正文
全页面静态化缓存
关于静态化,PHP的静态化分为:纯静态和伪静态。其中纯静态又分为:局部纯静态和全部纯静态。
全页面静态化缓存,也就是将页面全部生成html静态页面,用户访问时直接访问的静态页面,而不会去走php服务器解析的流程。 此种方式,在CMS内容管理型系统中比较常见。
一种比较常用的实现方式是用输出缓存:
ob_start()
******要运行的代码*******
$content = ob_get_contents();
****将缓存内容写入html文件*****
ob_end_clean();
介绍几个关于PHP缓冲区的相关函数:
ob_start 打开输出控制缓冲(要求php开启缓存,在php配置文件php.ini文件中可以设置 output_buffering = on)
ob_get_contents 返回输出缓冲区内容
ob_clean 清空(擦掉)输出缓冲区
ob_end_clean 清除缓冲区内容并且关闭
ob_get_clean 得到当前缓冲区的内容并删除当前输出缓冲区,相当于ob_get_contents()和ob_clean()
php生成文件的函数 file_put_contents('文件路径','文件内容'),还有fwrite()。
我们看一个例子,文件结构:
├──demo
│ ├──public
│ │ └──css
│ │ └──bootstrap.min.css
│ ├──templates
│ │ └──newlists.php
│ ├──db.php
│ └──index.php
db.php内容:
<?php
/**
* 数据库连接封装
*/
class Db {
// 存储类的实例的静态成员变量
private static $_instance;
// 数据库链接静态变量
private static $_connectSource;
// 连接数据库配置
private $_dbConfig = [
'host' => '127.0.0.1',
'user' => 'root',
'password' => '123456',
'database' => 'news'
];
private function __construct() {}
/**
* 实例化
*/
public static function getInstance()
{
// 判断是否被实例化
if (!(self::$_instance instanceof self)) {
self::$_instance = new self();
}
return self::$_instance;
}
/**
* 数据库连接
*/
public function connect()
{
if (!self::$_connectSource) {
// 数据库连接
// @ 符号可以取消警告提示
self::$_connectSource = @mysql_connect($this->_dbConfig['host'], $this->_dbConfig['user'], $this->_dbConfig['password']);
if (!self::$_connectSource) {
//抛出异常处理
throw new Exception('mysql connect error ');
}
// 选择一款数据库
mysql_select_db($this->_dbConfig['database'], self::$_connectSource);
// 设置字符编码
mysql_query("set names UTF8", self::$_connectSource);
}
// 返回资源链接
return self::$_connectSource;
}
}
index.php(根据静态文件失效的时间,判断是否重新生成静态文件 index.html)内容:
<?php
if (is_file('index.html') && (time() - filemtime('index.html')) < (60 * 5)) { // 缓存文件存在,并且生成时间在5分钟以内,则直接返回缓存文件
require_once('index.html');
} else { // 否则,生成缓存文件
// 1、连接数据库,然后从数据库里面获取数据
require_once('db.php');
$connect = Db::getInstance()->connect();
$sql = "SELECT * FROM news WHERE `category_id` = 1 AND `status` = 10 ORDER BY id DESC LIMIT 5";
$result = mysql_query($sql, $connect);
$news = array();
while ($row = mysql_fetch_array($result)) {
$news[] = $row;
}
// 2、把获取到的数据填充到模板文件里面,生成纯静态化文件
ob_start(); // 开启输出缓存区
require_once('templates/newlists.php'); // 引入模板文件,填充数据 newlists.php界面同样进过缓冲区
file_put_contents('index.html', ob_get_contents()); // 获取输出缓冲区内容,生成纯静态化文件
ob_clean(); // 清空(擦掉)输出缓冲区
/*if(file_put_contents('index.html', ob_get_clean())) {
echo 'success';
} else {
echo 'error';
}*/
}
newlists.php (使用bootstrap框架做界面):
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>新闻中心</title>
<link rel="stylesheet" href="public/css/bootstrap.min.css" type="text/css">
</head>
<body>
<div class="container">
<h3>新闻列表</h3>
<ul class="list-group">
<?php foreach ($news as $key => $value) { ?>
<li class="list-group-item"><a href="#"><?php echo $value['title'];?></a></li>
<?php } ?>
</ul>
</div>
</body>
</html>
出现 index.html :
├──demo
│ ├──public
│ │ └──css
│ │ └──bootstrap.min.css
│ ├──templates
│ │ └──newlists.php
│ ├──db.php
│ ├──index.php
│ └──index.html
当我们不超过300秒,再次访问index.php时,服务器将访问静态文件index.html给我们访问。
而当静态文件过期后,我们再次访问index.php,服务器将为我们更新index.html静态文件。
这里讲到的只是一种触发静态文件更新的方法,当然还有:手动触发更新(设置后台管理,管理员想立即更新静态文件,就点击运行生成静态文件即可)、 Linux服务器下的crontab定时扫描程序(在Linux服务器下,设置命令:
*/5 * * * * php 路径+文件名 ==> 代表 每5分钟系统将执行一次指定文件
分 时 日 月 年 脚本 文件
页面部分缓存
该种方式,是将一个页面中不经常变的部分进行静态缓存,而经常变化的块不缓存,最后组装在一起显示;可以使用类似于ob_get_contents的方式实现,
也可以利用类似ESI之类的页面片段缓存策略,使其用来做动态页面中相对静态的片段部分的缓存。
动态内容缓存技术,总体来说就是该静态化的静态化,该动态的保持动态,最后进行组合!
可行的方案大致有三种: CSI , SSI ,ESI。 具体使用中CSI的ajax使用很普遍。
一、CSI (Client Side Includes)
含义:通过iframe、javascript、ajax 等方式将另外一个页面的内容动态包含进来。
原理:整个页面依然可以静态化为html页面,不过在需要动态的地方则通过iframe,javascript或ajax来动态加载!
例子:<iframe src='http://abroad.e2bo.com/index.php' border='0'></iframe>
优点:相对比较简单,不需要服务器端做改变和配置;
缺点:不利于搜索引擎优化(iframe方式), javascript兼容性问题,以及客户端缓存问题可能导致更新后不能及时生效!对于客户体验也不够好!
二、SSI(Server Side Includes)
含义:通过注释行SSI命令加载不同模块,构建为html,实现整个网站的内容更新;
原理:通过SSI调用各模块的对应文件,最后组装为html页面,需要服务器模块支持(具体配置本文不做详述),比如:apache服务器需要开启mod_include模块;
例子:
<!--#include virtual="header.html" -->
<!--#include virtual="login.html" -->
<!--#include virtual="footer.html" -->
优点:不受具体语言限制,比较通用,只需要Web服务器或应用服务器支持即可,Ngnix、Apache、IIS等对此都有较好的支持。
缺点:SSI只能在当前服务器上包含加载,不能够直接包含其他服务器上的文件,即不能跨域包含;
三、ESI(Edge Side Includes)
含义及原理:
网上通用的解释如下:通过使用简单的标记语言来对那些可以加速和不能加速的网页中的内容片断进行描述, 每个网页都被划分成不同的小部分分别赋予不同的缓存控制策略, 使Cache服务器可以根据这些策略在将完整的网页发送给用户之前将不同的小部分动态地组合在一起。通过这种控制, 可以有效地减少从服务器抓取整个页面的次数,而只用从原服务器中提取少量的不能缓存的片断,因此可以有效降低原服务器的负载, 同时提高用户访问的响应时间。与SSI不同的是,ESI多在 缓存服务器或代理服务器上执行!
例子:
<html>
<head>
<title>ESI Demo</title>
</head>
<body>
<esi:include src="login.php" />
<div>
<h3>这中间是可静态化html内容</3>
</div>
</body>
<html>
优点:可用于缓存整个页面或页面片段,比较适合用于缓存服务器上;
缺点:目前支持ESI的软件还比较少,官方更新也略显缓慢,因此使用不是很广!
数据缓存
顾名思义,就是缓存数据的一种方式;比如,商城中的某个商品信息,当用商品id去请求时,就会得出包括店铺信息、商品信息等数据, 此时就可以将这些数据缓存到一个php文件中,文件名包含商品id来建一个唯一标示;下一次有人想查看这个商品时,首先就直接调这个文件里面的信息, 而不用再去数据库查询;其实缓存文件中缓存的就是一个php数组之类;现实场景中使用Redis做数据缓存的比较多。
数据缓存常用的三种方式:
查询缓存
其实这跟数据缓存是一个思路,就是根据查询语句来缓存;将查询得到的结果数据缓存在一个文件或内存(如Redis)中, 下次遇到相同的查询时(不超过缓存有效时间),就直接先从这个文件里面调数据,不会再去查数据库; 但此处的缓存文件名可能就需要以查询语句为基点来建立唯一标示,按时间变更进行缓存。
其实,这一条不是真正的缓存方式;上面的页面部分缓存、数据缓存、查询缓存的缓存技术一般都用到了时间变更判断;就是对于缓存文件您需要设一个有效时间, 在这个有效时间内,相同的访问才会先取缓存文件的内容,但是超过设定的缓存时间,就需要重新从数据库中获取数据,并生产最新的缓存文件; 比如,我将我们查询费时的列表就是设置10分钟更新一次;
按内容变更进行缓存
这个也并非独立的缓存技术,需结合着用;就是当数据库内容被修改时,即刻更新缓存文件;
比如,一个人流量很大的商城,商品很多,商品表必然比较大,这表的压力也比较重;我们就可以对商品显示页进行页面缓存;
当商家在后台修改这个商品的信息时,点击保存,我们同时就更新缓存文件;那么,买家访问这个商品信息时,实际上访问的是一个静态页面,而不需要再去访问数据库;
试想,如果对商品页不缓存,那么每次访问一个商品就要去数据库查一次,如果有10万人在线浏览商品,那服务器压力就大了;
内存式缓存
提到这个,可能大家想到的首先就是Memcached;memcached是高性能的分布式内存缓存服务器。 一般的使用目的是,通过缓存数据库查询结果, 减少数据库访问次数,以提高动态Web应用的速度、 提高可扩展性。
它就是将需要缓存的信息,缓存到系统内存中,需要获取信息时,直接到内存中取;比较常用的方式就是 key–>value方式;
$key = 'key19080700113123'; // 缓存键名
$memcachehost = '192.168.6.191';
$memcacheport = 11211;
$memcachelife = 60;
$memcache = new Memcache;
$memcache->connect($memcachehost,$memcacheport) or die ("Could not connect");
$memcache->set($key,'缓存的内容');
$get = $memcache->get($key); // 获取信息
现在Redis使用的比较多了:
$key = 'key19080700113123'; // 缓存键名
$redis = new redis();
$redis->connect('127.0.0.1', 6379) or die ("Could not connect");
$redis->set('$key',"缓存的内容") or die ("Could not set");
$get = $redis->get($key); // 获取信息
apache缓存模块
apache安装完以后,是不允许被cache的。如果外接了cache或squid服务器要求进行web加速的话,就需要在htttpd.conf里进行设置,
当然前提是在安装apache的时候要激活mod_cache的模块。
安装apache时:./configure –enable-cache –enable-disk-cache –enable-mem-cache
apache缓存比较适用于网站中有几个文件访问非常频繁而又不经常变动的情况。
php APC缓存扩展
Php有一个缓存扩展 APC,全称是 Alternative PHP Cache,官方翻译叫”可选PHP缓存”。它为我们提供了缓存和优化PHP的中间代码的框架。 APC的缓存分两部分:系统缓存和用户数据缓存。
系统缓存:它是指APC把PHP文件源码的编译结果缓存起来,然后在每次调用时先对比时间标记。如果未过期,则使用缓存的中间代码运行。
默认缓存 3600s(一小时)。但是这样仍会浪费大量CPU时间。因此可以在php.ini中设置system缓存为永不过期(apc.ttl=0)。
不过如果这样设置,改动php代码后需要重启WEB服务器。目前使用较多的是指此类缓存。
用户数据缓存:缓存由用户在编写PHP代码时用apc_store和apc_fetch函数操作读取、写入的。如果数据量不大的话,可以一试。
如果数据量大,使用类似memcache此类的更加专注的内存缓存方案会更好
windows下面为php_apc.dll,需要先加载这个模块,然后是在php.ini里面进行配置:
[apc]
extension=php_apc.dll
apc.rfc1867 = on
upload_max_filesize = 100M
post_max_size = 100M
apc.max_file_size = 200M
upload_max_filesize = 1000M
post_max_size = 1000M
max_execution_time = 600 ; 每个PHP页面运行的最大时间值(秒),默认30秒
max_input_time = 600 ; 每个PHP页面接收数据所需的最大时间,默认60
memory_limit = 128M ; 每个PHP页面所吃掉的最大内存,默认8M
Opcode缓存
当php解释器完成对脚本代码的分析后,便将它们生成可以直接运行的中间代码,也称为操作码(Operate Code,opcode)。 Opcode cache的目地是避免重复编译,减少CPU和内存开销。 如果动态内容的性能瓶颈不在于CPU和内存,而在于I/O操作,比如数据库查询带来的磁盘I/O开销,那么opcode cache的性能提升是非常有限的。
Zend引擎必须从文件系统读取文件、扫描其词典和表达式、解析文件、创建要执行的计算机代码(称为Opcode), 最后执行Opcode。每一次请求PHP脚本都会执行一遍以上步骤,如果PHP源代码没有变化,那么Opcode也不会变化,显然没有必要每次都重行生成Opcode, 结合在Web中无所不在的缓存机制,我们可以把Opcode缓存下来,以后直接访问缓存的Opcode岂不是更快,启用Opcode缓存之后的流程图如下所示:
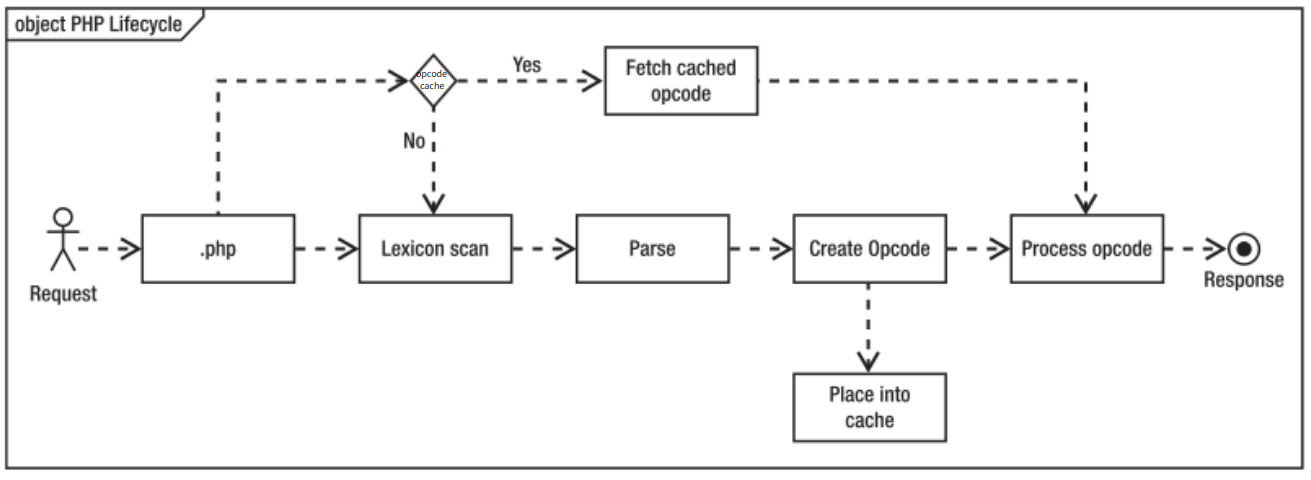
首先php代码被解析为Tokens,然后再编译为Opcode码,最后执行Opcode码,返回结果;
所以,对于相同的php文件,第一次运行时可以缓存其Opcode码,下次再执行这个页面时,直接会去找到缓存下的opcode码,直接执行最后一步, 而不再需要中间的步骤了。比较知名的是XCache、Turck MM Cache、PHP Accelerator等。
PHP Opcode原理
Opcode是一种PHP脚本编译后的中间语言,就像Java的ByteCode,或者.NET的MSL,举个例子,比如你写下了如下的PHP代码:
<?php
echo "Hello World!";
$a = 1 + 1;
echo $a;
?>
PHP执行这段代码会经过如下4个步骤(确切的来说,应该是PHP的语言引擎Zend)
- Scanning(Lexing) ,将PHP代码转换为语言片段(Tokens)
- Parsing, 将Tokens转换成简单而有意义的表达式
- Compilation, 将表达式编译成Opocdes
- Execution, 顺次执行Opcodes,每次一条,从而实现PHP脚本的功能。
插一句:现在有的Cache比如APC,可以使得PHP缓存住Opcodes,这样,每次有请求来临的时候,就不需要重复执行前面3步,从而能大幅的提高PHP的执行速度。
那什么是Lexing? 学过编译原理的同学都应该对编译原理中的词法分析步骤有所了解,Lex就是一个词法分析的依据表。
对于PHP在开始使用的是Flex,之后改为re2c, MySQL的词法分析使用的Flex,除此之外还有作为UNIX系统标准词法分析器的Lex等。
这些工具都会读进一个代表词法分析器规则的输入字符串流,然后输出以C语言实做的词法分析器源代码。 这里我们只介绍PHP的现版词法分析器,re2c。
在源码目录下的Zend/zend_language_scanner.l 文件是re2c的规则文件, 如果需要修改该规则文件需要安装re2c才能重新编译,生成新的规则文件。
Zend/zend_language_scanner.c会根据Zend/zend_language_scanner.l(Lex文件),来输入的 PHP代码进行词法分析,从而得到一个一个的“词”。
PHP4.2开始提供了一个函数叫token_get_all,这个函数就可以将一段PHP代码 Scanning成Tokens;
我们用下面的代码使用token_get_all函数处理我们上面提到的PHP代码:
<?php
echo "<pre>";
$phpcode = <<<PHPCODE
<?php
echo "Hello World!";
$a = 1 + 1;
echo $a;
?>
PHPCODE;
$tokens = token_get_all($phpcode);
print_r($tokens);
// $tokens = token_get_all($phpcode);
// foreach ($tokens as $key => $token) {
// $tokens[$key][0] = token_name($token[0]);
// }
// print_r($tokens);
?>
将会得到如下结果:
Array
(
[0] => Array
(
[0] => 379
[1] => <?php
[2] => 1
)
[1] => Array
(
[0] => 382
[1] =>
[2] => 2
)
[2] => Array
(
[0] => 328
[1] => echo
[2] => 2
)
[3] => Array
(
[0] => 382
[1] =>
[2] => 2
)
[4] => Array
(
[0] => 323
[1] => "Hello World!"
[2] => 2
)
[5] => ;
[6] => Array
(
[0] => 382
[1] =>
[2] => 2
)
[7] => =
[8] => Array
(
[0] => 382
[1] =>
[2] => 3
)
[9] => Array
(
[0] => 317
[1] => 1
[2] => 3
)
[10] => Array
(
[0] => 382
[1] =>
[2] => 3
)
[11] => +
[12] => Array
(
[0] => 382
[1] =>
[2] => 3
)
[13] => Array
(
[0] => 317
[1] => 1
[2] => 3
)
[14] => ;
[15] => Array
(
[0] => 382
[1] =>
[2] => 3
)
[16] => Array
(
[0] => 328
[1] => echo
[2] => 4
)
[17] => Array
(
[0] => 382
[1] =>
[2] => 4
)
[18] => ;
[19] => Array
(
[0] => 382
[1] =>
[2] => 4
)
[20] => Array
(
[0] => 381
[1] => ?>
[2] => 5
)
)
为了便于理解和查看,我们使用token_name函数将解析器代号修改成了符号名称说明(屏蔽上面两行,打开下面的屏蔽部分),看一下输出:
Array
(
[0] => Array
(
[0] => T_OPEN_TAG
[1] => <?php
[2] => 1
)
[1] => Array
(
[0] => T_WHITESPACE
[1] =>
[2] => 2
)
[2] => Array
(
[0] => T_ECHO
[1] => echo
[2] => 2
)
[3] => Array
(
[0] => T_WHITESPACE
[1] =>
[2] => 2
)
[4] => Array
(
[0] => T_CONSTANT_ENCAPSED_STRING
[1] => "Hello World!"
[2] => 2
)
[5] =>
[6] => Array
(
[0] => T_WHITESPACE
[1] =>
[2] => 2
)
[7] =>
[8] => Array
(
[0] => T_WHITESPACE
[1] =>
[2] => 3
)
[9] => Array
(
[0] => T_LNUMBER
[1] => 1
[2] => 3
)
[10] => Array
(
[0] => T_WHITESPACE
[1] =>
[2] => 3
)
[11] =>
[12] => Array
(
[0] => T_WHITESPACE
[1] =>
[2] => 3
)
[13] => Array
(
[0] => T_LNUMBER
[1] => 1
[2] => 3
)
[14] =>
[15] => Array
(
[0] => T_WHITESPACE
[1] =>
[2] => 3
)
[16] => Array
(
[0] => T_ECHO
[1] => echo
[2] => 4
)
[17] => Array
(
[0] => T_WHITESPACE
[1] =>
[2] => 4
)
[18] =>
[19] => Array
(
[0] => T_WHITESPACE
[1] =>
[2] => 4
)
[20] => Array
(
[0] => T_CLOSE_TAG
[1] => ?>
[2] => 5
)
)
分析这个返回结果我们可以发现,源码中的字符串,字符,空格,都会原样返回。
每个源代码中的字符,都会出现在相应的顺序处。
而其他的,比如标签,操作符,语句,都会被转换成一个包含三部分的结构:
- Token ID解释器代号 (也就是在Zend内部的该Token的对应码,比如,T_ECHO,T_STRING)
- 源码中的原来的内容
- 该词在源码中是第几行。
接下来,就是Parsing阶段了,Parsing首先会丢弃Tokens Array中的多于的空格,然后将剩余的Tokens转换成一个一个的简单的表达式
1.echo a constant string
2.add two numbers together
3.store the result of the prior expression to a variable
4.echo a variable
Bison是一种通用目的的分析器生成器。它将LALR(1)上下文无关文法的描述转化成分析该文法的C程序。 使用它可以生成解释器,编译器,协议实现等多种程序。 Bison向上兼容Yacc,所有书写正确的Yacc语法都应该可以不加修改地在Bison下工作。 它不但与Yacc兼容还具有许多Yacc不具备的特性。
Bison分析器文件是定义了名为yyparse并且实现了某个语法的函数的C代码。 这个函数并不是一个可以完成所有的语法分析任务的C程序。 除此这外我们还必须提供额外的一些函数: 如词法分析器、分析器报告错误时调用的错误报告函数等等。 我们知道一个完整的C程序必须以名为main的函数开头,如果我们要生成一个可执行文件,并且要运行语法解析器, 那么我们就需要有main函数, 并且在某个地方直接或间接调用yyparse,否则语法分析器永远都不会运行。
在PHP源码中,词法分析器的最终是调用re2c规则定义的lex_scan函数,而提供给Bison的函数则为zendlex。 而yyparse被zendparse代替。
之后就是Compilation阶段了,它会把Tokens编译成一个个op_array, 每个op_array包含如下5个部分:
1.Opcode数字的标识,指明了每个op_array的操作类型,比如add , echo
2.结果 存放Opcode结果
3.操作数1 给Opcode的操作数
4.操作数2
5.扩展值1个整形用来区别被重载的操作符
在PHP实现内部,opcode由如下的结构体表示如下:
struct _zend_op {
opcode_handler_t handler; // 执行该opcode时调用的处理函数
znode result;
znode op1;
znode op2;
ulong extended_value;
uint lineno;
zend_uchar opcode; // opcode代码
};
和CPU的指令类似,有一个标示指令的opcode字段,以及这个opcode所操作的操作数。
PHP不像汇编那么底层, 在脚本实际执行的时候可能还需要其他更多的信息,extended_value字段就保存了这类信息。
其中的result域则是保存该指令执行完成后的结果。
PHP脚本编译为opcode保存在op_array中,其内部存储的结构如下:
struct _zend_op_array {
/* Common elements */
zend_uchar type;
char *function_name; // 如果是用户定义的函数,则这里将保存函数的名字
zend_class_entry *scope;
zend_uint fn_flags;
union _zend_function *prototype;
zend_uint num_args;
zend_uint required_num_args;
zend_arg_info *arg_info;
zend_bool pass_rest_by_reference;
unsigned char return_reference;
/* END of common elements */
zend_bool done_pass_two;
zend_uint *refcount;
zend_op *opcodes; // opcode数组
zend_uint last,size;
zend_compiled_variable *vars;
int last_var,size_var;
// ...
}
如上面的注释,opcodes保存在这里,在执行的时候由下面的execute函数执行:
ZEND_API void execute(zend_op_array *op_array TSRMLS_DC)
{
// ... 循环执行op_array中的opcode或者执行其他op_array中的opcode
}
前面提到每条opcode都有一个opcode_handler_t的函数指针字段,用于执行该opcode。
PHP有三种方式来进行opcode的处理:CALL,SWITCH和GOTO。
PHP默认使用CALL的方式,也就是函数调用的方式, 由于opcode执行是每个PHP程序频繁需要进行的操作,
可以使用SWITCH或者GOTO的方式来分发, 通常GOTO的效率相对会高一些,不过效率是否提高依赖于不同的CPU。
在我们上面的例子中,我们的PHP代码会被Parsing成:
* ZEND_ECHO 'Hello World%21'
* ZEND_ADD ~0 1 1
* ZEND_ASSIGN !0 ~0
* ZEND_ECHO !0
* ZEND_RETURN 1
你可能会问了,我们的$a去那里了? 这个要介绍操作数了,每个操作数都是由以下俩个部分组成:
a)op_type : 为IS_CONST, IS_TMP_VAR, IS_VAR, IS_UNUSED, or IS_CV
b)u,一个联合体,根据op_type的不同,分别用不同的类型保存了这个操作数的值(const)或者左值(var)
而对于var来说,每个var也不一样
IS_TMP_VAR, 顾名思义,这个是一个临时变量,保存一些op_array的结果,以便接下来的op_array使用,
这种的操作数的u保存着一个指向变量表的一个句柄(整数),这种操作数一般用~开头,比如~0,表示变量表的0号未知的临时变量
IS_VAR 这种就是我们一般意义上的变量了,他们以$开头表示
IS_CV 表示ZE2.1/PHP5.1以后的编译器使用的一种cache机制,这种变量保存着被它引用的变量的地址,当一个变量第一次被引用的时候,
就会被CV起来,以后对这个变量的引用就不需要再次去查找active符号表了,CV变量以!开头表示。
这么看来,我们的$a被优化成!0了。
比如我们使用VLD来查看opcodes显示如下:
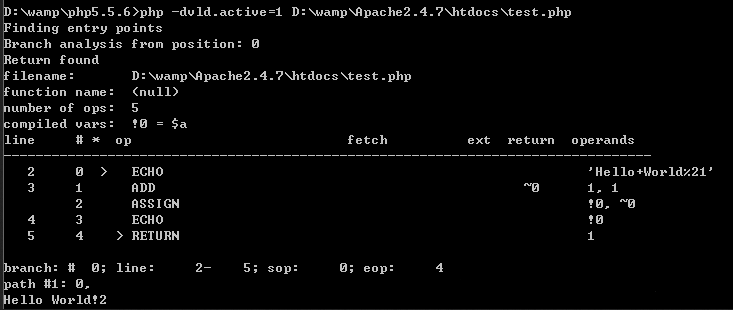
从上面这个我们看到,是不是和我们之前分析的一样呢。 如上为VLD输出的PHP代码生成的中间代码的信息,说明如下:
Branch analysis from position 这条信息多在分析数组时使用。
Return found 是否返回,这个基本上有都有。
filename 分析的文件名
function name 函数名,针对每个函数VLD都会生成一段如上的独立的信息,这里显示当前函数的名称
number of ops 生成的操作数
compiled vars 编译期间的变量,这些变量是在PHP5后添加的,它是一个缓存优化。这样的变量在PHP源码中以IS_CV标记。
op list 生成的中间代码的变量列表
是不是和前面所说的一样呢。
最后一步,也就是Execution,Zend引擎 顺次执行Opcodes,每次一条,从而实现PHP脚本的功能,和机器指令运行相似。
好了,到这里整个PHP代码的执行过程算是写完了。
参考资料
PHP 中 9 大缓存技术总结 https://www.cnblogs.com/aksir/p/6781276.html
PHP实现页面静态化——全部纯静态化 https://blog.csdn.net/qq_15096707/article/details/50809197
结合php ob函数理解缓冲机制 https://www.cnblogs.com/DeanChopper/p/4688667.html
Output Control Functions https://www.php.net/manual/en/ref.outcontrol.php
动态缓存技术之CSI,SSI,ESI https://www.cnblogs.com/Alight/p/3940651.html
缓存的三种方式 https://www.cnblogs.com/llzhang123/p/9037346.html
深度理解PHP执行流程 https://blog.csdn.net/diavid/article/details/81035188
PHP代码执行流程 https://www.cnblogs.com/yangjinqiang/p/10951606.html
php处理redis https://www.php.cn/php-weizijiaocheng-396247.html
脚踏两只船的困惑 - Memcached与Redis https://www.imooc.com/article/23549?block_id=tuijian_wz
聊一聊分布式场景下redis和memcached,及各自使用场景和优缺点 https://baijiahao.baidu.com/s?id=1628669085694391797
Redis与Memcached有何区别 ?redis和Memcached的区别比较 https://www.php.cn/mysql-tutorials-410551.html
Memcached vs Redis, 挑选哪一个? https://blog.csdn.net/itguangit/article/details/80019179
Apache缓存的实现 https://www.cnblogs.com/leixuesong/articles/5388284.html
详解浏览器缓存机制与Apache设置缓存 https://blog.csdn.net/zxp3817100/article/details/52385317
PHP之APC缓存详细介绍 https://www.cnblogs.com/vania/p/4745029.html
PHP APC缓存配置、使用详解 https://www.jb51.net/article/47772.htm
PHP-深入理解Opcode缓存 https://www.cnblogs.com/JohnABC/p/4531029.html
深入理解PHP原理之Opcodes http://www.laruence.com/2008/06/18/221.html
深入理解PHP代码的执行的过程 https://blog.csdn.net/risingsun001/article/details/22888861
token_get_all https://www.php.net/manual/en/function.token-get-all.php
PHP 手册 > 附录 > 解析器代号列表 https://www.php.net/manual/zh/tokens.php