语一样。因此就需要用一种无论 是谁都能明白的方法来表示代码清单4.1 中的程序。为此所使用的图 表,就是诸位都已经知道的“流程图”。
所谓流程图,正如其名,就是表示程序流程(Flow)的图(Chart)。 有很多专业的程序员,他们在编写程序前,都会通过画流程图或是类 似的图来思考程序的流程(如图4.4 所示)。
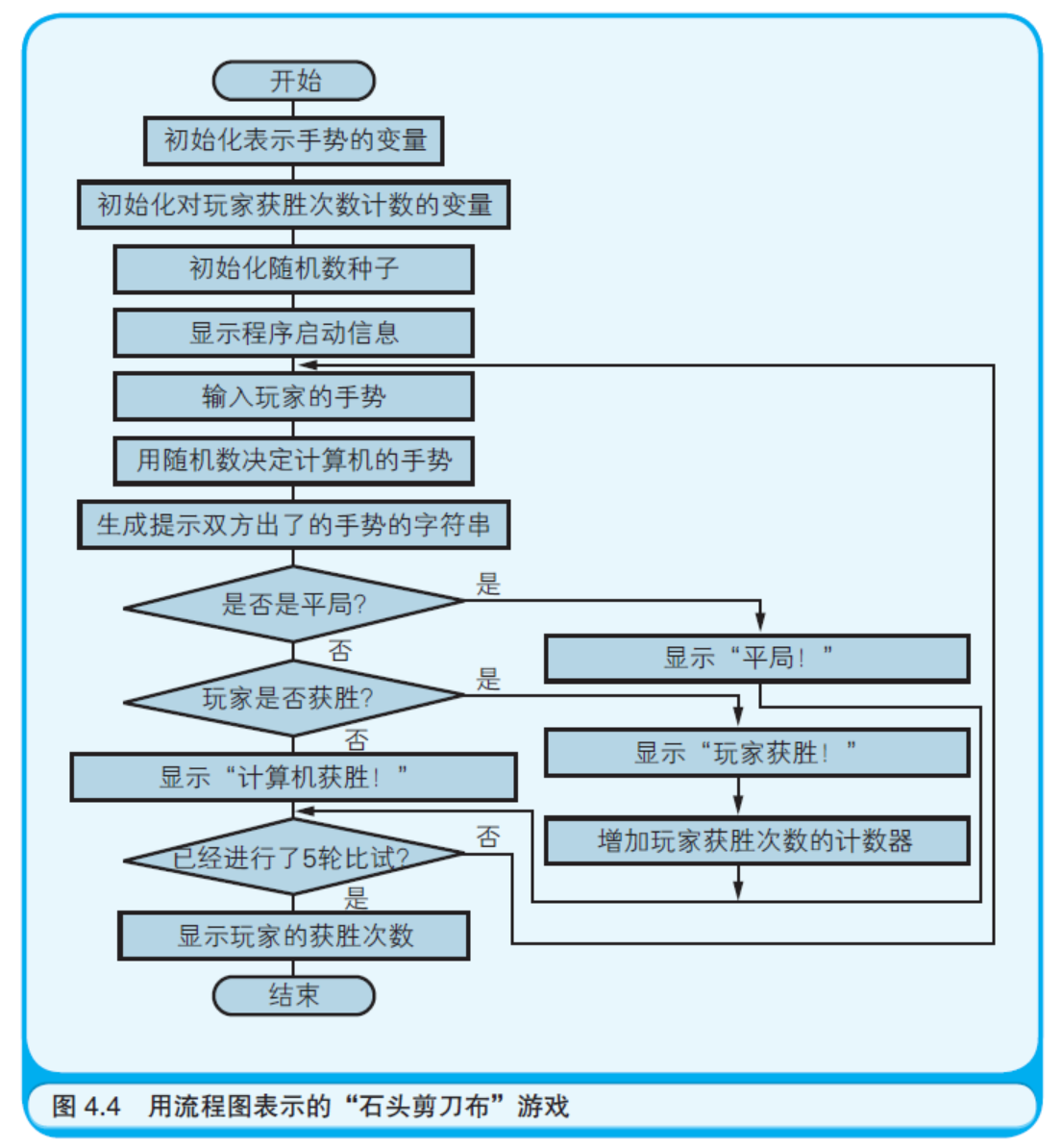
流程图的方便之处在于它并不依赖于特定的编程语言。图4.4 的流 程图所表示的流程不仅能转换成VBScript 程序,还可以转换成用其他 语言编写的程序,比如C 语言或Java 语言。可以认为编程语言只不过 是将流程图上的流程用文字(程序)重现出来罢了。各种编程语言的差 异正如一种自然语言中各地方言的差异一样。只要给出了详细的流程 图,就可以编写出基本相同的程序。笔者也曾有过这样的经历,画流 程图花费了一个月之久,但是对照着流程图专心写程序只需要两天的 时间。
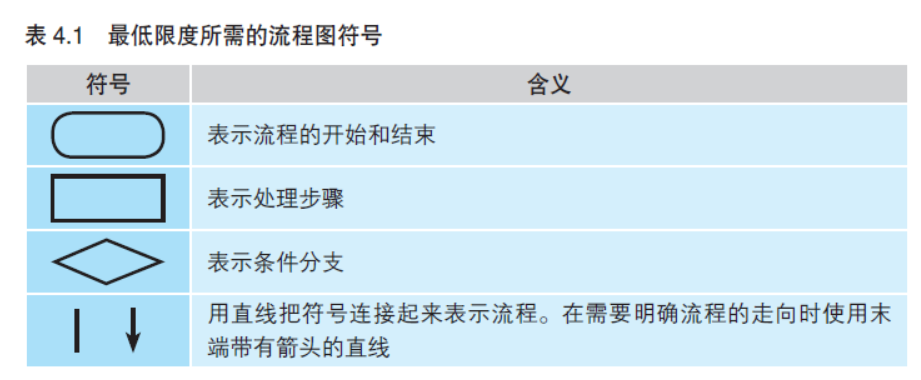
话说回来,诸位都善于画流程图吗?是不是有很多人会觉得在流 程图中有那么多的符号,在画图时要把这些符号都用上很麻烦呢? 实际上用于表示程序流程的最基础的符号并没有多少。只要先记 住表4.1 中的符号就足够了。就连笔者也很少使用这张表以外的符号。 虽然有时也能见到形如显示器或者打印纸的符号,但是可以认为这些 只是为了丰富流程图的表现所附加的符号。
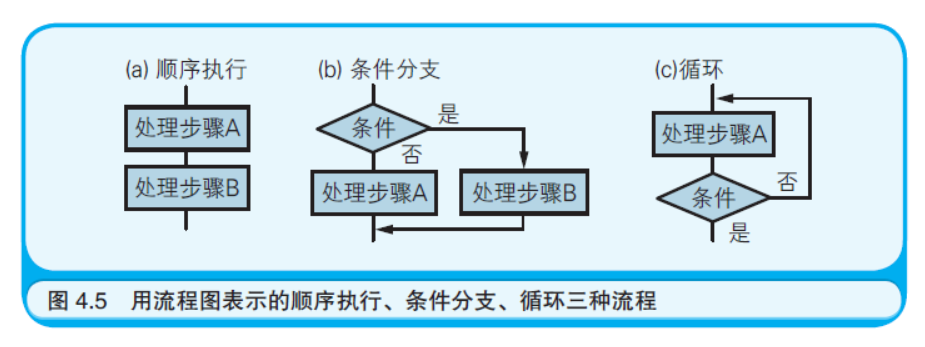
只使用表4.1 中所示的符号,就可以画出程序的三种流程(如图 4.5 所示)。顺序执行只需用直线将矩形框连接起来(a)。条件分支用菱 形表示(b)。循环的表示方法是通过条件分支回到前面的处理步骤(c)。 这样就能将所有的流程都表示出来了。
作为程序员必须要学会灵活地运用流程图。在思考程序流程的时 候,也要首先在头脑中画出流程图。
- 4.3 表示循环程序块的“帽子”和“短裤”
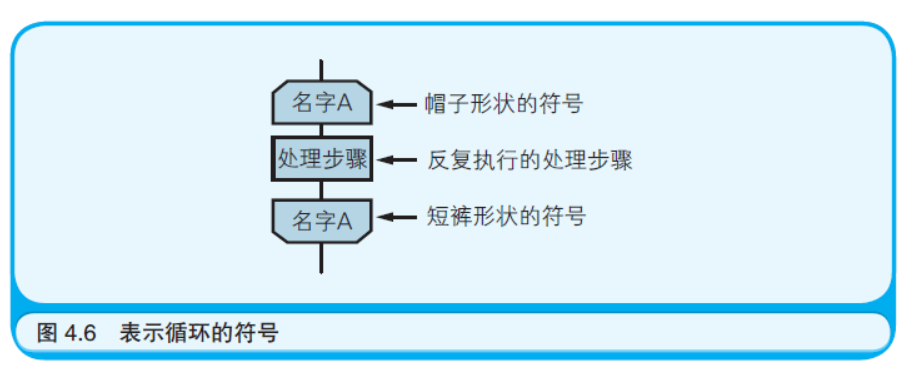
再继续介绍一些有关流程图的内容吧。如果诸位曾经备考过“信息 技术水平考试”,就应该见过用如图4.6 所示的符号表示循环的流程图。 笔者将这一对符号称作“帽子和短裤”(这当然不是正式的名称)。
对于帽子形状和短裤形状的符号,为了表示它们是成对出现的, 要在上面写下适当的名字。然后用“帽子”和“短裤”把需要反复执行 的步骤包围起来。如果要在循环中嵌套循环,就需要对每个循环分别 使用一对“帽子”和“短裤”。为了区分成对出现的“帽子”和“短裤”, 要为每一对起不同的名字。
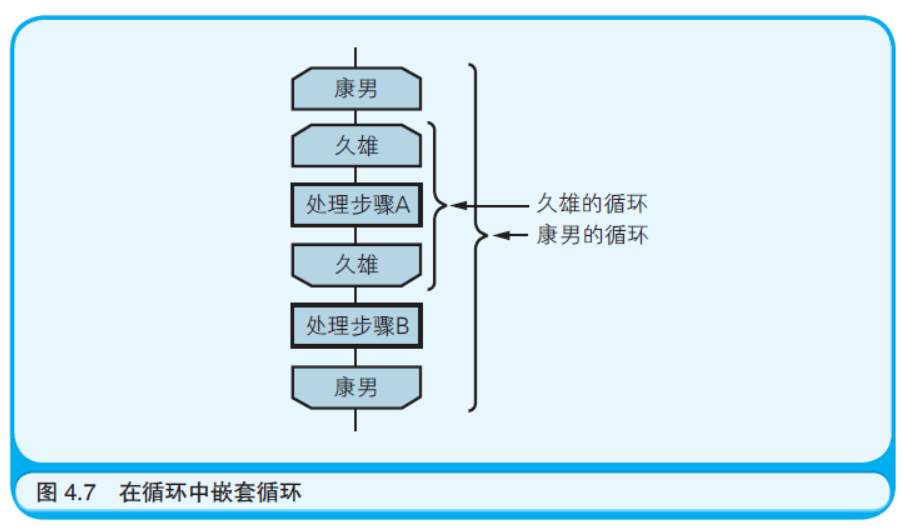
稍微说一点题外话。笔者的名字是久雄,有一个叫康男的哥哥。 洗衣服时,如果把哥哥的帽子和短裤和我的混在一起洗的话,就不知 道哪件是哥哥的、哪件是我的了。于是,母亲就在我们哥俩儿的帽子 和短裤上分别写上了个人的名字。在流程图的“帽子”和“短裤”符号 上写名字也出于同样的目的(如图4.7 所示)。
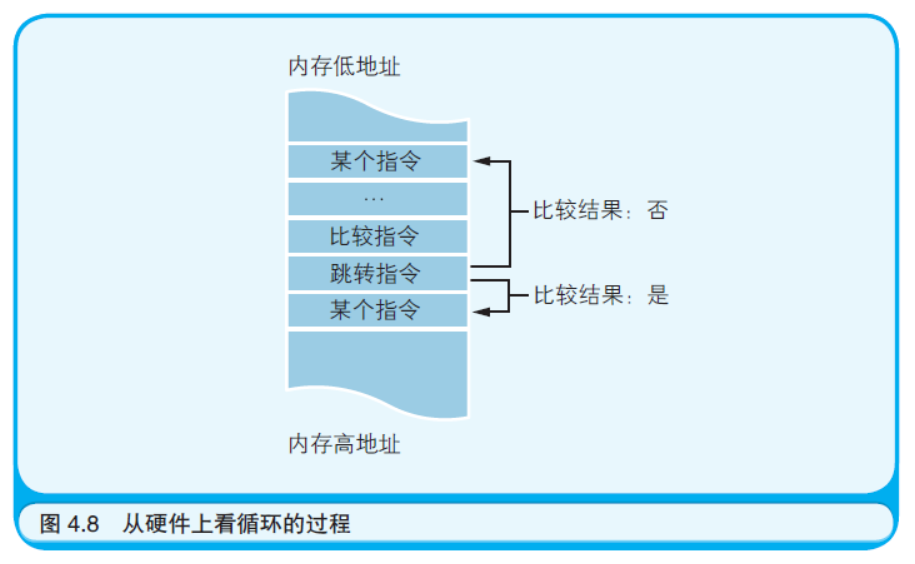
上面的内容稍微有点跑题,下面我们回到正题。在计算机硬件上 的操作中,循环是通过当满足条件时就返回到之前处理过的步骤来实 现的。一旦使用了机器语言或汇编语言所提供的跳转指令,就可以将 PC 寄存器的值设置为任意的内存地址。如果将它的值设为之前执行过 的步骤所对应的内存地址,那么就构成了循环。因此,在表示循环的 时候,正如图4.5(c) 所示的那样,仅仅使用带有菱形符号的流程图也就 足够了。用机器语言或者汇编语言表示循环时,都是先进行某种比较, 再根据比较结果,跳转到之前的地址(如图4.8 所示)。
但是,现在还在使用机器语言或汇编语言的人已经不多了。程序 员使用的都是能够更加高效地编写程序的高级语言,如BASIC、C 语 言和Java 等。在这些高级语言中,程序员使用“程序块”表示循环而 不是跳转指令。所谓“程序块”就是程序中代码的集合。程序中要被循 环处理的部分,就是一种程序块。如图4.6 所示的用帽子和短裤符号表 示循环的方法就适用于使用了程序块的高级语言。
代码清单4.2 用高级语言表示循环
' 进行5 轮比试
For i = 1 To 5 # 相当于“帽子”
' 处理步骤
…
Next # 相当于“短裤”
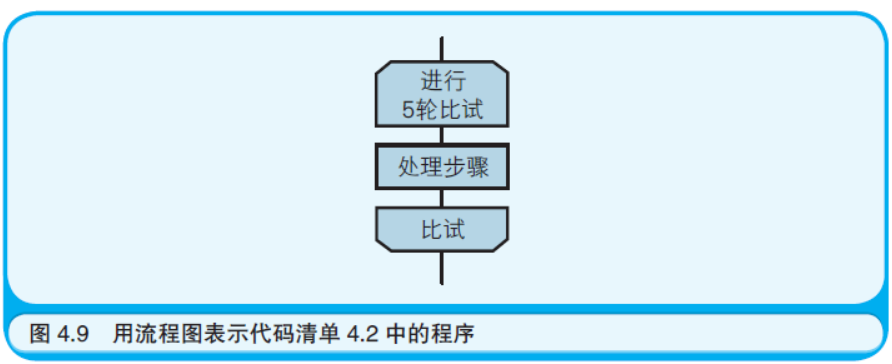
代码清单4.2 列出了从之前的“石头剪刀布游戏”中摘录出的程序 块,这段代码用于循环双方的比试过程。由此可见,在VBScript 中, 是用For 和Next 两个关键字表示循环的程序块的。For 对应着“帽子”, Next 则对应着“短裤”。For 的后面写有循环条件。“For i = 1 To 5”表 示用变量i 存储循环次数,将i 的值从1 加到5,每进行1 次循环就增 加1,如果i 的值超过了5 循环就终止。画图时循环条件也要写在“帽 子”中(如图4.9 所示)。
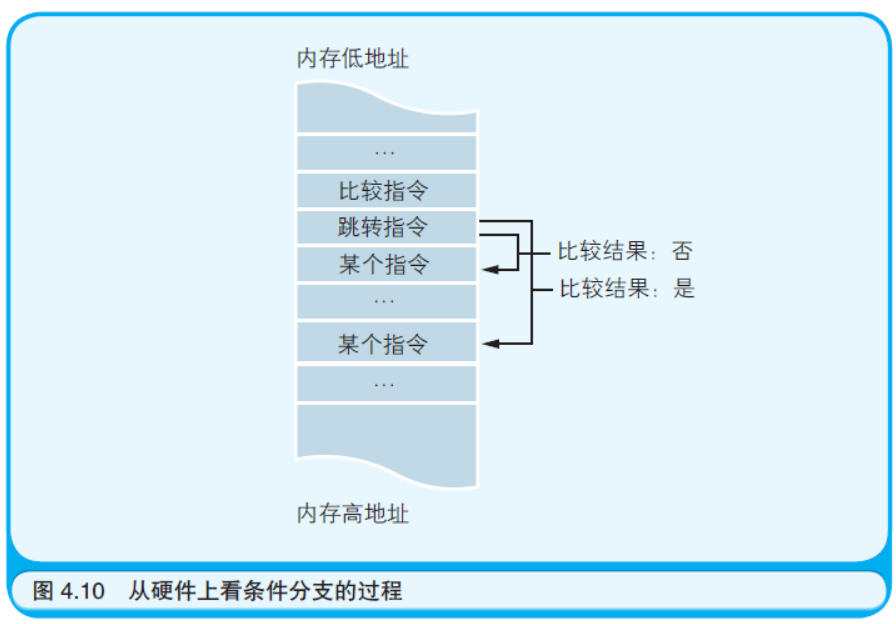
用“帽子”和“短裤”表示循环结构没有什么问题,也适用于使用 高级语言编写的程序。但是在直接表示硬件操作的机器语言和汇编语 言中,是通过条件分支返回到之前处理过的指令来实现循环的,并没 有相当于For 或者Next 的指令。条件分支本身也是通过跳转指令实现 的。根据比较操作的结果,跳转到之前处理过的步骤就是循环;跳转到 之后尚未处理的步骤就是条件分支(如图4.10 所示)。
在高级语言中,条件分支也是由程序块表示的。在VBScript 中, 使用If、ElseIf、Else、End If 表示条件分支的程序块。通过这几个关键 字就可以形成一个被分成三个区域的程序块(如代码清单4.3 所示)。
代码片段4.3 用高级语言表示的条件分支
' 判定胜负,显示结果
If use = computer Then
MsgBox s & "... 平局! " # 区域(1)
ElseIf computer = (user + 1) Mod 3 Then
MsgBOx s & "... 玩家获胜! " # 区域(2)
wins = wins + 1 # 区域(2)
Else
MsgBox s % "... 计算机获胜! " # 区域(3)
End If
如果If 关键字后面所写的条件成立,区域(1) 中所写的代码就会被执 行,形成分支。如果ElseIf 后面所写的条件成立,区域(2) 中所写的代 码就会被执行,形成分支。当这两个条件都不成立时,区域(3) 中所写 的代码就会被执行,形成分支。高级语言的条件分支代码块,可以用 画有菱形符号的流程图表示。
- 4.4 结构化程序设计
既然谈到了程序块,就再介绍一下结构化程序设计吧。诸位即使 不曾亲身经历,也应该在什么地方听说过这个词吧。结构化程序设计 是由学者戴克斯特拉提倡的一种编程风格。简单地说,所谓结构化程 序设计就是“为了把程序编写得具备结构性,仅使用顺序执行、条件分 支和循环表示程序的流程即可,而不再使用跳转指令”。“仅用顺序执 行、条件分支和循环表示程序的流程”这一点是不言自明的,需要请诸 位注意的是“不使用跳转指令”这一点。
作为计算机硬件上的行为,无论是条件分支还是循环都必须使用 跳转指令实现。但是在VBScript 等高级语言中,可以用If~ElseIf~ Else~End If 程序块表示条件分支,用For~Next 程序块表示循环。跳 转指令因此就变得可有可无了。但是即便如此,在很多高级语言中, 还是提供了与机器语言中跳转指令相当的语句,例如VBScript 中的 GoTo 语句。其实戴克斯特拉想表达的是“既然好不容易使用上了高级 语言,就别再使用相当于跳转指令的语句了。即使不使用跳转语句, 程序的所有流程仍然可以表述出来”。他这样说是因为跳转指令所带来 的危害性不小,会使程序陷入到流程错综复杂的状态,就像意大利面 条那样缠绕在一起(如图4.11 所示)。
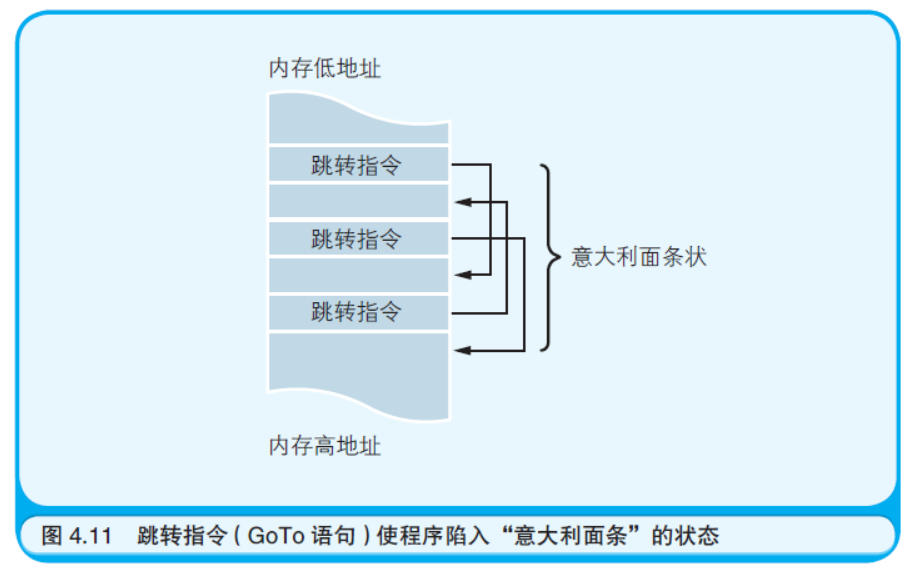
在程序设计的世界中,如果看到了以“结构化”开头的术语,就可 以这样认为:程序的流程是由程序块表示的,而不是用GoTo 语句等跳 转指令实现的。例如,微软的.NET 框架所提供的新版BASIC 语言 Visual Basic.NET 中,就以增加新语法的方式加入了被称作“结构化异 常处理”的错误处理机制。这里所说的异常类似于错误。
在旧版本的Visual Basic 中,一旦发生了错误,程序的流程就会跳 转到执行错误处理的地方。用程序块来表示这种错误处理方式的机制, 就是结构化异常处理。在Visual Basic.NET 中, 用Try~Catch~End Try 程序块来表示结构化异常处理(如代码清单4.4 所示)。但是即使使 用了结构化异常处理,在硬件上使用的也还是跳转指令,只是说在高 级语言中不用再写相当于跳转指令的语句了。如果把用高级语言所编 写的程序转换成机器语言,像结构化异常处理这样的语句还是会被转 换为跳转指令。
代码清单4.4 原始的错误处理机制和结构化异常处理的区别

- 4.5 画流程图来思考算法
为了充分体现流程图的用途,下面稍微涉及一些有关算法的内容。 所谓算法(Algorithm),就是解决既定问题的步骤。想让计算机解决问 题,就需要把问题的解法转换成程序的流程。
仅用一条语句就能实现出“石头剪刀布游戏”的编程语言是不存在 的。如果眼下待解决的问题是如何编写“石头剪刀布游戏”,那么就必 须考虑如何把若干条指令组合起来并形成一个解决问题的流程。如果 能够想出可以巧妙实现“石头剪刀布游戏”的流程,那么这个问题也就 解决了,换言之算法也就实现了。要是诸位被前辈问到:“这个程序的 算法是怎样的呢?”那么只要回答清楚程序的流程就可以了。或者画出 流程图也是可以的,因为表示程序流程的流程图本身就能解释算法。
思考算法时的要点是要分两步走,先从整体上考虑程序的粗略流 程,再考虑程序各个部分细节的流程。有关细节上的流程将在下一章 介绍,在这里笔者先介绍粗略的流程。这是一种相当简单的流程,虽 然或多或少会有例外,但是几乎所有的程序从整体来看都具有一个一 成不变的流程,那就是“初始化处理”→“循环处理”→“收尾处理”。
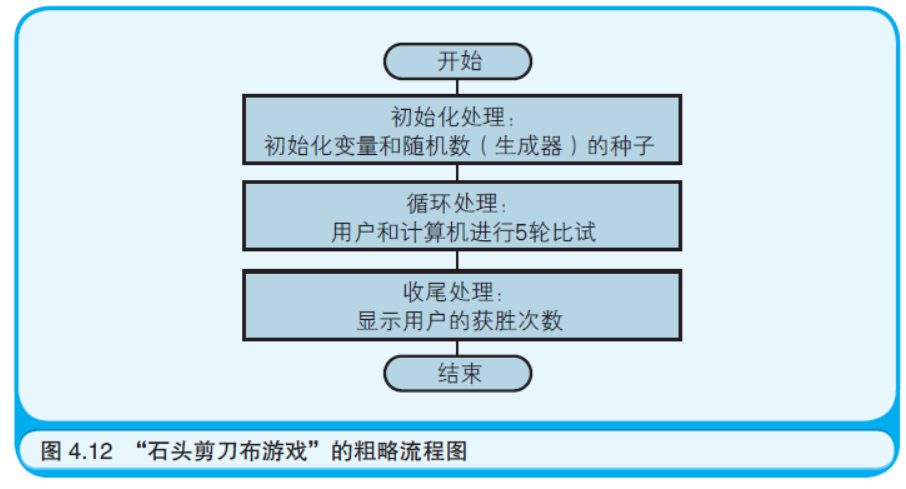
请试想,用户是怎样使用程序的呢?首先,用户启动了程序(程序 执行初始化处理)。接下来用户根据自己的需求操作程序(程序进入循 环处理阶段)。最后用户关闭了程序(程序执行收尾处理)。这样的使用 方法就可以直接作为程序的整体流程。还是以“石头剪刀布游戏”为 例,分出初始化处理、循环处理、收尾处理之后,就可以画出如图 4.12 那样的粗略的流程图。图中把5 次循环处理看作是一个整体,当 成是一次处理(用矩形表示)。
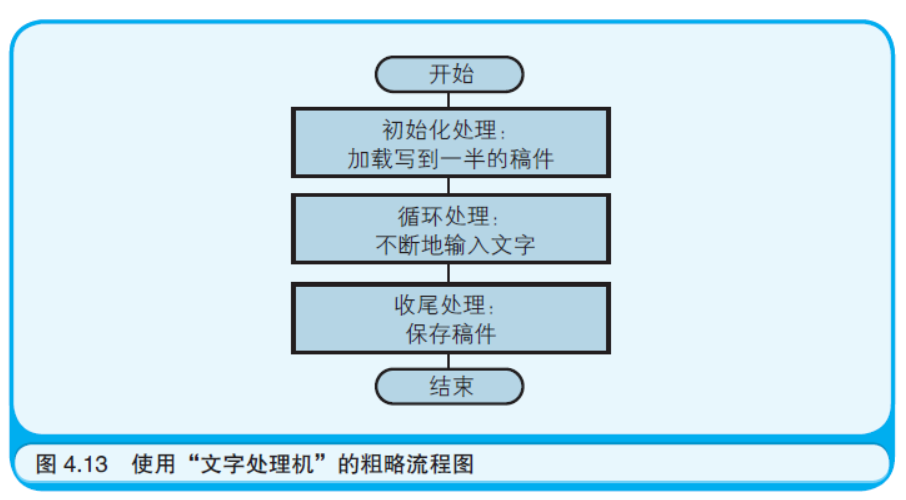
反映程序整体流程的粗略流程图还可以用来描述笔者写作本书时 的流程(如图4.13 所示)。首先,启动文字处理机,加载已经写到一半 的稿件(初始化处理)。接下来,不断地输入文字(循环处理)。最后, 保存稿件(收尾处理)。
我建议那些因为程序没有按照自己的想法来工作而烦恼的人,不 妨试试从勾画反映程序整体流程的粗略流程图下手。只要在此之上慢 慢地细化流程,就能得到详细的流程图。接下来再按照流程图所示的 流程埋头编写程序就轻松了。
- 4.6 特殊的程序流程——中断处理
最后,稍微介绍一下两种特殊的程序流程——中断处理和事件驱 动(Event Driven)。首先说明中断处理。
中断处理是指计算机使程序的流程突然跳转到程序中的特定地方, 这样的地方被称为中断处理例程(Routine)或是中断处理程序 (Handler),而这种跳转是通过CPU 所具备的硬件功能实现的。人们通 常把中断处理比作是接听电话。假设诸位都正坐在书桌前处理文件, 这时突然来电话了,诸位就不得不停下手头的工作去接电话,接完电 话再回到之前的工作。像这样由于外部的原因使正常的流程中断,中 断后再返回到之前流程的过程就是中断处理流程。
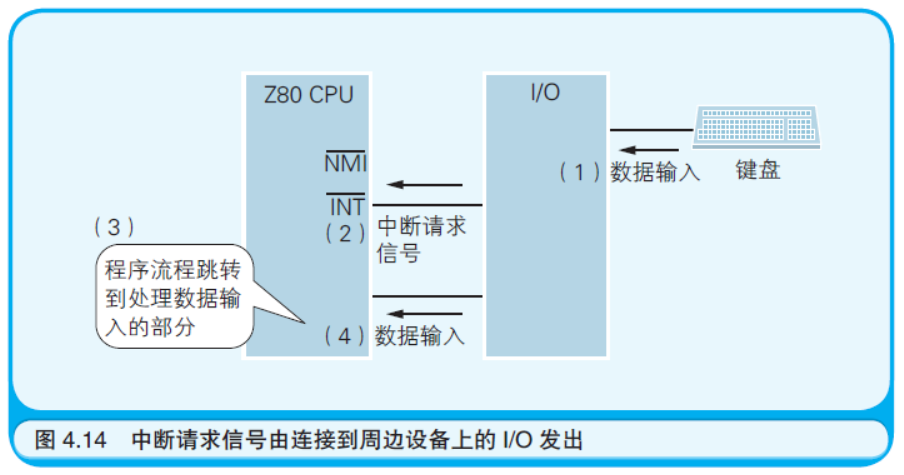
在第2 章微型计算机的电路图中已经展示过,在Z80 CPU 中有INT 和 NMI 两个引脚, 它们可以接收从I/O 设备发出的中断请求信号(INT 引脚用于处理一般的中断请求。NMI 引脚则用于即使CPU 屏蔽了中断, 也可在执行中的指令结束后立刻响应中断请求的情况)。 以硬件形式连接到CPU 上的I/O 模块会发出中断请求信号,CPU根据该信号执行相应的中断处理程序。 在诸位使用的个人计算机上,中断请求信号是由连接到周边设备上的I/O 模块发出的。 例如每当用户按下键盘上的按键,键盘上的I/O 模块就会把中断请求信号发送给CPU。 CPU 通过这种方式就可以知道有按键被按下,于是就会从I/O设备读入数据(如图4.14 所示)。 CPU 并不会时刻监控键盘是否有按键被按下。
中断处理以从硬件发出的请求为条件,使程序的流程产生分支, 因此可以说它是一种特殊的条件分支。可是,在诸位编写的程序中并 不需要编写有关中断处理的代码。因为处理中断请求的程序,或是内 置于被烧录在计算机ROM 中的BIOS 系统(Basic Input Output System, 基本输入输出系统)中,或是内置于Windows 等操作系统中。诸位只 需要先记住以下两点即可:计算机具有硬件上处理中断的能力;中断一 词的英文是Interrupt。
- 4.7 特殊的程序流程——事件驱动
程序员们经常用事件驱动的方式编写那些工作在GUI(Graphical User Inteface,图形用户界面)环境中的应用程序,例如Windows 操作 系统中的应用程序。这听起来好像挺复杂的,但其实如果把事件驱动 想象成是两个程序在对话,理解起来就简单了。
下面看一个实际的例子吧。代码清单4.5 中列出了一段用C 语言编 写的Windows 应用程序, 这里只列出了程序的骨架。在程序中有 WinMain() 和WndProc() 两个函数(代码块)。WinMain() 是在程序启动 时被调用的主例程(Main Routine)。而WndProc() 并不会被诸位所编写 的程序本身调用,Windows 操作系统才是WndProc() 的调用者。这种 机制就使得Windows 和诸位所编写的应用程序这两个程序之间可以进 行对话。
代码清单4.5 用C 语言编写的Windows 应用程序的骨架
/* 主例程 */
int APIENTRY WinMain(HINSTANCE hInst, HINSTANCE hPrevInst, LPSTR lpCmdLine, int nCmdShow){
…
}
/* 窗口过程 */
LRESULT CALLBACK WndProc(HWND hWnd, UINT msg, WPARAM wParam, LPARAM lParam){
…
}
通常把用户在应用程序中点击鼠标或者敲击键盘这样的操作称作 “事件”(Event)。负责检测事件的是Windows。Windows 通过调用应 用程序的WndProc() 函数通知应用程序事件的发生。而应用程序则根 据事件的类型做出相应的处理。这种机制就是事件驱动。可以说事件 驱动也是一种特殊的条件分支,它以从Windows 送来的通知为条件, 根据通知的内容决定程序下一步的流程。
要实现事件驱动,就必须把应用程序中的WndProc() 函数(称为窗 口过程,Window Procedure)的起始内存地址告诉Windows。这一步将 在应用程序WinMain() 中作为初始化处理被执行。
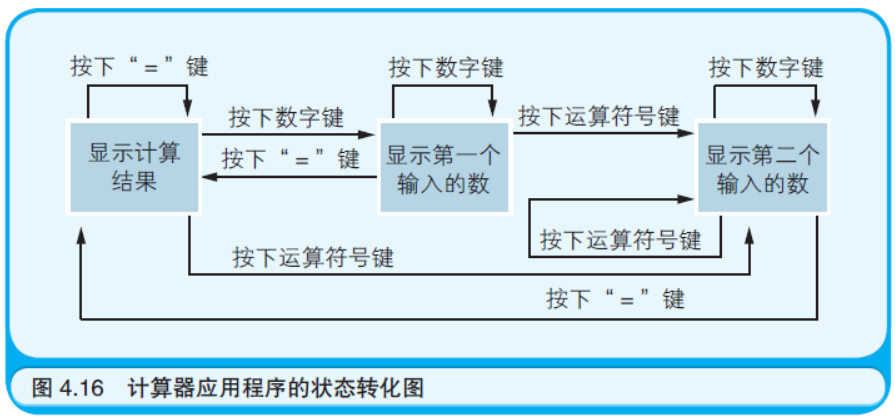
事件驱动是一种适用于GUI 环境的编程风格,在这种环境中用户 可以通过鼠标和键盘来操作应用程序。虽然事件驱动的流程也可以用 流程图表示,但是由于要排列很多的菱形符号(表示条件分支),画起 来会很复杂。所以下面介绍便于表示事件驱动的“状态转化图”。状态 转化图中有多个状态,反映了由于某种原因从某个状态转化到另一个 状态的流程。工作在GUI 环境中的程序,其显示在画面上的窗口就有若 干个状态。
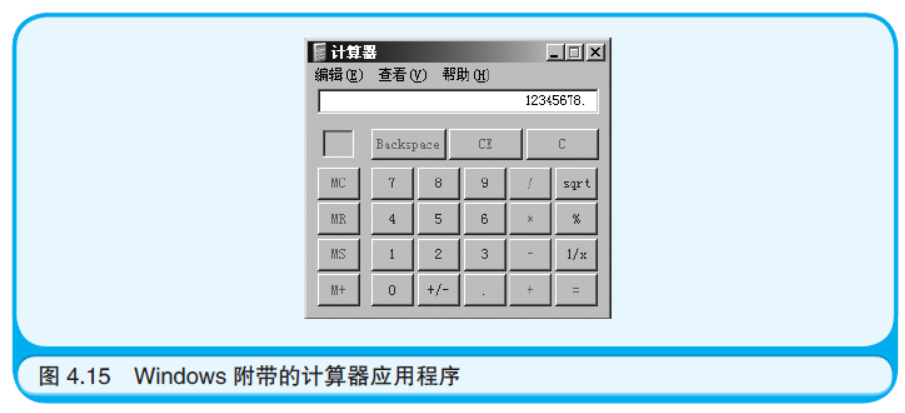
例如,如图4.15 所示的计算器应用程序就可以看作包含三个 状态:“显示计算结果”“显示第一个输入的数”以及“显示第二个输入的 数”。随着用户按下不同种类的按键,状态也会发生转变。在状态转化图 中,在矩形中写上状态的名称,用箭头表示状态转化的方向,并且在箭 头上标注引起状态转化的原因(事件)(如图4.16 所示)。
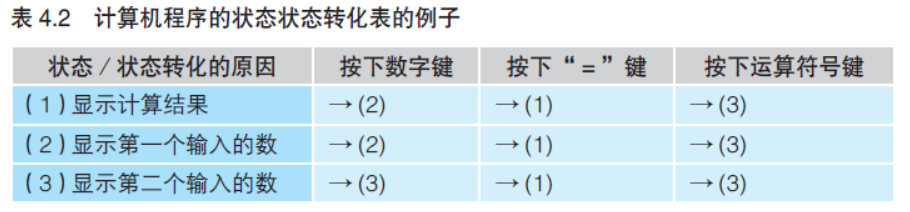
对于那些觉得画图很麻烦的人,笔者推荐使用“状态转化表”(如 表4.2 所示)。因为制表的话,用Microsoft Excel 等表格软件就可以完 成,修改起来也要比图方便。在状态转化表中,行标题是带有编号的 状态,列标题是状态转化的原因,而单元格中是目标状态的编号。
☆ ☆ ☆
也许读完中断处理和事件驱动的这两节,诸位会觉得稍微有些混 乱,但是程序的流程还是只有顺序执行、条件分支和循环这三种,这 一点是没有改变的。其中的顺序执行是最基本的程序流程,这是因为 CPU 中的PC 寄存器的值会自动更新。条件分支和循环,在高级语言 中用程序块表示,在机器语言和汇编语言中用跳转指令表示,在硬件 上是通过把PC 寄存器的值设为要跳转到的目的地的内存地址来实现。 只要能充分理解这些概念就OK 了。
在接下来的第5 章,笔者将更加详细地介绍在本章略有涉及的算法。敬请期待!
第 5 章 与算法成为好朋友的七个要点
- 热身问答
初级问题:Algorithm 翻译成中文是什么?
中级问题:辗转相除法是用于计算什么的算法?
高级问题:程序中的“哨兵”指的是什么?
- 答案
初级问题: Algorithm 翻译成中文是“算法”。
中级问题: 是用于计算最大公约数的算法。
高级问题:“ 哨兵”指的是一种含有特殊值的数据,可用于标识数据的结尾等。
- 解释
初级问题: 算法(Algorithm)一词的含义,不仅能在计算机术语辞典上查到,就是用普通的英汉辞典也能查到。
中级问题: 最大公约数指的是两个整数的公共约数中最大的数。使用辗转相除法,就可以通过机械的步骤求出最大公约数。
高级问题: 字符串的末尾用0 表示,链表的末尾用-1 表示,像这种特殊的数据就是哨兵。 在本章中,我们将展示如何在“线性搜索”算法中灵活地应用哨兵。
- 本章重点
程序是用来在计算机上实现现实世界中的业务和 娱乐活动的。为了达到这个目的,程序员们需要结合 计算机的特性,用程序来表示现实世界中对问题的处理步骤,即处理 流程。在绝大多数情况下,为了达到某个目的需要进行若干步处理。 例如为了达到“计算出两个数相加的结果”这个目的,就需要依次完成 以下三个步骤,即“输入数值”“执行加法运算”“展示结果”。像这样 的处理步骤,就被称为算法。
在算法中,有表示程序整体大流程的算法,也有表示程序局部小 流程的算法。在第4 章已经讲解过了表示大流程的算法。那么本章的 重点就是表示小流程的算法。
5.1 算法是程序设计的“熟语”
5.2 要点1:算法中解决问题的步骤是明确且有限的
5.3 要点2:计算机不靠直觉而是机械地解决问题
5.4 要点3:了解并应用典型算法
主要的典型算法
| 名称 | 用途 |
|---|---|
| 辗转相除法 | 求解最大公约数 |
| 埃拉托斯特尼筛法 | 判定素数 |
| 顺序查找 | 检索数据 |
| 二分查找 | 检索数据 |
| 哈希查找 | 检索数据 |
| 冒泡排序 | 数据排序 |
| 快速排序 | 数据排序 |
5.5 要点4:利用计算机的处理速度
在算法技巧中有个著名的技巧叫作“哨兵”。这个技巧多用在线性搜索(从若干个数据中查找目标数据)等算法中。 线性搜索的基本过程是将若干个数据从头到尾,依次逐个比对,直到找到目标数据。
下面还是通过例题来思考吧。假设有100 个箱子,里面分别装有一个写有任意数字的纸条, 箱子上面标有1~100 的序号。现在要从这100 个箱子当中查找是否有箱子装有写着要查找数字的纸条。
首先看看不使用哨兵的方法。从第一个箱子开始依次检查每个箱子中的纸条。每检查完一个纸条, 还要再检查箱子的编号(用变量N表示),并进一步确认编号是否已超过最后一个编号了。 这个过程用流程图表示后如图5.6 所示。
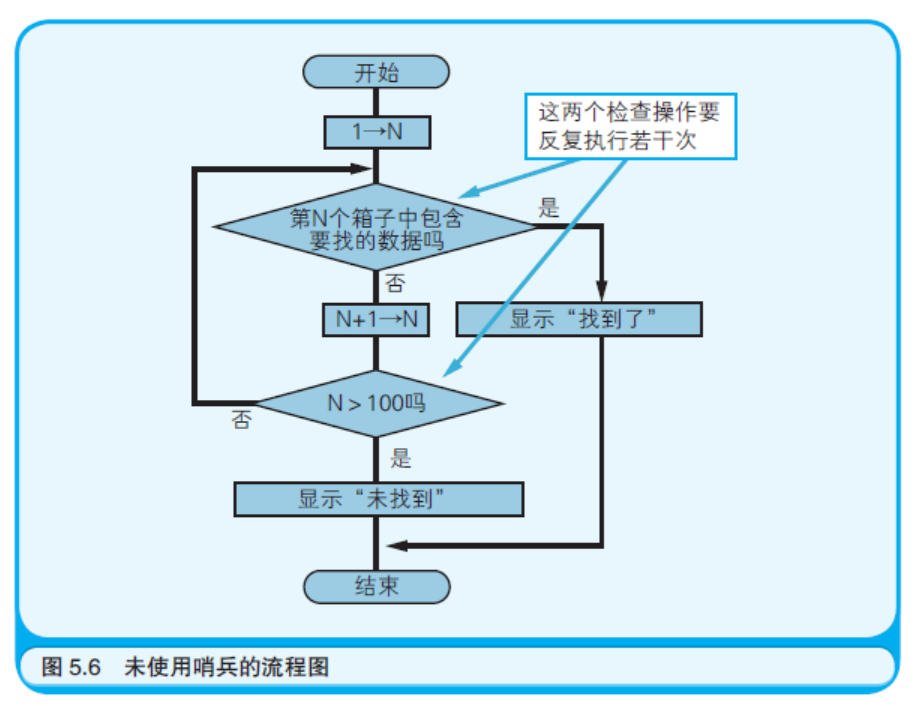
图5.6 所示的过程,虽然看起来似乎没什么问题,但是实际上含有不必要的处理——每回都要检查箱子的编号有没有到100。 为了消除这种不必要的处理,于是添加了一个101 号箱子,其中预先放入的纸条上写有正要查找的数字。 这种数据就被称为“哨兵”。通过放入哨兵,就一定能找到要找的数据了。 找到要找的数据后,如果该箱子的编号还没有到101 就意味着找到了实际的数据; 如果该箱子的编号是101,则意味着找到的是哨兵,而没有找到实际的数据。 需要多次反复检查的就只剩下“第N 个箱子中包含要找的数字吗?”这一点了, 程序的执行时间也因此大幅度地缩减了。
当笔者第一次得知哨兵的作用时,对其巧妙性感到惊叹,兴奋异常。 有些读者会感到“不太明白巧妙在哪里”,那么就讲一个故事来解释哨兵的概念吧。 假设某个漆黑的夜晚,诸位在在海岸的悬崖边上玩一个游戏(请勿亲身尝试)。 诸位站在距悬崖边缘100 米的地方,地上每隔1 米就任意放1 件物品。请找出这些物品中有没有苹果。
诸位每前进1 米就要捡起地上的物品,检查是否拿到了苹果,同时还要检查有没有到达悬崖的边缘(不检查的话就有可能掉到海里)。 也就是说要对这两种检查反复若干次。
使用了哨兵以后,就要先把起点挪到距悬崖边缘101 米的地方,再在悬崖的边缘放置一个苹果。 这个苹果就是哨兵。通过放置哨兵,诸位就一定能找到苹果了。每前进1 米时只需检查捡到的物品是不是苹果就可以了。 发现是苹果以后,只需站在原地再检查一步开外的情况。如果还没有到达悬崖边缘,就意味着找到了真正要找的苹果。 已经达到了悬崖边缘,则说明现在手中的苹果是哨兵,而没有找到真正要找的苹果。
5.6 要点5:使用编程技巧提升程序执行速度
5.7 要点6:找出数字间的规律
5.8 要点7:先在纸上考虑算法
第 6 章 与数据结构成为好朋友的七个要点
- 热身问答
初级问题:程序中的变量是指什么?
中级问题:把若干个数据沿直线排列起来的数据结构叫作什么?
高级问题:栈和队列的区别是什么?
- 答案
初级问题: 变量是数据的容器。
中级问题: 叫作“数组”。
高级问题: 栈中数据的存取形式是LIFO ;队列中数据的存取形式是FIFO。
- 解释
初级问题: 变量中所存储的数据是可以改变的。变量的实质是按照变量所存储数据的大小被分配到的一块内存空间。
中级问题: 使用了数组就可以高效地处理大量的数据。数组的实质是连续分配的一块特定大小的内存空间。
高级问题: LIFO(Last In First Out,后进先出)表示优先读取后存入的数据; FIFO(First In First Out,先进先出)表示优先读取先存入的数据。本章将会详细地讲解栈和队列的结构。
- 本章重点
在第5 章中笔者曾经这样介绍过算法:程序是用来 在计算机上实现现实世界中的业务和娱乐活动的,为 了达到这个目的,程序员们需要结合计算机的特性,用程序来表示现 实世界中对问题的处理步骤,即处理流程。本章的主题是数据结构, 也就是如何结合计算机的特性,用程序来表示现实世界中的数据结构。
程序员有必要把算法(处理问题的步骤)和数据结构(作为处理对 象的数据的排列方式)两者放到一起考虑。选用的算法和数据结构两者 要相互匹配这一点很重要。本章会依次讲解以下3 点:数据结构的基础、 最好先记忆下来的典型数据结构以及如何用程序实现典型的数据结构。 范例代码全部由适合于学习算法和数据结构的C 语言编写。为了让即 便不懂C 语言的读者也能读懂,笔者会采取简单易懂的说明,所以请 诸位不要担心。另外,为了易于理解,文中只展示了程序中的核心片段, 省略了错误处理等环节,这一点还要请诸位谅解。
6.1 要点1:了解内存和变量的关系
6.2 要点2:了解作为数据结构基础的数组
6.3 要点3:了解数组的应用——作为典型算法的实现方式
6.4 要点4:了解并掌握典型数据结构的类型和概念
表6.1 主要的典型数据结构
名称 数据结构的特征
栈 把数据像小山一样堆积起来
队列 把数据排成一队
链表 可以任意地改变数据的排列顺序
二叉树 把数据分为两路排列
6.5 要点5:了解栈和队列的实现方法
6.6 要点6:了解结构体的组成
6.7 要点7:了解链表和二叉树的实现方法
第 7 章 成为会使用面向对象编程的程序员吧
- 热身问答
初级问题:Object 翻译成中文是什么?
中级问题:OOP 是什么的缩略语?
高级问题:哪种编程语言在C 语言的基础上增加了对OOP 的支持?
- 答案
初级问题: Object 翻译成中文是“对象”。
中级问题: OOP 是Object Oriented Programming(面向对象编程)的缩略语。
高级问题: C++ 语言。
- 解释
初级问题: 对象(Object)是表示事物的抽象名词。
中级问题: 面向对象也可以简称为OO(Object Oriented)。
高级问题: ++ 是表示自增(每次只将变量的值增加1)的C 语言运算符。之所以被命名为C++, 是因为C++ 在C 语言的基础上增加了面向对象的机制这一点。另外,将C++ 进一步改良的编程语言就是Java 和C# 语言。
- 本章重点
在本章笔者想让诸位掌握的是有关面向对象编程 的概念。理解面向对象编程有着各种各样的方法,程 序员们对它的观点也会因人而异。本章会将笔者至今为止遇到过的多 名程序员的观点综合起来,对面向对象编程进行介绍。哪种观点才是 正确的呢?这并不重要,重要的是把各个角度的观点整合起来,而后 形成适合自己的理解方法。在读完本章后,请诸位一定要和朋友或是 前辈就什么是面向对象编程展开讨论。
7.1 面向对象编程
7.2 对OOP 的多种理解方法
7.3 观点1 :面向对象编程通过把组件拼装到一起构建程序
7.4 观点2 :面向对象编程能够提升程序的开发效率和可维护性
7.5 观点3 :面向对象编程是适用于大型程序的开发方法
7.6 观点4 :面向对象编程就是在为现实世界建模
7.7 观点5 :面向对象编程可以借助UML 设计程序
7.8 观点6 :面向对象编程通过在对象间传递消息驱动程序
7.9 观点7 :在面向对象编程中使用继承、封装和多态
7.10 类和对象的区别
7.11 类有三种使用方法
而使用类的程序员可以通过三种方法使用类,关于这一点诸位要有所了解。这三种方法分别是:
- 仅调用类所持有的个别成员(函数和变量);
- 在类的定义中包含其他的类(这种方法被称作组合);
- 通过继承已存在的类定义出新的类。应该使用哪种方法是由目标类的性质以及程序员的目的决定的。
7.12 在Java和.NET 中有关OOP 的知识不能少
第 8 章 一用就会的数据库
- 热身问答
初级问题:数据库术语中的“表”是什么意思?
中级问题:DBMS 是什么的简称?
高级问题:键和索引的区别是什么?
- 答案
初级问题: 表(Table)就是被整理成表格形式的数据。
中级问题: DBMS 是Database Management System(数据库管理系统)的简称。
高级问题: 键用于设定表和表之间的关系(Relationship),而索引是提升数据检索速度的机制。
- 解释
初级问题: 一张表由若干个列和行构成。列也被称为字段(Field),行也被称为记录(Record)。
中级问题: 市面上的DBMS 有SQL Server、Oracle、DB2 等。无论是哪种DBMS 都可以用基本相同的SQL 语句操作。
高级问题: 其上每个值都能够唯一标识一条记录的字段称为主键。 为了在表和表之间建立关系而在表中添加的、其他表主键的字段称为外键。而索引是与键无关的机制。
- 本章重点
前面的章节讲解的是计算机的构造和程序设计。 而本章一改之前的主题,来讲一讲数据库。像DBMS、 关系型数据库、SQL( Structured Query Language,结构化查询语言)、 事务(Transaction)之类的数据库术语,想必诸位都有所耳闻吧。可 是应该也有很多人觉得自己好像是明白了这些术语的意思,实际上却 并没有真正地理解。不仅是数据库,其他计算机技术也一样,不实际 地应用,就不能充分掌握。 本章首先介绍数据库的概况,然后通过文字的描述,请诸位体验 一下编写简单的数据库应用程序的过程。这样就不但能理解数据库术 语的含义,而且还能灵活应用这些知识了。还有一点请诸位明白,在 编写数据库应用程序时,可以采用各种各样的方法,而本章所介绍的 方法仅仅是其中的一种。
8.1 数据库是数据的基地
8.2 数据文件、DBMS 和数据库应用程序
8.3 设计数据库
8.4 通过拆表和整理数据实现规范化
8.5 用主键和外键在表间建立关系
8.6 索引能够提升数据的检索速度
8.7 设计用户界面
8.8 向DBMS发送CRUD操作的SQL 语句
8.9 使用数据对象向DBMS发送SQL 语句
8.10 事务控制也可以交给DBMS 处理
第 9 章 通过七个简单的实验理解 TCP/IP 网络
- 热身问答
初级问题:LAN 是什么的缩略语?
中级问题:TCP/IP 是什么的缩略语?
高级问题:MAC 地址是什么?
- 答案
初级问题: LAN 是Local Area Network(局域网)的缩略语。
中级问题: TCP/IP 是Transmission Control Protocol/Internet Protocol(传输控制协议和网际协议)的缩略语。
高级问题: 所谓MAC(MediaAccess Control)地址就是能够标识网卡的编号。
- 解释
初级问题: 通常把在一栋建筑物内或是一间办公室里的那种小规模网络称作LAN。 与此相对,把互联网那样的大规模网络称作WAN(Wide Area Network,广域网)。
中级问题: TCP/IP 协议族是互联网所使用的一套标准协议。TCP/IP这个名字意味着同时使用了TCP 协议和IP 协议。
高级问题: 几乎所有的网卡都会在上市前被分配一个不可变更的MAC 地址。本章将介绍查看MAC 地址的方法。
- 本章重点
诸位都经常上网吧,在网上看看网页、发发邮件 什么的,这一切似乎已经司空见惯了。通常,人们把 通过连接多台计算机所组成的、可用于交换信息的系统称为“网络” (Network)。互联网作为网络的一种,可以使我们的计算机和远在千里 之外的计算机连接在一起。而用于把全世界的计算机彼此相连的网线 已然交织成了一张网。 因为信息可以以电信号的形式在网线中传播,所以计算机彼此之间 就能够进行信息交换。但为了交换信息,还必须在发送者和接收者之间 事先确定发送方式。这种对信息发送方式的规定或约束就称为“协议” (Protocol)。小到公司内部的网络,大到互联网,TCP/IP(Transmission Control Protocol/Internet Protocol)协议族已然成为了现行的标准。 哎呀,要是再这样说下去的话,就会越来越复杂了。也许有人会 认为“只要会上网不就行了,没有必要去了解原理什么的”。但是,一 旦了解了原理,也就能更加灵活地使用网络了。那么在本章,我们就 通过一些可以随时进行的简单实验,来探索TCP/IP 网络的原理吧。
9.1 实验环境
在开始实验前,先来介绍一下作为实验对象的网络环境吧(如图 9.1 所示)。实验用的就是笔者办公室内的网络,这样的网络环境随处 可见。
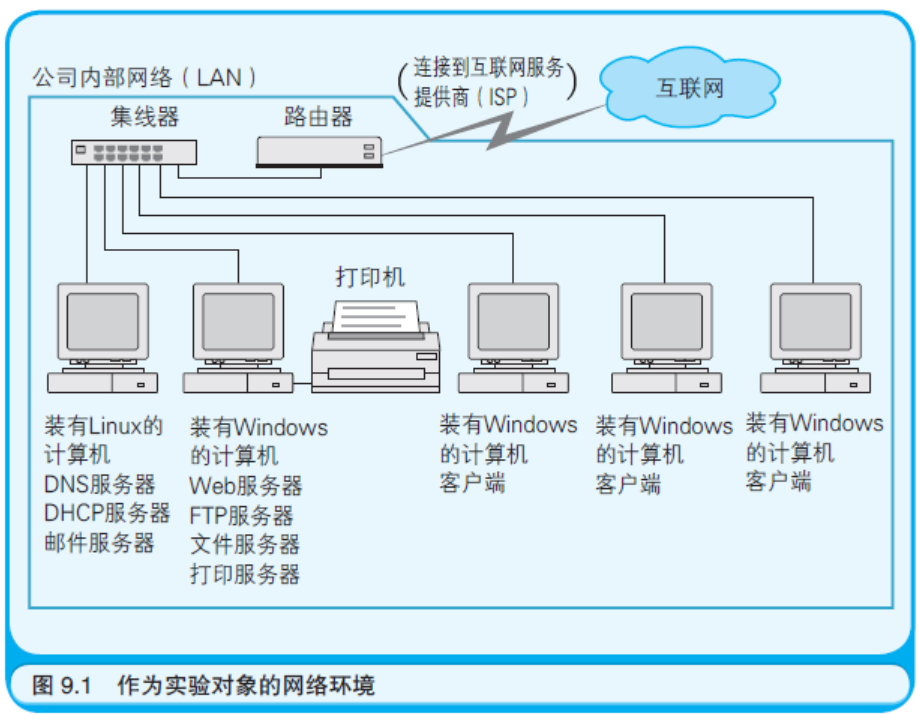
在所有网络上的计算机中,有些是服务器(Server,服务的提供 者),有些是客户端(Client,服务的利用者)。在服务器上运行的程序 为客户端提供服务。“集线器”(Hub)是负责把各台计算机的网线相互 连接在一起的集线设备。“路由器”(Router)是负责把公司内的网络和 互联网连接起来的设备。
通常把像这样部署在一间办公室内的小规模网络称作LAN ;把像 互联网那样将企业和企业联结起来的大规模网络称作WAN。路由器负 责将LAN 连接到WAN 上。路由器的一端会先连接到互联网服务提供 商的路由器上。而在服务提供商(Provider)那里,又会继续将它们的 路由器连接到其他路由器上,通过这种方式最终接入到互联网的主干 线缆上。以企业内的LAN 为一个基本单位,通过服务提供商的路由器 把它们和其他企业的LAN 互联起来,而把这种联结延伸至世界各个角 落的正就是互联网。把像LAN 这样的一张张小网都联结起来,就能织 成一张叫作互联网的大网。
9.2 实验1 :查看网卡的MAC 地址
计算机是硬件和软件的集合体,网络也不例外。那么首先,我们就从构成网络的硬件开始探索吧。 在组建公司内部的网络时,笔者购买了如下4 种硬件:
- 安装到每台计算机上的网卡(NIC,NetworkInterface Card);
- 插到网卡上的网线;
- 把网线汇集起来连接到一处的集线器;
- 用于接入到互联网的路由器。
需要注意的是这些硬件的规格只有相互匹配了才能连接在一起。网卡选择的是规格极其普通的以 太网(Ethernet)网卡。因为现在以太网已经成为了主流的选择,所以 也就无需再考虑其他方案了。网卡的种类一旦确定下来,网线、集线 器和路由器的规格也就确定了。既然硬件的规格一致了,就意味着其 中传输的电信号的形式也是一致的。这样的话无论是Linux 的计算机, 还是Windows 的计算机,它们在硬件上已经是连通的了。
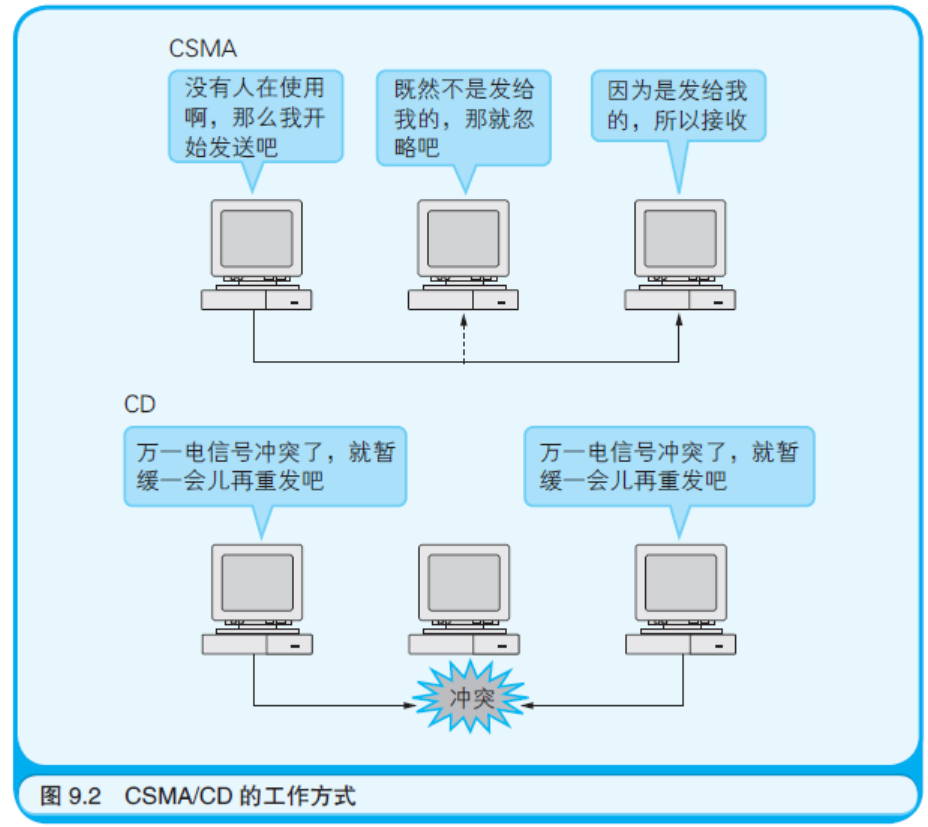
以太网使用了一种略显粗糙的方法连接LAN 内的计算机(如图9.2所示)。以太网中的每台计算机都需要先确认一件事: 在网线上有没有其他的计算机正在传输电信号,也就是说要先确保没有人在占用网络,然后才能发送自己想传输的电信号。 谁先抢到了网线的使用权,谁就先发送。万一遇到了多台计算机同时都想发送电信号的情况, 只需要让这些计算机等待一段长度随机的时间后再重新发送相同的电信号即可。 这套机制叫作CSMA/CD(Career Sense Multiple Access withCollision Detection,带冲突检测的载波监听多路访问)。 所谓载波监听(Career Sense),指的是这套机制会去监听(Sense)表示网络是否正在使用的电信号(Career)。 而多路复用(Multiple Access)指的是多个(Multiple)设备可以同时访问(Access)传输介质。 带冲突检测(withCollision Detection)则表示这套机制会去检测(Detection)因同一时刻的传输而导致的电信号冲突(Collision)。 在小规模的LAN 中,像这样略显粗躁的CSMA/CD 机制是可以正常运转的。因为CSMA/CD 归根结底也只是一种适用于LAN 的机制。
在以太网中,发送给一台计算机的电信号也可以被其他所有的计算机收到。一台计算机收到了电信号以后会先做判断, 如果是发送给自己的则选择接收,反之则选择忽略。可以用被称作MAC(MediaAccess Control)地址的编号来指定电信号的接收者。 在每一块网卡所带有的ROM(Read Only Memory,只读存储器)中,都预先烧录了一个唯一的MAC 地址。 网卡的制造厂商负责确定这个MAC 地址是什么。因为MAC 地址是由制造厂商的编号和产品编号两部分组成的, 所以世界上的每一个MAC 地址都是独一无二的。
…
9.3 实验2 :查看计算机的IP 地址
…
下面进入实验,请诸位查看各自计算机上配置的IP 地址。与之前相同,还是使用如下的命令。
ipconfig /all
C:\>ipconfig /all
Windows IP 配置
主机名 . . . . . . . . . . . . . : BaiYang-PC
主 DNS 后缀 . . . . . . . . . . . :
节点类型 . . . . . . . . . . . . : 混合
IP 路由已启用 . . . . . . . . . . : 否
WINS 代理已启用 . . . . . . . . . : 否
DNS 后缀搜索列表 . . . . . . . . : ctc
以太网适配器 以太网:
媒体状态 . . . . . . . . . . . . : 媒体已断开连接
连接特定的 DNS 后缀 . . . . . . . :
描述. . . . . . . . . . . . . . . : Intel(R) Ethernet Connection (2) I219-LM
物理地址. . . . . . . . . . . . . : C8-5B-76-A5-8D-61
DHCP 已启用 . . . . . . . . . . . : 是
自动配置已启用. . . . . . . . . . : 是
以太网适配器 VirtualBox Host-Only Network:
连接特定的 DNS 后缀 . . . . . . . :
描述. . . . . . . . . . . . . . . : VirtualBox Host-Only Ethernet Adapter
物理地址. . . . . . . . . . . . . : 0A-00-27-00-00-0A
DHCP 已启用 . . . . . . . . . . . : 否
自动配置已启用. . . . . . . . . . : 是
本地链接 IPv6 地址. . . . . . . . : fe80::350e:3a2e:501b:4a41%10(首选)
IPv4 地址 . . . . . . . . . . . . : 192.168.56.1(首选)
子网掩码 . . . . . . . . . . . . : 255.255.255.0
默认网关. . . . . . . . . . . . . :
DHCPv6 IAID . . . . . . . . . . . : 738852903
DHCPv6 客户端 DUID . . . . . . . : 00-01-00-01-26-CE-E8-B0-C8-5B-76-A5-8D-61
DNS 服务器 . . . . . . . . . . . : fec0:0:0:ffff::1%1
fec0:0:0:ffff::2%1
fec0:0:0:ffff::3%1
TCPIP 上的 NetBIOS . . . . . . . : 已启用
无线局域网适配器 本地连接* 1:
媒体状态 . . . . . . . . . . . . : 媒体已断开连接
连接特定的 DNS 后缀 . . . . . . . :
描述. . . . . . . . . . . . . . . : Microsoft Wi-Fi Direct Virtual Adapter
物理地址. . . . . . . . . . . . . : 34-F3-9A-17-87-D5
DHCP 已启用 . . . . . . . . . . . : 是
自动配置已启用. . . . . . . . . . : 是
无线局域网适配器 本地连接* 10:
媒体状态 . . . . . . . . . . . . : 媒体已断开连接
连接特定的 DNS 后缀 . . . . . . . :
描述. . . . . . . . . . . . . . . : Microsoft Wi-Fi Direct Virtual Adapter #2
物理地址. . . . . . . . . . . . . : 36-F3-9A-17-87-D4
DHCP 已启用 . . . . . . . . . . . : 否
自动配置已启用. . . . . . . . . . : 是
以太网适配器 以太网 3:
媒体状态 . . . . . . . . . . . . : 媒体已断开连接
连接特定的 DNS 后缀 . . . . . . . :
描述. . . . . . . . . . . . . . . : TAP-Windows Adapter V9
物理地址. . . . . . . . . . . . . : 00-FF-D0-31-F9-9D
DHCP 已启用 . . . . . . . . . . . : 是
自动配置已启用. . . . . . . . . . : 是
无线局域网适配器 WLAN:
连接特定的 DNS 后缀 . . . . . . . : ctc
描述. . . . . . . . . . . . . . . : Intel(R) Dual Band Wireless-AC 8260
物理地址. . . . . . . . . . . . . : 34-F3-9A-17-87-D4
DHCP 已启用 . . . . . . . . . . . : 是
自动配置已启用. . . . . . . . . . : 是
IPv6 地址 . . . . . . . . . . . . : 240e:363:47a:1401:8881:b922:f8ee:e(首选)
获得租约的时间 . . . . . . . . . : 2022年9月26日 9:48:44
租约过期的时间 . . . . . . . . . : 2022年9月26日 12:48:43
IPv6 地址 . . . . . . . . . . . . : 240e:363:47a:1401:b42d:38e0:7af1:eb6f(首选)
临时 IPv6 地址. . . . . . . . . . : 240e:363:47a:1401:2ce2:482c:19e1:2135(首选)
本地链接 IPv6 地址. . . . . . . . : fe80::b42d:38e0:7af1:eb6f%8(首选)
IPv4 地址 . . . . . . . . . . . . : 192.168.2.8(首选)
子网掩码 . . . . . . . . . . . . : 255.255.255.0
获得租约的时间 . . . . . . . . . : 2022年9月26日 9:48:46
租约过期的时间 . . . . . . . . . : 2022年9月27日 9:48:41
默认网关. . . . . . . . . . . . . : fe80::8a81:b9ff:fe22:f8ee%8
192.168.2.1
DHCP 服务器 . . . . . . . . . . . : 192.168.2.1
DHCPv6 IAID . . . . . . . . . . . : 87356314
DHCPv6 客户端 DUID . . . . . . . : 00-01-00-01-26-CE-E8-B0-C8-5B-76-A5-8D-61
DNS 服务器 . . . . . . . . . . . : fe80::8a81:b9ff:fe22:f8ee%8
192.168.2.1
TCPIP 上的 NetBIOS . . . . . . . : 已启用
C:\>
…
9.4 实验3 :了解DHCP 服务器的作用
IP 地址和子网掩码都是在软件上设置的参数。请先打开控制面板中的“网络连接”, 然后用鼠标右键单击“本地连接”并选择“属性”菜单项,接着在打开的窗口中选择“Internet 协议(TCP/IP)”, 最后单击“属性”按钮(如果您使用的是Windows 7 或8,请先打开控制面板中的“查看网络状态和任务”, 然后单击左侧边栏中的“更改适配器设置”,接着用鼠标右键单击“本地连接”并选择“属性”菜单项, 在打开的窗口中选择“Internet 协议版本 4(TCP/IPv4)”,最后单击“属性”按钮)。 这样就打开了设定IP 地址和子网掩码的对话框(如图9.5 所示)。
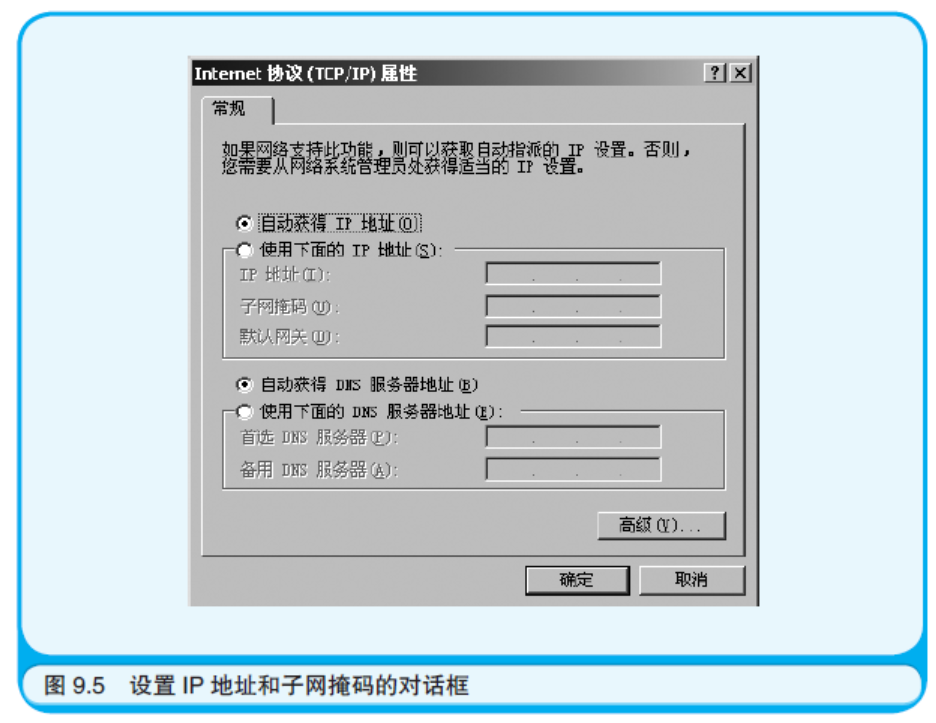
虽然在这个对话框中可以手动设置IP 地址和子网掩码,但是大多数情况下选择的还是“自动获得IP 地址”这个选项。 这个选项使得计算机在启动时会去从DHCP 服务器获取IP 地址和子网掩码,并自动地配置它们。
DHCP 的全称是Dynamic Host Configuration Protocol(动态主机设置协议)。 在笔者搭建的LAN 中,使用了一台装有Linux 的计算机充当DHCP 服务器的角色。 因为Windows 的计算机也同样支持DHCP 的协议,所以即使服务器上装的是Linux,而客户端装的是Windows,也没有关系。
DHCP 服务器上记录着可以被分配到LAN 内计算机的IP 地址范围和子网掩码的值。 作为DHCP 客户端的计算机在启动时,就可以从中知道哪些IP 地址还没有分配给其他计算机。
请再看一次图9.5。虽然文字是灰色的也许有些难以辨认,但是还 是可以看到有一个叫作“默认网关”的配置项。通常会把路由器的IP 地址设置在这里。也就是说路由器就是从LAN 通往互联网世界的入口 (Gateway)。路由器的IP 地址也可以从DHCP 服务器获取。最后再请 诸位注意一点,这里选择了“自动获得DNS 服务器地址”这一选项。 也就是说,DNS 服务器的IP 地址也可以从DHCP 服务器获取。DNS 服务器的作用将在稍后的章节中介绍。
9.5 实验4 :路由器是数据传输过程中的指路人
在分组管理下,IP 地址中的网络地址部分可以代表一个组中的全 部计算机,即一个LAN 中的计算机全体。互联网就是用路由器把多个 LAN 连接起来所形成的一张大网。从以上这两点,是不是就能慢慢看 出路由器所扮演的角色了?
路由器正如其名,就是决定数据传输路径的设备。在本实验环境 中,与LAN 内的其他计算机一样,路由器也是连接在集线器上的。因 为LAN 内采用了CSMA/CD 机制,所以所有发送出去的数据也都会 发到路由器上。当从公司内的计算机向另一家公司的计算机发送数 据时会发生什么呢?首先,一个不属于LAN 内计算机的IP 地址会被 附加到数据的发送目的地字段上。这样的数据虽然会被LAN 内的计 算机所忽略,但是不会被路由器忽略。因为路由器的工作原理就是 查看附加到数据上的IP 地址中的网络地址部分,只要发现这个数据 不是发送给LAN 内计算机的,就把它发送到LAN 外,即互联网的 世界中。
路由器虽然看起来就是个小盒子,可实际上是一台神奇的计算机。 分布在世界各地的LAN 中的路由器相互交换着信息,互联网正是由于 这种信息的交换才得以联通。这种信息被称作“路由表”,用来记录应 该把数据转发到哪里。在像互联网这样的网络中,传输路径错综复杂, 而路由器就是站在各个岔路口的指路人(如图9.6 所示)。在一台路由 器的路由表中,只会记录通往与之相邻的路由器的路径,而并不会记 录世界范围内的所有传输路径。
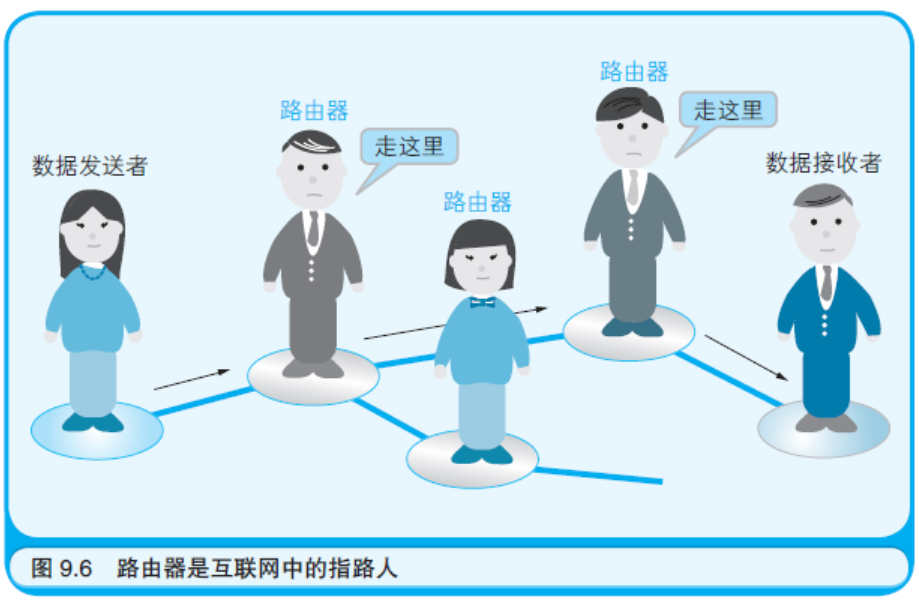
下面就实际观察一下路由表吧。为此需要在命令提示符窗口中执行如下命令(执行结果如图9.7 所示)。
route print
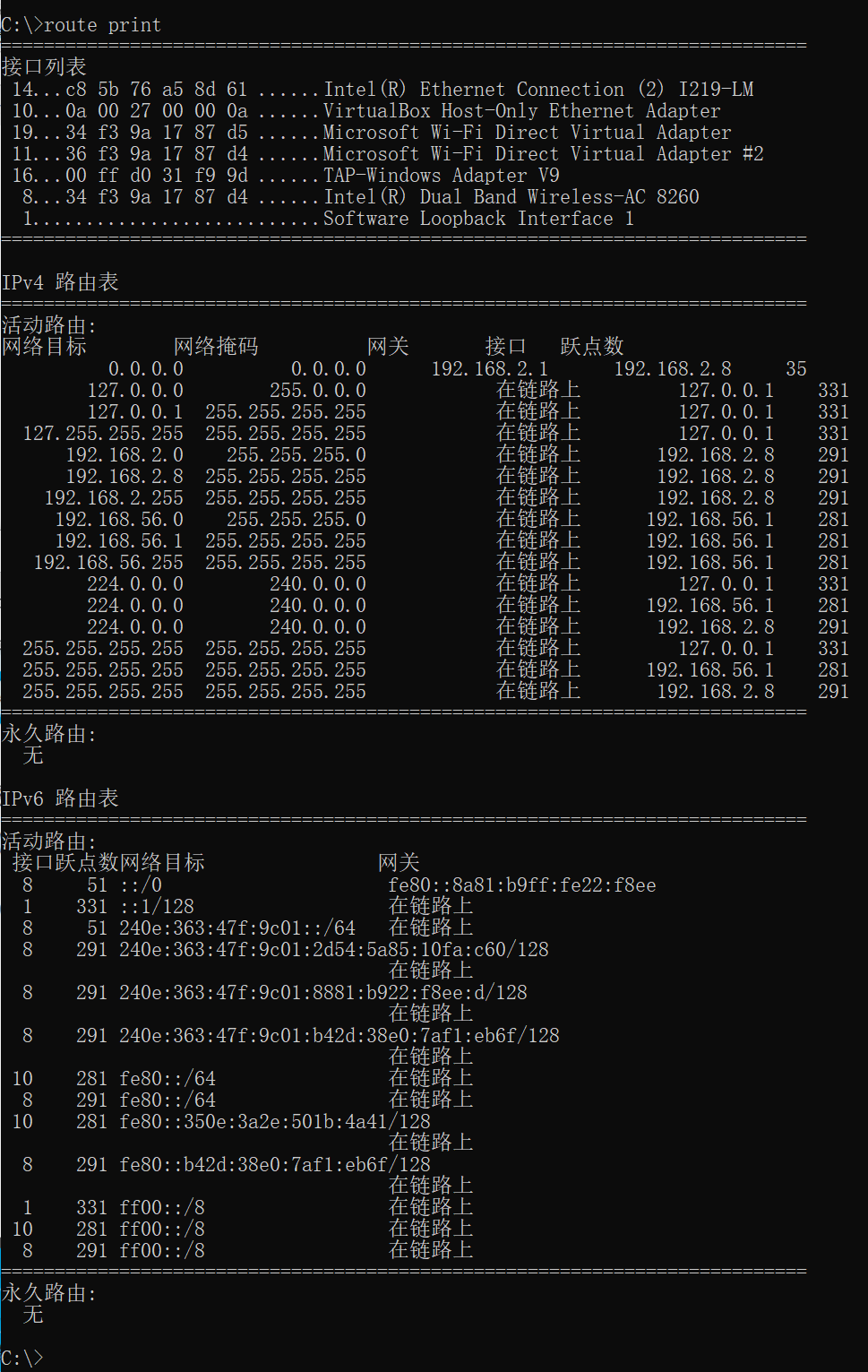
C:\>route print
===========================================================================
接口列表
14...c8 5b 76 a5 8d 61 ......Intel(R) Ethernet Connection (2) I219-LM
10...0a 00 27 00 00 0a ......VirtualBox Host-Only Ethernet Adapter
19...34 f3 9a 17 87 d5 ......Microsoft Wi-Fi Direct Virtual Adapter
11...36 f3 9a 17 87 d4 ......Microsoft Wi-Fi Direct Virtual Adapter #2
16...00 ff d0 31 f9 9d ......TAP-Windows Adapter V9
8...34 f3 9a 17 87 d4 ......Intel(R) Dual Band Wireless-AC 8260
1...........................Software Loopback Interface 1
===========================================================================
IPv4 路由表
===========================================================================
活动路由:
网络目标 网络掩码 网关 接口 跃点数
0.0.0.0 0.0.0.0 192.168.2.1 192.168.2.8 35
127.0.0.0 255.0.0.0 在链路上 127.0.0.1 331
127.0.0.1 255.255.255.255 在链路上 127.0.0.1 331
127.255.255.255 255.255.255.255 在链路上 127.0.0.1 331
192.168.2.0 255.255.255.0 在链路上 192.168.2.8 291
192.168.2.8 255.255.255.255 在链路上 192.168.2.8 291
192.168.2.255 255.255.255.255 在链路上 192.168.2.8 291
192.168.56.0 255.255.255.0 在链路上 192.168.56.1 281
192.168.56.1 255.255.255.255 在链路上 192.168.56.1 281
192.168.56.255 255.255.255.255 在链路上 192.168.56.1 281
224.0.0.0 240.0.0.0 在链路上 127.0.0.1 331
224.0.0.0 240.0.0.0 在链路上 192.168.56.1 281
224.0.0.0 240.0.0.0 在链路上 192.168.2.8 291
255.255.255.255 255.255.255.255 在链路上 127.0.0.1 331
255.255.255.255 255.255.255.255 在链路上 192.168.56.1 281
255.255.255.255 255.255.255.255 在链路上 192.168.2.8 291
===========================================================================
永久路由:
无
IPv6 路由表
===========================================================================
活动路由:
接口跃点数网络目标 网关
8 51 ::/0 fe80::8a81:b9ff:fe22:f8ee
1 331 ::1/128 在链路上
8 51 240e:363:47a:1401::/64 在链路上
8 291 240e:363:47a:1401:59:7070:f1c7:f8d0/128
在链路上
8 291 240e:363:47a:1401:8881:b922:f8ee:8/128
在链路上
8 291 240e:363:47a:1401:b42d:38e0:7af1:eb6f/128
在链路上
10 281 fe80::/64 在链路上
8 291 fe80::/64 在链路上
10 281 fe80::350e:3a2e:501b:4a41/128
在链路上
8 291 fe80::b42d:38e0:7af1:eb6f/128
在链路上
1 331 ff00::/8 在链路上
10 281 ff00::/8 在链路上
8 291 ff00::/8 在链路上
===========================================================================
永久路由:
无
C:\>
路由表由5 列构成。Network Destination、Netmask、Gateway、 Interface 这四列记录着数据发送的目的地和路由器的IP 地址等信息。 Metric 这一列记录着路径的权重,这个值由某种算法决定,比如数据传 输过程中经过的路由器的数量。如果遇到有多条候选路径都可以通往 目的地的情况,路由器就会选择Metric 值较小的那条路径。在路由表 中还有如下的规则:如果数据的发送目的地就在本LAN 中,则可以直 接发送数据而无需经过路由器转发;反之如果在LAN 外(或发送目的 地的IP 地址不在路由表中),则需要经过路由器转发。细节虽然有些复 杂,但是只要了解了大体上的规则就可以了。
9.6 实验5 :查看路由器的路由过程
假设诸位正在浏览笔者目前就职的公司GrapeCity 的主页(http:// www.grapecity.com/)。GrapeCity 的Web 服务器中的数据,要经过若干 个路由器的转发才能达到诸位的计算机上。通常把这种数据经过路由 器转发的过程称为“路由”(Routing)。
在命令提示符窗口中执行tracert 命令后,就可以查看路由的过程 了。执行时需要在tracert 的后面指定一个主机名(或计算机名),作为 数据的发送目的地。这样看到的转发路径其实是相反的,那我们就干 脆来看一下诸位的计算机到GrapeCity 的Web 服务器的路径吧。请在 命令提示符窗口中执行如下命令(执行结果如图9.8 所示)。
tracert www.baidu.com
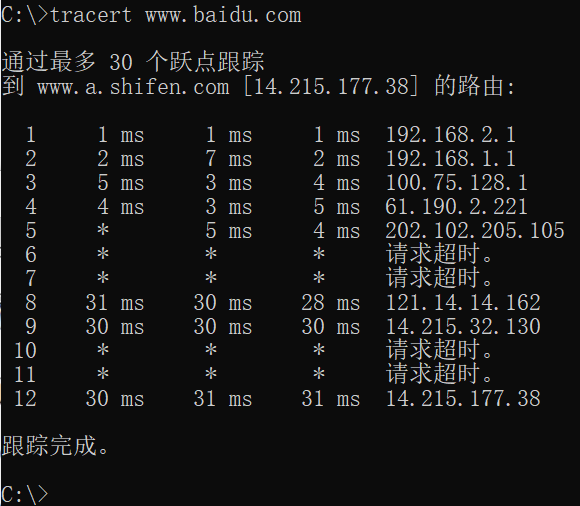
诸位难道不认为这回的实验结果非常有意思吗?左侧按照1~12的顺序列出了数据前进道路上途经的IP 地址。 第1 行的192.168.2.1是作为实验对象的LAN 内的路由器。第2 行的192.168.1.1 是笔者所在公司的路由器。 第3 行的100.75.128.1 是笔者所租用的互联网服务提供商的路由器。从第4 到第8 行,是其他服务提供商的路由器。 其中第8 行的121.14.14.162 是baidu 所租用的服务提供商的路由器。 第9 行的14.215.32.130 是baidu 的路由器。最后,第12 行的14.215.177.38 是 baidu 的Web 服务器。 可以看到,从笔者公司内的LAN 出发,通过12 次路由才终于到达了 baidu。
C:\>tracert www.baidu.com
通过最多 30 个跃点跟踪
到 www.a.shifen.com [14.215.177.39] 的路由:
1 1 ms 1 ms 1 ms 192.168.2.1
2 3 ms 2 ms 2 ms 192.168.1.1
3 9 ms 36 ms 7 ms 100.109.128.1
4 5 ms 3 ms 4 ms 61.190.194.45
5 * 4 ms 4 ms 202.102.207.93
6 * * * 请求超时。
7 * * * 请求超时。
8 26 ms * 25 ms 90.96.135.219.broad.fs.gd.dynamic.163data.com.cn [219.135.96.90]
9 27 ms 30 ms 29 ms 14.29.121.186
10 * * * 请求超时。
11 * * * 请求超时。
12 27 ms 26 ms 26 ms 14.215.177.39
跟踪完成。
C:\>
9.7 实验6 :DNS服务器可以把主机名解析成IP地址
笔者希望诸位在刚刚的实验中注意到了这样一个问题:在互联网的 世界中,本应使用IP 地址这样的数字来标识计算机才是,而刚刚却能 使用一串字符www.baidu.com 来标识Grape City 的Web 服务器。实 际上,在互联网中还存在着一种叫作DNS(Domain Name System,域 名系统)的服务器。正是该服务器为我们把www.baidu.com 这样的 域名解析为了14.215.177.38 这样的IP 地址 。
诸位的计算机都有一个主机名,每个LAN 也都有一个域名。举例 来说,笔者所使用的计算机的主机名是ma50j(源于这台计算机的型 号),所在的LAN 的域名是yzw.co.jp。把主机名和域名组合起来所形 成的ma50j.yze.co.jp,就是能够标识笔者这台计算机的一个世界范围内 独一无二的名字,这个名字与IP 地址的作用是等价的。通常把这种由 主机名和域名组合起来形成的名字称作FQDN(Fully Qualified Domain Name,完整限定域名)。
在互联网中,难以记忆的IP 地址使用起来很麻烦。于是人们就发 明出了DNS 服务器,这样只需要使用FQDN,DNS 服务器就可以自动 地把它解析为IP 地址了(这个过程叫作“域名解析”)。DNS 服务器通 常被部署在各个LAN 中,里面记录着FQDN 和IP 地址的对应关系表。 世界范围内的DNS 服务器是通过相互合作运转起来的。如果一台DNS 服务器无法解析域名,它就会去询问其他的DNS 服务器。这套流程是 自动进行的,诸位并不会意识到。
…
9.8 实验7 :查看IP 地址和MAC 地址的对应关系
在互联网的世界中,到处传输的都是附带了IP 地址的数据。但是 能够标识作为数据最终接收者的网卡的,还是MAC 地址。于是在计算 机中就加入了一种程序,用于实现由IP 地址到MAC 地址的转换,这 种功能被称作ARP(Address Resolution Protocol,地址解析协议)。
ARP 的工作方式很有意思。它会对LAN 中的所有计算机提问: “有谁的IP 地址是210.160.205.80 吗?有的话请把你的MAC 地址告诉 我。”通常把这种同时向所有LAN 内的计算机发送数据的过程称作“广 播”(Broadcast)。通过广播询问,如果有某台计算机回复了MAC 地 址,那么这台计算机的IP 地址和MAC 地址的对应关系也就明确了。 ARP 的工作流程也是自动进行的,诸位并不会意识到。
如果为了查询MAC 地址,每回都要进行广播询问,那么查询的效 率就会降低。于是ARP 还提供了缓存的功能,当向各个计算机都询问 完一轮之后,就会把得到的MAC 地址和IP 地址的对应关系缓存起来 (临时保存在内存中)。存起来的这些对应关系信息称作“ARP 缓存 表”。只要在命令提示符窗口中执行arp -a 命令,就可以查看当前ARP 缓存表中的内容。那么,作为最后的实验,我们就来查看一下ARP 缓 存表吧。
arp -a
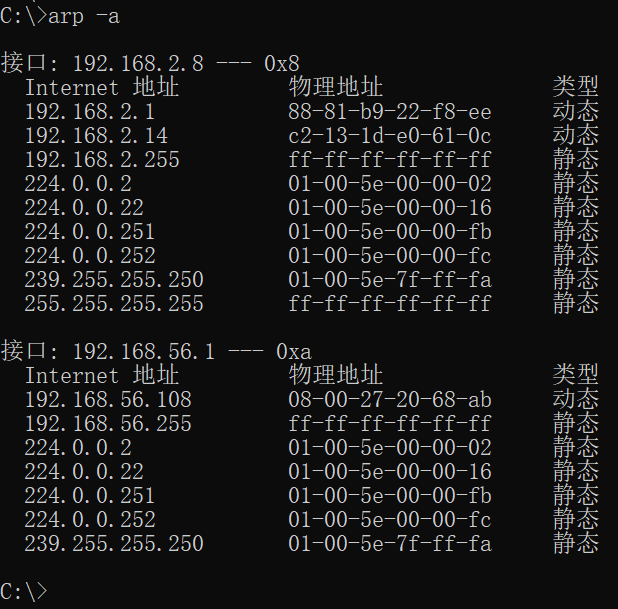
C:\>arp -a
接口: 192.168.2.8 --- 0x8
Internet 地址 物理地址 类型
192.168.2.1 88-81-b9-22-f8-ee 动态
192.168.2.255 ff-ff-ff-ff-ff-ff 静态
224.0.0.2 01-00-5e-00-00-02 静态
224.0.0.22 01-00-5e-00-00-16 静态
224.0.0.251 01-00-5e-00-00-fb 静态
224.0.0.252 01-00-5e-00-00-fc 静态
239.255.255.250 01-00-5e-7f-ff-fa 静态
255.255.255.255 ff-ff-ff-ff-ff-ff 静态
接口: 192.168.56.1 --- 0xa
Internet 地址 物理地址 类型
192.168.56.108 08-00-27-20-68-ab 动态
192.168.56.255 ff-ff-ff-ff-ff-ff 静态
224.0.0.2 01-00-5e-00-00-02 静态
224.0.0.22 01-00-5e-00-00-16 静态
224.0.0.251 01-00-5e-00-00-fb 静态
224.0.0.252 01-00-5e-00-00-fc 静态
239.255.255.250 01-00-5e-7f-ff-fa 静态
C:\>
9.9 TCP 的作用及TCP/IP 网络的层级模型
最后请允许笔者补充说明一些内容。TCP/IP 这个词表示在网络上 同时使用了TCP 和IP 这两种协议。正如前面所讲解的那样,IP 协议 用于指定数据发送目的地的IP 地址以及通过路由器转发数据。而 TCP 协议则用于通过数据发送者和接收者相互回应对方发来的确认信 号,可靠地传输数据。通常把像这样的数据传送方式称作“握手” (Handshake)(如图9.13 所示)。TCP 协议中还规定,发送者要先把原 始的大数据分割成以“包”(Packet)为单位的数据单元,然后再发送, 而接收者要把收到的包拼装在一起还原出原始数据。
…
MAC信息 | IP信息 | TCP(port)信息 | data数据信息 | 错误检查信息
硬件上发送数据的是网卡。在网卡之上是设备驱动程序(用于控制 网卡这类硬件的程序),设备驱动程序之上是实现了IP 协议的程序,IP 程序之上则是实现了TCP 协议的程序,而再往上才是应用程序,比如 Web 或电子邮件。这样就构成了一幅在硬件之上堆叠了若干个软件层 的示意图(如图9.15 所示)。TCP 协议使用被称作“TCP 端口号”的数 字识别上层的应用程序。TCP 端口号中有一些是预先定义好的,比如 Web 使用80 端口,电子邮件使用25 端口(用于发送)和110 端口(用 于接收)。
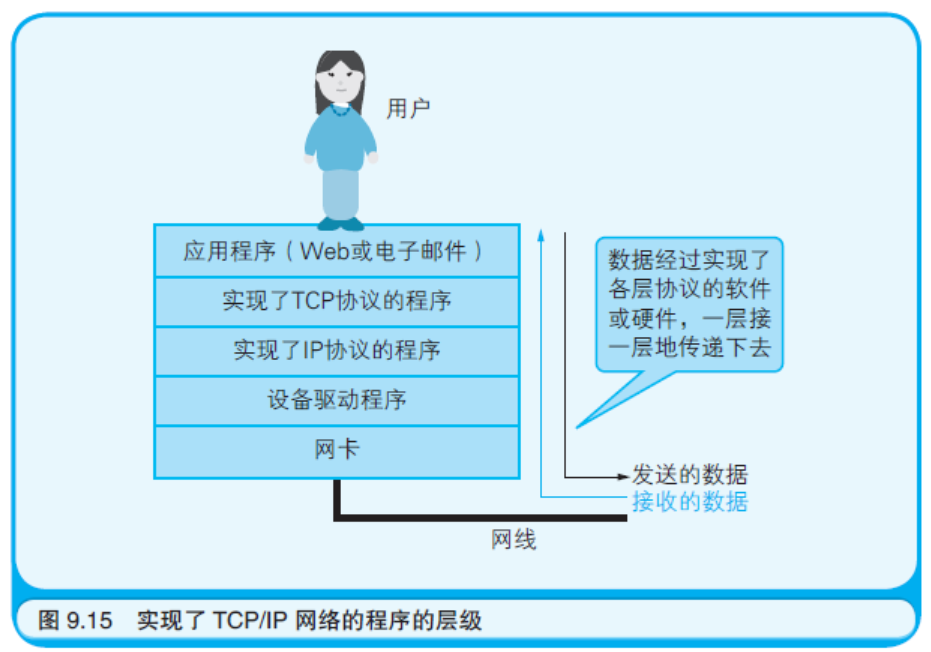
☆ ☆ ☆
怎么样?对于至今为止一直在使用却不知其所以然的网络,一旦 了解了其中的原理,就会很有成就感吧?但是,目前为止我们通过实 验所掌握的只不过是TCP/IP 网络的基础知识。如果想要了解得更加深 入,笔者建议诸位去学习有关TCP/IP 的专业书籍。只要掌握了本章所 讲解的基础知识,即便在这之前还觉得那些书难以理解,现在也应该 可以轻松地看懂了。在深入学习的阶段,如果有条件进行实验,那么 请务必动手做一做。因为通过实验学到的知识,人们往往会掌握得更 扎实、记忆得更牢靠。
在接下来的第10 章中,笔者将讲解与网络安全相关的加密技术和 身份认证机制。敬请期待!
第 10 章 试着加密数据吧
- 热身问答
初级问题:通常把还原加密过的文件这一操作叫作什么?
中级问题:在字母A 的字符编码上加上3,可以得到哪个字母?
高级问题:在数字签名中使用的信息摘要是什么?
- 答案
初级问题: 叫作解密。
中级问题: 可以得到字母D。
高级问题: 信息摘要是指从作为数字签名对象的文件整体中计算出的数值。
- 解释
初级问题: 本章将会介绍加密和解密的具体例子。
中级问题: 因为字母表中的字母编码是按字母顺序排列的,所以在字母A 的编码上加3,即A → B → C → D,所以可以得到D。
高级问题: 对比由文件整体计算出的信息摘要,可以证明文件的内容有没有被篡改。加密处理过的信息摘要就是数字签名。
- 本章重点
在前面的章节中,涉及的都是一些稍显死板的话题。
那么在本章,就喝杯咖啡稍微休息一下吧,敬请诸位放
松心情往下阅读。本章的主题是数据加密。对于公司内部的网络而言,
由于只是将员工的电脑彼此相连,可能就不太需要对其间传输的数据进
行加密。但是在互联网中,由于它联结的是全世界范围的企业和个人,
所以会面临很多需要对数据进行加密处理的情况A。举例来说,在网店购
物时用户输入的信用卡卡号,就是应该被加密传输的代表性数据。假设
卡号未经加密就被发送出去,那么就会面临卡号被同样接入互联网的某
人盗取,信用卡被其用来肆意购物的危险。因此像这种网店页面的
URL,通常都是以https:// 开头,表示数据正在使用加密的方式进行传输。
其实,大家在不知不觉中就已经都是加密技术的受益者了。
然而,如何对数据进行加密呢?这的确是个有意思的话题。在本
章中,我们将使用VBScript(Visual Basic Scripting Edition)语言实际
编写几个加密程序来展开这个话题。请诸位不要只是阅读文字内容,还
应该实际确认程序的运作。加密技术真的有趣得令人兴奋的一项技术!
10.1 先来明确一下什么是加密
10.2 错开字符编码的加密方式
10.3 密钥越长,解密越困难
…
如果仅用一位数作为密钥,那么只需要从0 到9 尝试十次就能破解密文。但是如果是用三位数的密钥, 那么就有从000 到999 的1000种可能。如果更进一步把密钥的位数增长到十位,结果会怎样呢? 那样的话,破解者就需要尝试10 的10 次方 = 100 亿次。就算使用了一秒钟可以进行100 万次尝试的计算机, 破解密文也还是需要花费100 亿÷100 万次/ 秒 = 10000 秒≈ 2.78 小时,坏人说不定就会因此放弃破解。 密钥每增长一位,破解所花费的时间就会翻10 倍。密钥再进一步增长到16 位的话,破解时间就是2.78 小时×1000000 ≈ 317 年, 从所需的时间上来看,可以说破解是不可能的。
10.4 适用于互联网的公开密钥加密技术
前面几节所讲解的加密技术都属于“对称密钥加密技术”,也称作 “秘密密钥加密技术”(如图10.7 所示)。这种加密技术的特征是在加密 和解密的过程中使用数值相同的密钥。因此,要使用这种技术,就必 须事先把密钥的值作为只有发送者和接收者才知道的秘密保护好(如图 10.7-(1) 所示)。虽然随着密钥位数的增加,破解难度也会增大,但是 事先仍不得不考虑一个问题:发送者如何才能把密钥悄悄地告诉接收者 呢?用挂号信吗?要是那样的话,假设有100 名接收者,那么发送者 就要寄出100 封挂号信,非常麻烦,而且这样也无法防止通信双方以 外的其他人知道密钥。再说寄送密钥也要花费时间。互联网的存在应 该意味着用户可以实时地与世界各地的人们交换信息。因此对称密钥 加密技术不适合在互联网中使用。
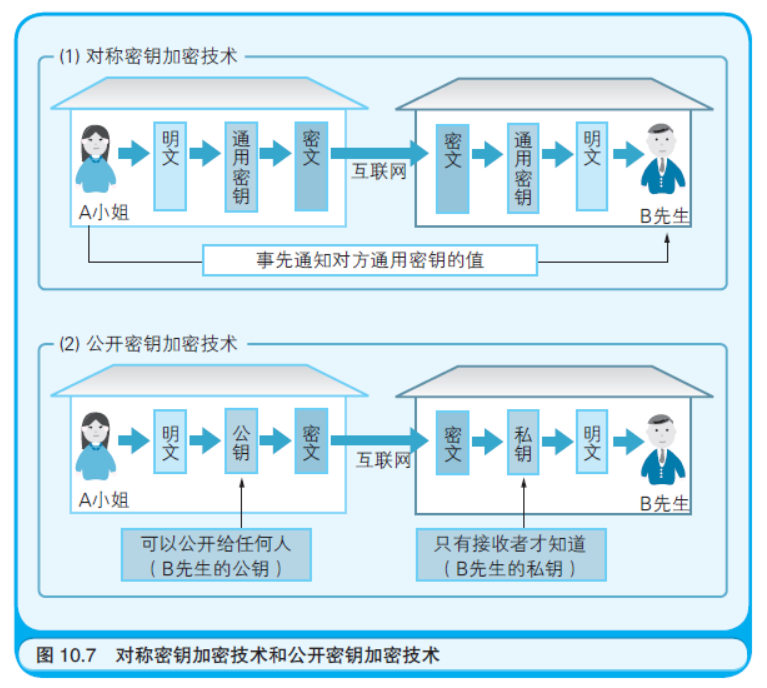
但是世界上不乏善于解决问题的能人。他们想到只要让解密时的 密钥不同于加密时的密钥,就可以克服对称密钥加密技术的缺点。 (“会有这样的技术吗?”也许诸位不禁会发出这样的疑问,稍后笔者将 展示具体的例子)。而这种加密技术就被称为“公开密钥加密技术”。
在公开密钥加密技术中,用于加密的密钥可以公开给全世界,因 此称为“公钥”,而用于解密的密钥是只有自己才知道的秘密,因此称 为“私钥”。举例来说,假设笔者的公钥是3,私钥是5(实际中会把位 数更多的两个数作为一对儿密钥使用)。笔者会通过互联网向全世界宣 布“矢泽久雄的公钥是3 哦”。这之后当诸位要向笔者发送数据的时候, 就可以用这个公钥3 加密数据了。这样就算加密后的密文被人盗取了, 只要他还不知道笔者的私钥就不可能对其解密,从而保证了数据的安 全性。而收到了密文的笔者,则可以使用只有笔者自己才知道的私钥5 对其解密(如图10.7(2) 所示)。怎么样?这个技术很棒吧!
可用于实现公开密钥加密技术的算法有若干种,这里笔者将介绍 目前广泛应用于互联网中的RSA 算法。RSA 这个名字是由三位发明者 Ronald Rivest、Adi Shamir 和Leonard Adleman 姓氏的首字母拼在一起 组成的。美国的RSA 信息安全公司对RSA 的专利权一直持有到2000年9 月20 日。 使用RSA 创建公钥和私钥的步骤如图10.8 所示。无论 是公钥还是私钥都包含着两个数值,两个数值组成的数对儿才是一个 完整的密钥。

由图10.8 的步骤可以得出:323 和11 是公钥,323 和131 是私钥, 的确是两个值都不相同的密钥。在使用这对儿密钥进行加密和解密时, 需要对每个字符执行如图10.9 所示的运算。这里参与运算的对象是字 母N(字符编码为78)。用公钥对N 进行加密得到224,用私钥对224 进行解密可使其还原为78。

乍一看会以为只要了解了RSA 算法,就可以通过公钥c = 323、 e = 11 推算出私钥c = 323,f = 131 了。但是为了求解私钥中的f,就不 得不对c 进行因子分解,分解为两个素数a、b。在本例中c 的位数很 短,而在实际应用公开密钥加密时,建议将c 的位数(用二进制数表示 时)扩充为1024 位(相当于128 字节)。要把这样的天文数字分解为两 个素数,就算计算机的速度再快,也还是要花费不可估量的时间,时 间可能长到不得不放弃解密的程度。
10.5 数字签名可以证明数据的发送者是谁
在本章的最后,先来介绍一种公开密钥加密技术的实际应用—— 数字签名。在日本的商界有盖章的习惯,而在欧美则是签字。印章和 签名都可以证明一个事实,那就是某个人承认了文件的内容是完整有 效的。而在通过网络传输的文件中,数字签名可以发挥出与印章和签 名同样的证明效果。通常可以按照下面的步骤生成数据签名。步骤中 所提及的“信息摘要”(Message Digest)可以理解为就是一个数值,通 过对构成明文的所有字符的编码进行某种运算就能得出该数值。
【文本数据的发送者】
(1)选取一段明文
例:NIKKEI
(2)计算出明文内容的信息摘要
例:(78+73+75+75+69+73)÷100 的余数 = 43
(3)用私钥对计算出的信息摘要进行加密
例:43 → 66(字母B 的编码)
(4)把步骤(3)得出的值附加到明文后面再发送给接收者
例:NIKKEIB
【文本数据的接收者】
(1)用发送者的公钥对信息摘要进行解密
例:B = 66 → 43
(2)计算出明文部分的信息摘要
例:(78+73+75+75+69+73)÷100 的余数 = 43
(3)比较在步骤(1)和(2)中求得的值,二者相同则证明接收的信息有效
例:因为两边都是43,所以信息有效
请诸位注意,这里是使用私钥进行加密、使用公钥进行解密,这 与之前的用法刚好相反(如图10.10 所示)。而且这里所使用的是信息 发送者(图10.10 中的A 小姐)的密钥对儿,而之前所使用的则是信息 接收者(B 先生)的密钥对儿。
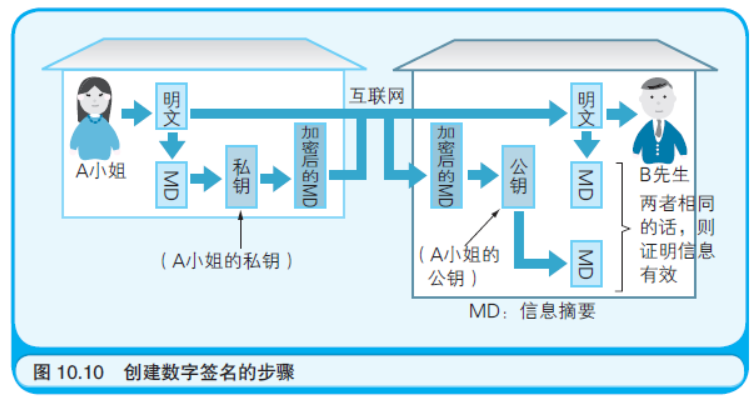
本例中信息摘要的算法是把明文中所有字母的编码加起来,然后 取总和的最后两位。而在实际中计算数字签名时,使用的是通过更加 复杂的公式计算得出的、被称作MD5(Message Digest5)的信息摘要。 由于MD5 经过了精心的设计,所以使得两段明文即使只有略微的差 异,计算后也能得出不同的信息摘要。
也许诸位会认为把文件发送者的名字,比如“矢泽久雄”这个字符 串用私钥加密,然后让对方用公钥解密也能代替印章或签字。但是如 果这样做就不算是数字签名了,因为印章或签字有两层约束。其一是 发送者承认文件的内容是完整有效的;其二是文件确实是由发送者本人 发送的。发送者用构成文件的所有字符的编码生成了信息摘要,就证 明发送者从头到尾检查了文件并承认其内容完整有效。如果接收者重 新算出的信息摘要和经过发送者加密的信息摘要匹配,就证明文件在 传输过程中没有被篡改,并且的确是发送者本人发送的。正因为数据 是用发送者的私钥加密的,接收者才能用发送者的公钥进行解密。
看到这里有个疑惑,居然公钥可以解密私钥加密的的数据,那数据的安全性从哪来? 这里所说的签名并不等同于上面所说的加解密,而是接收者验证发送者发送的信息有没有被篡改。 由于历史原因,RSA的使用过于广泛,所以才会有私钥加密的说法,其他算法并不是这样的。 最准确的说法应该是:当且仅当使用RSA算法进行签名时,签名的部分过程使用到了私钥进行加密运算。
☆ ☆ ☆
其实,绝对无法破解的加密技术也是存在的。首先密钥的位数要 与文件数据中的字符个数相同,其次每次发送文件时都需要先更换密 钥,最后为了防止密钥被盗,发送者还要亲手把密钥交给接收者。诸 位明白为什么说这样做就绝对无法破解了吗?原因在于这样做等同于 发送完全随机并且没有任何意义的数据。可是这种加密技术是不切实 际的。合理的密钥应该满足如下条件:长短适中、可以反复使用、可以 通过某种通信手段交给接收者,并且通信双方以外的其他人难以用它 来解密。公开密钥加密技术就完全满足上述条件,笔者在这里要对发 明了这项技术的工程师们表达由衷的敬意。
在接下来的第11 章中,笔者将介绍作为通用数据格式的XML。敬请期待!
第 11 章 XML 究竟是什么
热身问答
初级问题:XML 是什么的缩写?
中级问题:HTML 和XML 的区别是什么?
高级问题:在处理XML 文档的程序组件中,哪个成为了W3C 的推荐标准?
答案
初级问题: XML 是Extensible Markup Language(可扩展标记语言)的缩写。
中级问题: HTML 是用于编写网页的标记语言。XML 是用于定义任意标记语言的元语言。
高级问题: DOM(Document Object Model,文档对象模型)。
解释
初级问题: 所谓标记语言,就是可以用标签为数据赋予意义的语言。
中级问题: 通常把用于定义新语言的语言称作元语言。通过使用XML 可以定义出各种各样的新语言。
高级问题: 本章将会介绍使用了DOM 的示例程序。
本章重点
在计算机行业,没听说过XML 这个词的人恐怕不存在吧。诸位也一定都知道XML 这个词,而且也应该能深切地体会到, XML 作为一种诞生不到10 年的新技术,却不断地渗透到了计算机的各个领域。 例如,这个应用程序能够把文件保存成XML 格式;那个DBMS(数据库管理系统)的下一个版本将支持XML ; 而那个Web 服务是基于XML 实现的……
本章的主题将围绕“XML 究竟是什么”来展开。XML 其格式本身就是既简单又通用的。也正因为如此, XML 才会被扩充成各种各样的形式,应用于各种各样的场景。而且今后对XML 的利用方式也将不断地进化下去。 为了不至于对进化后的XML 形态感到吃惊,趁着现在我们就先来整理一下XML 的基础知识吧。
11.1 XML 是标记语言
11.2 XML 是可扩展的语言
11.3 XML 是元语言
…
表11.1 XML 中的主要约束

XML 的数据是纯文本格式的,也就是说只包含字符。通常把遵循 了XML 的约束编写出的文档称为“XML 文档”;把保存着XML 文 档的文件称为“XML 文件”。可以使用记事本等文本编辑器编写 XML 文件。
…
11.4 XML 可以为信息赋予意义
…
在互联网的世界中,有一个叫作W3C(World Wide Web Consortium, 万维网联盟)的机构。该机构以“W3C 推荐标准”的形式制定了一系 列标准。XML 于1996 年成为了W3C 的推荐标准(XML 1.0)。这之 后, 人们使用XML 这种元语言, 又定义出了新的网页标记语言 XHTML(Extensible Hypertext Markup Language,可扩展超文本标记语 言), 该语言也于2000 年成为了W3C 推荐标准。早晚有一天, XHTML 会取代现行的HTML(HTML 4.0),成为编写网页的主流标记 语言(原书于2003 年出版,那时还没有HTML5)。
…
11.5 XML 是通用的数据交换格式
…
XML 并不是第一个跨越了厂商或应用程序差异的通用数据交换格 式。在计算机行业,长久以来一直把CSV(Comma Separated Value, 逗号分隔值)作为通用数据交换格式沿用至今。下面就试着对比一下 XML 和CSV 吧。
与XML 一样,CSV 也是仅由字符构成的纯文本文件。一般情况
下,CSV 文件的扩展名为.csv。正如其名,在CSV 文件中,记录的是
经过,(半角逗号)分割后的信息。例如,上一节提到的购物网站中
的商品信息如果用CSV 表示的话,就如图11.10 所示。其中,字符串
要用"(半角双引号)括起来,而数字则直接书写。每一件商品的记
录(有一定意义的信息的集合)占一行。
11.6 可以为XML 标签设定命名空间
…
于是就诞生了一个W3C 推荐标准——XML 命名空间(Namespace
in XML),旨在防止这种同形异义带来的混乱。所谓命名空间,通常是
一个能代表企业或个人的字符串,用于修饰限定标签的名字。在XML
文档中,通过把“xmlns=” 命名空间的名字””作为标签的一个属性记
述,就可以为标签设定命名空间。xmlns 即XML NameSpace(命名空
间)的缩写。通常用全世界唯一的标识符作为命名空间的名称。说到互
联网世界中的唯一标识符,公司的URI 就再好不过了吧。例如,在
XML 文件中,GrapeCity 公司的矢泽创建的标签
<cat xmlns=”http://www.grapecity.com/yazawa”> 小玉</cat>
这样的话,就可以与使用了其他命名空间的
在本例中,作为<cat> 标签的命名空间设置的http://www.grapecity.com/yazawa,仅作为一个全世界唯一的标识符来使用。
就算把这个URI 输入到Web 浏览器的地址栏中,也并不会显示出相应的网页。
11.7 可以严格地定义XML 的文档结构
除了之前讲解过的“格式良好的XML 文档”,还有有一个词叫作
“有效的XML 文档”(Valid XML document)。所谓有效的XML 文档是
指在XML 文档中写有DTD(Document Type Definition,文档类型描
述)信息。前面笔者没有说明,其实完整的XML 文档包括XML 声明、
XML 实例和DTD 三个部分。所谓XML 声明,就是写在XML 文档开
头的、形如<?xml version="1.0" encoding="Shift_JIS"?> 的部分。XML
实例是文档中通过标签被标记的部分。而DTD 的作用是定义XML 实
例的结构。虽然也可以省略DTD,但是通过DTD 可以严格地检查
XML 实例的内容是否有效。
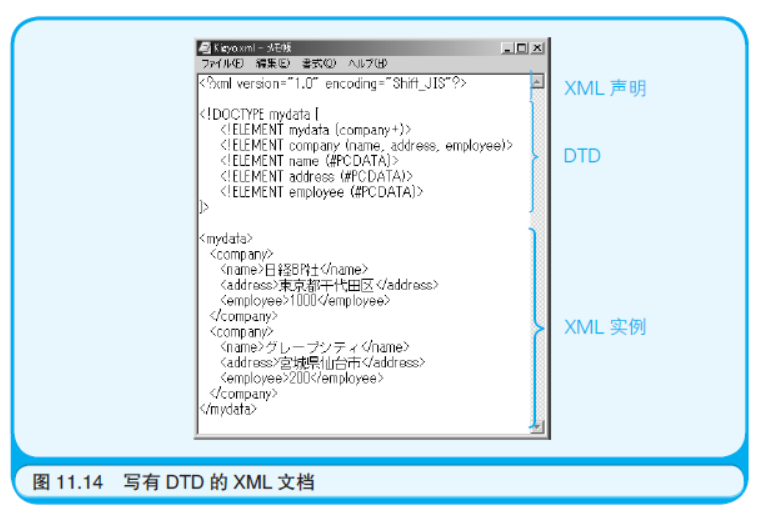
图11.14 展示了一个写有DTD 的XML 文档。请把它想成是一个描述公司名称、地址和员工数量的XML 文档。
用“<!DOCTYPE>”和“]>”括起来的部分就是DTD。DTD 定义了在<mydata> 标签中可以有一个以上的
与DTD 相同,还有一个名为XML Schema 的技术也可用于定义 XML 实例的结构。在XML 中,DTD 借用了可称得上是标记语言始祖 的SGML(Standard Generalized Markup Language,标准通用标记语言) 语言的语法。而XML Schema 是为了XML 新近研发的技术,因此它可 以对XML 文档执行更严格地检查,例如检查数据类型或数字位数等。 DTD 是1996 年发布的W3C 推荐标准,而XML Schema 发布于2001 年。今后将成为主流的是崭新的XML Schema,而不是古老的DTD。
11.8 用于解析XML 的组件
…
的确存在着用于处理XML 文档的程序组件。比如已成为W3C 标 准的DOM(Document Object Model,文档对象模型)以及由XML-dev 社区开发的SAX(Simple API for XML)。其实无论是DOM 还是SAX, 都只是组件的规范,实际的组件是由某个厂商或社区提供的。
…
11.9 XML 可用于各种各样的领域
通过使用XML,诞生了各种各样的标记语言(如表11.2 所示)。 以往的软件厂商在存储数学算式、多媒体数据等数据时,使用的都是 自家应用程序的私有格式。然而在未来,作为世界标准的XML 格式的 标记语言将成为主流。即使是现在,也已经涌现出了一批成为W3C 建 议标准的标记语言。
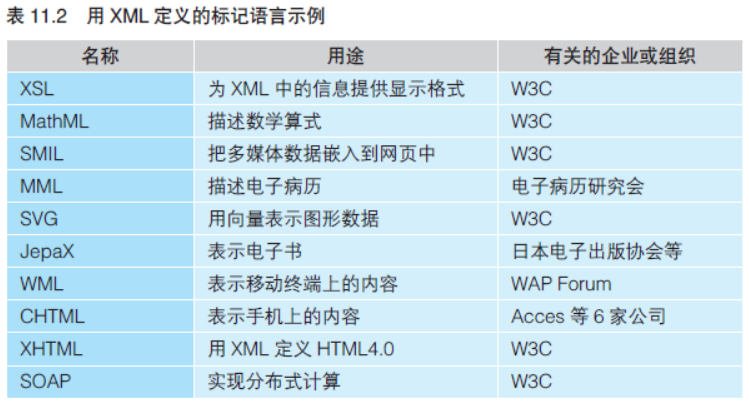
…
SOAP(Simple Object Access Protocol,简单对象访问协议)可用于 分布式计算。所谓分布式计算,就是把程序分散部署在用网络连接起 来的多台计算机上,使这些计算机相互协作,充分发挥计算机整体的 计算能力。简单地说,SOAP 就是使运行在A 公司计算机中的A 程序, 可以调用运行在B 公司计算机中的B 程序。
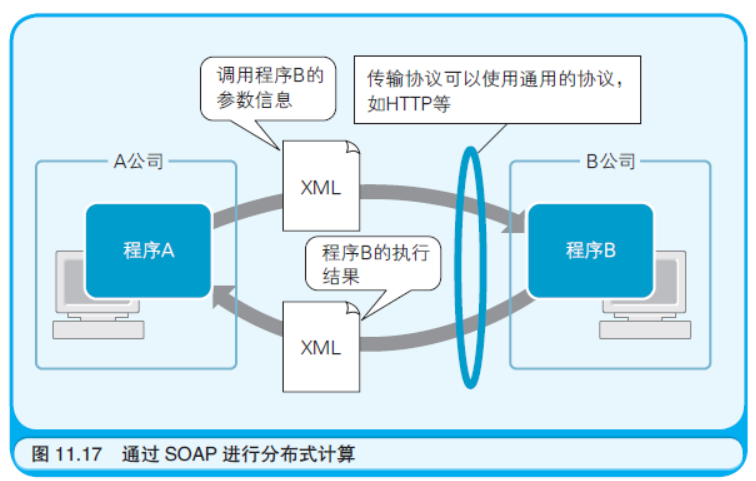
SOAP 的出现使过去的分布式计算技术变得更容易使用,也更通 用。无论是调用程序时所需的参数信息,还是程序执行后的返回结果, 都可以用通用的数据格式XML 表示(如图11.17 所示)。另一方面, SOAP 收发数据时所使用的传输协议并不固定,凡是能够收发XML 数 据的协议均可使用。一般情况下使用的是HTTP 或SMTP 协议。可以 说SOAP 的诞生使得人们可以更加轻松地构建分布式计算环境了。
☆ ☆ ☆
XML 受到了众人的瞩目,在各种各样的场景中都可以见到它的身 影,这已经是不折不扣的事实了,而且还会继续诞生新的XML 的使用 方法。但是请不要认为这等同于“今后所有的数据都应该是XML 格式 的”。因为XML 只有在充当通用数据格式时才有价值。也就是说,只 有在像互联网那样的环境中,运行在不同机器中的不同应用程序相互 联结,XML 才会大有作为。只有一台独立的计算机,或者只在一家公 司内部的话,使用XML 格式存储数据反而体现不出优势,仅仅是文件 的尺寸变大从而浪费存储空间罢了。
同样地,在分布式计算中,如果是由不同种类的机器互联组成的 系统,那么使用基于XML 的SOAP 才是有意义的。反之如果环境中的 机器和应用程序全部来自同一厂商,那么使用厂商自己定制的格式而 并非基于XML 的格式,反而可以更加快捷地处理信息。XML 是通用 的,但它不是万能的。笔者会把XML 中的X 看作是eXchangable(可 交换的)而并非是eXtensible(可扩展的),诸位赞同这种看法吗?
下一章是本书的最后一章,笔者将讲解由各种技术组合而成的计算机系统。敬请期待!
第 12 章 SE 负责监管计算机系统的构建
热身问答
初级问题:SE 是什么的缩略语?
中级问题:IT 是什么的缩略语?
高级问题:请列举一个软件开发过程的模型。
答案
初级问题: SE 是System Engineer(系统工程师)的缩略语。
中级问题: IT 是Information Technology(信息技术)的缩略语。
高级问题: 软件开发过程的模型有“瀑布模型”“原型模型”“螺旋模型”等。
解释
初级问题: 在计算机系统的开发过程中,SE 是参与所有开发阶段的工程师。
中级问题: 一提到IT,通常就意味着充分地运用计算机解决问题, 但Information Technology(信息技术)这个词中并没有包含表示计算机含义的词语。
高级问题: 本章将会详细地介绍应用瀑布模型的开发过程。
本章重点
从第1 章到第11 章,讲解的都是各种各样的计算 机技术。在作为本书最后一章的第12 章,请允许笔者 再介绍一下将这些技术组合起来构建而成的计算机系统,以及负责构 建计算机系统的SE(System Engineer,系统工程师)。本章不仅有技 术方面的内容,更会涉及商业方面的内容。对于商业而言,没有什么 可称得上是绝对正确的见解,因此本章的叙述中也多少会含有笔者的 主观想法,这一点还望诸位谅解。
“将来的目标是音乐家!”——正如以前新出道的偶像歌手都会有 这句口头禅一样,过去新入行的工程师也有一句口头禅,那就是“将来 的目标是SE !”在那时SE 给人的印象是计算机工程师的最高峰。可 是最近,想成为SE 的人似乎并没有那么多了。不善于与客户交谈,感 到项目管理之类的工作很麻烦,觉得穿着牛仔裤默默地面对计算机才 更加舒坦等原因似乎都是不想成为SE 的理由。SE 果真是那么不好的 工作吗?其实不然,SE 是有趣的、值得去做的工作。下面就介绍一下 身为SE 所需要掌握的技能以及SE 的工作内容吧。
12.1 SE 是自始至终参与系统开发过程的工程师
所谓的SE 到底是负责什么工作的人呢?《日经计算机术语辞典 2002》(日经BP 出版社)中对SE 做出了如下的解释。
SE 指的是在进行业务的信息化时,负责调查、分析业务内容,确定计算机系统的基础设计及其详细规格的技术人员。 同时SE 也负责系统开发的项目管理和软件的开发管理、维护管理工作。由于主要的工作是基础设计, 所以不同于编写程序的程序员,SE 需要具备从硬件结构、软件的构建方法乃至横跨整个业务的广泛知识以及项目管理的经验。
简单地说,SE 就是自始至终参与系统开发过程的工程师,而不是 只负责编程的程序员。所谓系统,就是“由多个要素相互发生关联,结 合而成的带有一定功能的整体”。将各种各样的硬件和软件组合起来构 建而成的系统就是计算机系统。
至今为止,有些业务依然是靠手工作业进行的,引进计算机系统 就是为了提高这类业务的效率。SE 在调查、分析完手工作业的业务内 容后,会进行把业务迁移到计算机系统的基本设计,并确定详细的规 格。SE 负责的工作是项目管理和软件开发管理,以及引进计算机系统 后的维护,而制作软件(编程)的工作则交由程序员完成。 也就是说,SE 是从构建计算机系统的最初阶段(调查分析)开始, 一直到最后的阶段(维护管理)都会参与其中的工程师。比起只参与编 写程序这一工作的程序员,SE 所参与的工作范围更加广泛。为此,SE 就必须掌握从硬件到软件再到项目管理的多种多样的技能。
12.2 SE 未必担任过程序员
12.3 系统开发过程的规范
…
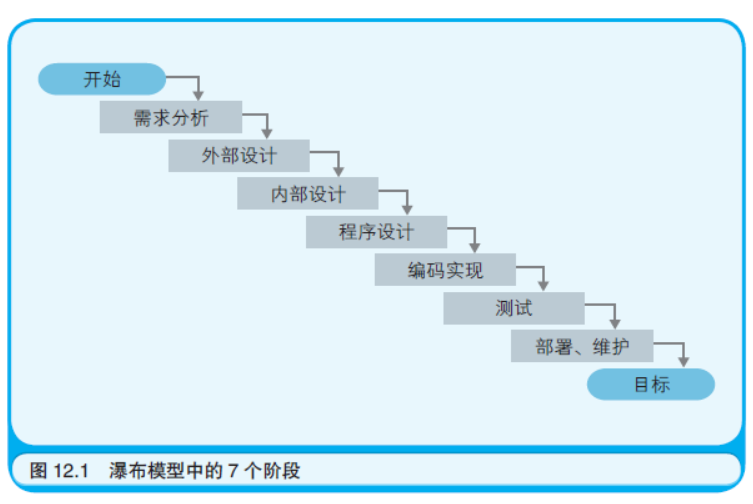
在瀑布模型中,每完成一个阶段,都要书写文档(报告)并进行审 核。进行审核时还需要召开会议,在会上由SE 为开发团队的成员、上 司以及客户讲解文档的内容。若审核通过了,就可以从上司或客户那 里得到批准,继续进入后续的开发阶段。若审核没有通过,则不能进 入后续的阶段。一旦进入了后续的阶段,就不能回退到之前的阶段。 为了避免回退到上一阶段,一是要力求完美地完成每一个阶段的工作, 二是要彻底地执行审核过程,这些就是瀑布模型的特征。这种开发过 程之所以被称为“瀑布模型”,是因为开发流程宛如瀑布,一级一级地 自上而下流动,永不后退。如图12.2 所示,开发过程就好像是开发团 队乘着小船,一边克服着一个又一个的瀑布(通过审核),一边从上流 顺流而下漂向下游。而坐在船头的人当然就是SE 了。
…
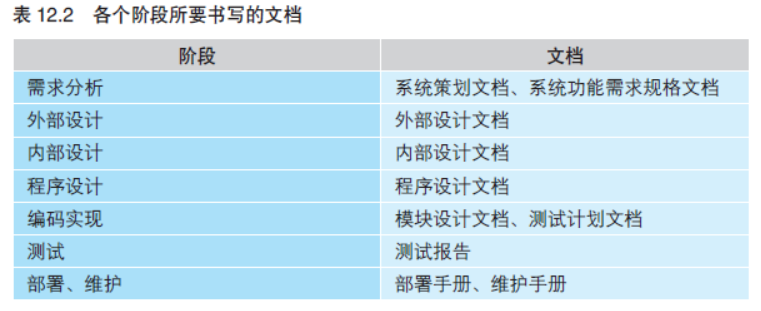
12.4 各个阶段的工作内容及文档
下面介绍瀑布模型各个阶段的工作内容及所要书写的文档的种类(如表12.2 所示)。
…
12.5 所谓设计,就是拆解
…
下面,请诸位回忆一下在第1 章讲解过的“计算机的三大原则”。
- 原则1:计算机只能够做输入、运算、输出三种操作
- 原则2:程序是指令和数据的集合
- 原则3:计算机有自己的处理方法
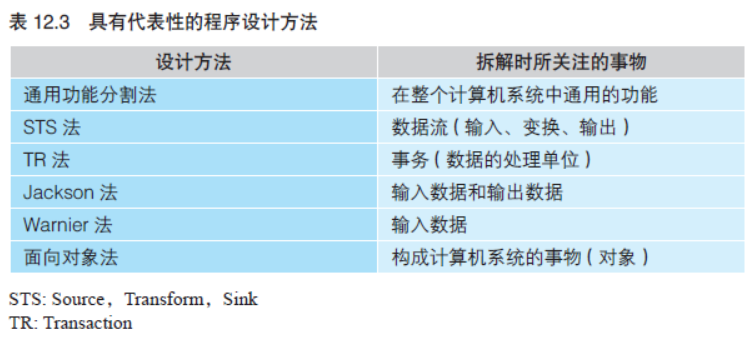
可以看到,表12.3 所示的各种设计方法,其关注点要么在输入、 运算、输出、指令、数据这几个要素的某一个上,要么在某几个的组 合上。引进计算机系统的目的是通过用计算机替代靠手工作业进行的 业务,来提升工作效率。因此在设计时,要使手工作业的业务顺应计 算机的处理方式来进行替换,这一点也值得注意。
12.6 面向对象法简化了系统维护工作
12.7 技术能力和沟通能力
正如之前讲解的那样,SE 所要具备的能力是多种多样的。这些能 力大体上可以分为两类——技术能力(Technical Skill)和沟通能力 (Communication Skill)。所谓技术能力,是指灵活运用硬件、软件、网 络、数据库等技术的能力。而所谓沟通能力,是指和他人交换信息的 能力,而且这里要求的是双向的信息交换能力。
…
12.8 IT 不等于引进计算机
12.9 计算机系统的成功与失败
12.10 大幅提升设备利用率的多机备份
…
个人计算机和打印机各1 台时,设备利用率是72%,一旦分别增 至了2 台,设备利用率就一下子飙升到了95%。如果能出示这个数据, 客户也还是能接受20 万日元的2 倍、即40 万日元的费用吧。由此看 来,身为SE,在谈话时还必须能在技术上有理有据地说服对方。
☆ ☆ ☆
在计算机行业确实有“SE 的地位比程序员的高”这种说法。那么, 所有计算机技术人员将来都必须以SE 为目标吗?就连非常热爱编程, 想当一辈子程序员也错了吗?笔者认为并不是这样的,想当一辈子程 序员也很好。但问题是若要立志成为计算机行业的专家,就不能仅仅 关注技术了。虽然又懂技术又懂计算机确实让人感到兴奋,但如果只 是这样的话,早晚有一天工作就会变得没那么有意思了。有些人在30 岁左右就会选择离开计算机行业,不是因为他们追赶不上技术前进的 步伐,而是因为他们感到工作变得无聊了。专家也好普通人也罢,只 有为社会做出了贡献才能有成就感,才会觉得工作有意义。可能有人 会觉得“这么说来,即使是程序员,只要能意识到自己也是在为社会做 贡献不就好了吗?”能这样想就对了! SE 也好,程序员也罢,所有和计 算机相关的工程师都要有这样一种意识:我们要让计算机技术服务于社 会。如果能有这样的决心,就应该能作为一生的事业和计算机愉快地 相处下去了吧。
结束语
在本书写作之前,我还写过一本叫作《程序是怎样跑起来的》的 书。该书被翻译成了韩文和中文,所以不仅是日本国内,在海外也有 很多读者。此外,该书还被很多企业用作新员工培训的辅助读物,亦 被大学用作研讨会的教材。在这里真的非常感谢诸位! 但是,作为作者,我在高兴之余也感到了深深的歉意。从诸位手 中收到的读者来信中,有一位70 岁左右的老先生这样写道:“因为是热 门图书所以买了一本,但内容太难了,理解不了。”为此我又一心一意 地撰写了本书。在本书中,将从基础中的基础开始讲起,明确地指出 知识的范围和目标,力求做到更加通俗易懂。诸位读过后感想如何 呢?若诸位能通过读者来信将您的意见或感想告知我,我将感到不胜 荣幸。
谢辞
正值本书发行之际,我要衷心感谢从策划阶段就开始关照我的日 经Software 的柳田俊彥主编、矢崎茂明记者、日经BP 出版社的高畠知 子, 以及每一位工作人员。借此机会, 我还要感谢那些在《日经 Software》连载《计算机并不难》时,为我指出讲解中的遗漏或错误, 以及来信鼓励我的诸位读者。
程序是怎样跑起来的
目录
第1章 对程序员来说CPU是什么 1
1.1 CPU的内部结构解析 3
1.2 CPU是寄存器的集合体 6
1.3 决定程序流程的程序计数器 9
1.4 条件分支和循环机制 10
1.5 函数的调用机制 13
1.6 通过地址和索引实现数组 16
1.7 CPU的处理其实很简单 17
第2章 数据是用二进制数表示的 19
2.1 用二进制数表示计算机信息的原因 21
2.2 什么是二进制数 23
2.3 移位运算和乘除运算的关系 25
2.4 便于计算机处理的“补数” 27
2.5 逻辑右移和算术右移的区别 31
2.6 掌握逻辑运算的窍门 34
COLUMN 如果是你,你会怎样介绍?——向小学生讲解CPU和二进制 38
第3章 计算机进行小数运算时出错的原因 41
3.1 将0.1累加100次也得不到10 43
3.2 用二进制数表示小数 44
3.3 计算机运算出错的原因 46
3.4 什么是浮点数 47
3.5 正则表达式和 EXCESS系统 50
3.6 在实际的程序中进行确认 52
3.7 如何避免计算机计算出错 55
3.8 二进制数和十六进制数 56
第4章 熟练使用有棱有角的内存 59
4.1 内存的物理机制很简单 61
4.2 内存的逻辑模型是楼房 65
4.3 简单的指针 67
4.4 数组是高效使用内存的基础 69
4.5 栈、队列以及环形缓冲区 71
4.6 链表使元素的追加和删除更容易 75
4.7 二叉查找树使数据搜索更有效 79
第5章 内存和磁盘的亲密关系 81
5.1 不读入内存就无法运行 83
5.2 磁盘缓存加快了磁盘访问速度 84
5.3 虚拟内存把磁盘作为部分内存来使用 85
5.4 节约内存的编程方法 88
5.5 磁盘的物理结构 93
第6章 亲自尝试压缩数据 97
6.1 文件以字节为单位保存 99
6.2 RLE 算法的机制 100
6.3 RLE 算法的缺点 101
6.4 通过莫尔斯编码来看哈夫曼算法的基础 103
6.5 用二叉树实现哈夫曼编码 105
6.6 哈夫曼算法能够大幅提升压缩比率 109
6.7 可逆压缩和非可逆压缩 110
COLUMN 如果是你,你会怎样介绍?——向沉迷游戏的中学生讲解内存和磁盘 114
第7章 程序是在何种环境中运行的 117
7.1 运行环境=操作系统+硬件 119
7.2 Windows克服了CPU以外的硬件差异 122
7.3 不同操作系统的API不同 124
7.4 FreeBSD Port帮你轻松使用源代码 125
7.5 利用虚拟机获得其他操作系统环境 127
7.6 提供相同运行环境的 Java虚拟机 128
7.7 BIOS和引导 130
第8章 从源文件到可执行文件 133
8.1 计算机只能运行本地代码 135
8.2 本地代码的内容 137
8.3 编译器负责转换源代码 139
8.4 仅靠编译是无法得到可执行文件的 141
8.5 启动及库文件 143
8.6 DLL文件及导入库 145
8.7 可执行文件运行时的必要条件 146
8.8 程序加载时会生成栈和堆 148
8.9 有点难度的Q&A 150
第9章 操作系统和应用的关系 153
9.1 操作系统功能的历史 155
9.2 要意识到操作系统的存在 157
9.3 系统调用和高级编程语言的移植性 160
9.4 操作系统和高级编程语言使硬件抽象化 161
9.5 Windows操作系统的特征 163
COLUMN 如果是你,你会怎样介绍?——向超喜欢手机的女高中生讲解操作系统的作用 170
第10章 通过汇编语言了解程序的实际构成 173
10.1 汇编语言和本地代码是一一对应的 175
10.2 通过编译器输出汇编语言的源代码 177
10.3 不会转换成本地代码的伪指令 180
10.4 汇编语言语法是“操作码+操作数” 182
10.5 最常用的mov指令 185
10.6 对栈进行push和pop 185
10.7 函数调用机制 187
10.8 函数内部的处理 189
10.9 始终确保全局变量用的内存空间 191
10.10 临时确保局部变量用的内存空间 196
10.11 循环处理的实现方法 199
10.12 条件分支的实现方法 202
10.13 了解程序运行方式的必要性 204
第11章 硬件控制方法 209
11.1 应用和硬件无关? 211
11.2 支撑硬件输入输出的IN指令和OUT指令 212
11.3 编写测试用的输入输出程序 215
11.4 外围设备的中断请求 218
11.5 用中断来实现实时处理 221
11.6 DMA可以实现短时间内传送大量数据 222
11.7 文字及图片的显示机制 224
COLUMN 如果是你,你会怎样介绍?——向邻居老奶奶说明显示器和电视机的不同 226
第12章 让计算机“思考” 229
12.1 作为“工具”的程序和为了“思考”的程序 231
12.2 用程序来表示人类的思考方式 232
12.3 用程序来表示人类的思考习惯 235
12.4 程序生成随机数的方法 237
12.5 活用记忆功能以达到更接近人类的判断 239
12.6 用程序来表示人类的思考方式 242
COLUMN 如果是你,你会怎样介绍?——向常光临的酒馆老板讲解计算机的思考机制 245
附录 让我们开始C语言之旅 247
C语言的特点 247
变量和函数 248
数据类型 249
标准函数库 250
函数调用 251
局部变量和全局变量 254
数组和循环 255
其他语法结构 256
参考资料
计算机是怎样跑起来的 web版 https://www.ituring.com.cn/book/1139
计算机是怎样跑起来的 (可参考阅读,这个就不要用了) http://www.javashuo.com/article/p-ebgzhuvv-nw.html