正文
kafka是用于构建实时数据管道和流应用程序。
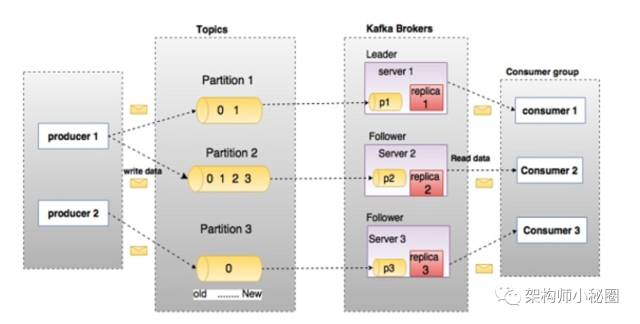
Kafka是一种高吞吐量的分布式发布订阅消息系统,它可以处理消费者在网站中的所有动作流数据。Kafka是由Apache软件基金会开发的一个开源流处理平台。 Kafka同RabbitMQ一样,也是一个MQ队列服务器。
Kafka有如下特性:
- 通过O(1)的磁盘数据结构提供消息的持久化,这种结构对于即使数以TB的消息存储也能够保持长时间的稳定性能。
- 高吞吐量:即使是非常普通的硬件Kafka也可以支持每秒数百万的消息。
- 支持通过Kafka服务器和消费机集群来分区消息。
- 支持Hadoop并行数据加载。
Kafka相关术语介绍:
- Broker -Kafka集群包含一个或多个服务器,这种服务器被称为broker
- Topic -每条发布到Kafka集群的消息都有一个类别,这个类别被称为Topic。(物理上不同Topic的消息分开存储, 逻辑上一个Topic的消息虽然保存于一个或多个broker上,但用户只需指定消息的Topic即可生产或消费数据而不必关心数据存于何处)
- Partition -Partition是物理上的概念,每个Topic包含一个或多个Partition.
- Producer -负责发布消息到Kafka broker
- Consumer -消息消费者,向Kafka broker读取消息的客户端。
- Consumer Group -每个Consumer属于一个特定的Consumer Group(可为每个Consumer指定group name,若不指定group name则属于默认的group)。
我们一般把Kafka用作log日志队列服务,日志流流程:

源码包安装
在/usr/local/src目录下下载:
sudo wget https://mirrors.tuna.tsinghua.edu.cn/apache/kafka/2.4.1/kafka_2.12-2.4.1.tgz
解压:
sudo tar zxvf kafka_2.12-2.4.1.tgz
安装完成。
启动服务
cd kafka_2.12-2.4.1
启动ZooKeeper服务:
sudo bin/zookeeper-server-start.sh config/zookeeper.properties
启动Kafka服务:
sudo bin/kafka-server-start.sh config/server.properties
创建一个名为logstash的topic:
bin/kafka-topics.sh --create --bootstrap-server localhost:9092 --replication-factor 1 --partitions 1 --topic logstash
现在就可以往kafka中写数据了。
查看topic有哪些:
bin/kafka-topics.sh --list --bootstrap-server localhost:9092
消费topic名为logstash中的队列数据:
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic logstash --from-beginning
可以实时看到数据内容。
停止服务
停止Kafka服务:
sudo bin/kafka-server-stop.sh
停止ZooKeeper服务:
sudo bin/zookeeper-server-stop.sh
其他问题
启动ZooKeeper服务时发现报错了:
[2020-04-03 14:56:53,228] INFO binding to port 0.0.0.0/0.0.0.0:2181 (org.apache.zookeeper.server.NIOServerCnxnFactory)
[2020-04-03 14:56:53,229] ERROR Unexpected exception, exiting abnormally (org.apache.zookeeper.server.ZooKeeperServerMain)
java.net.BindException: 地址已在使用
at sun.nio.ch.Net.bind0(Native Method)
at sun.nio.ch.Net.bind(Net.java:433)
at sun.nio.ch.Net.bind(Net.java:425)
at sun.nio.ch.ServerSocketChannelImpl.bind(ServerSocketChannelImpl.java:223)
at sun.nio.ch.ServerSocketAdaptor.bind(ServerSocketAdaptor.java:74)
at sun.nio.ch.ServerSocketAdaptor.bind(ServerSocketAdaptor.java:67)
at org.apache.zookeeper.server.NIOServerCnxnFactory.configure(NIOServerCnxnFactory.java:687)
at org.apache.zookeeper.server.ZooKeeperServerMain.runFromConfig(ZooKeeperServerMain.java:143)
at org.apache.zookeeper.server.ZooKeeperServerMain.initializeAndRun(ZooKeeperServerMain.java:106)
at org.apache.zookeeper.server.ZooKeeperServerMain.main(ZooKeeperServerMain.java:64)
at org.apache.zookeeper.server.quorum.QuorumPeerMain.initializeAndRun(QuorumPeerMain.java:128)
at org.apache.zookeeper.server.quorum.QuorumPeerMain.main(QuorumPeerMain.java:82)
2181端口被占用了。
看一下这个端口是否在监听:
netstat -tunl | grep 2181
看一下是什么服务在监听这个端口:
lsof -i :2181
发现是java:
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
java 9914 baiyang 120u IPv6 7073484 0t0 TCP *:2181 (LISTEN)
杀掉这个进程:
kill -9 9914
再重新启动就可以了。
Kafka原理
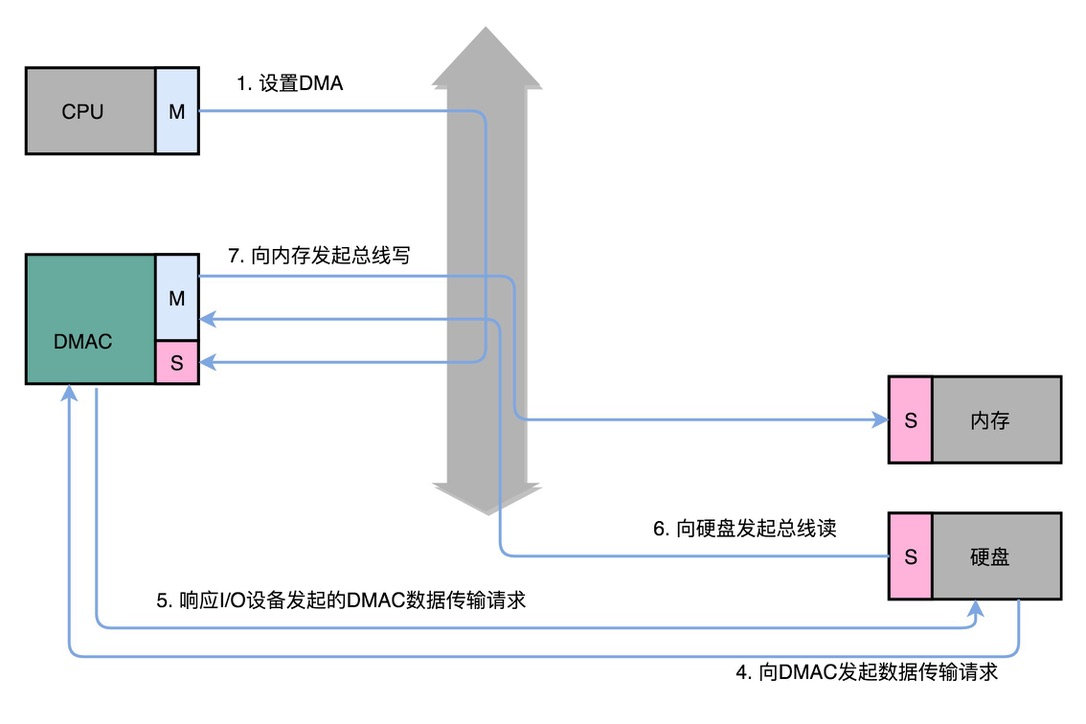
DMA (Direct Memory Access 直接内存访问)工作图:
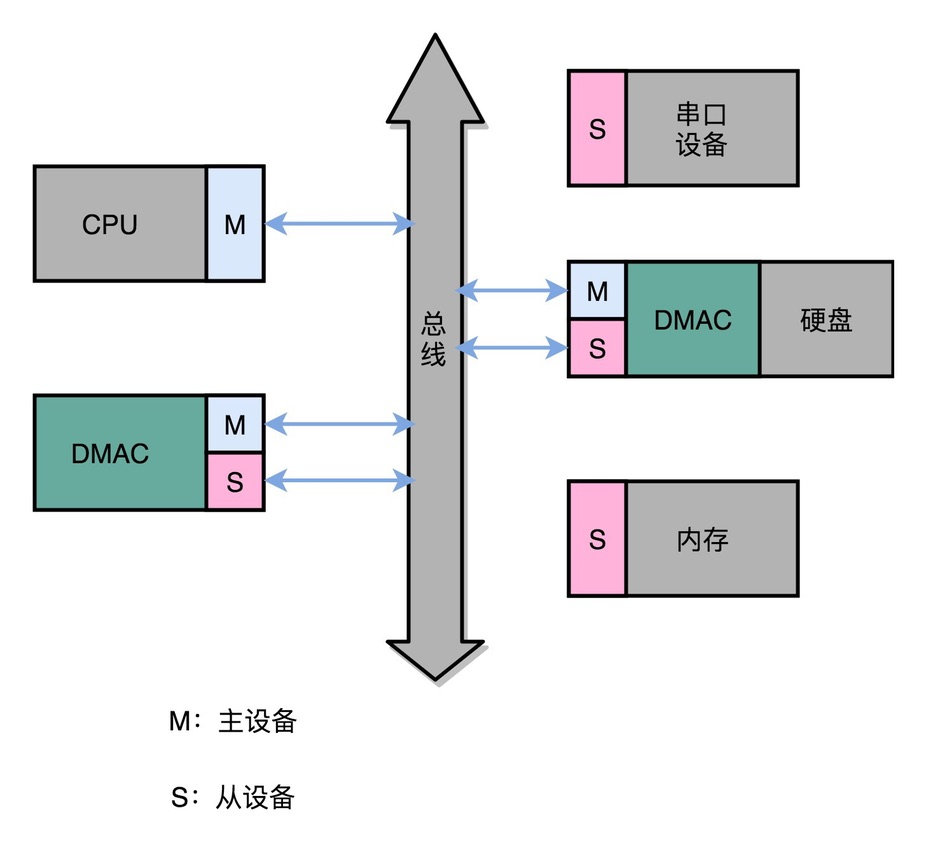
各个子设备也都装了DMA:
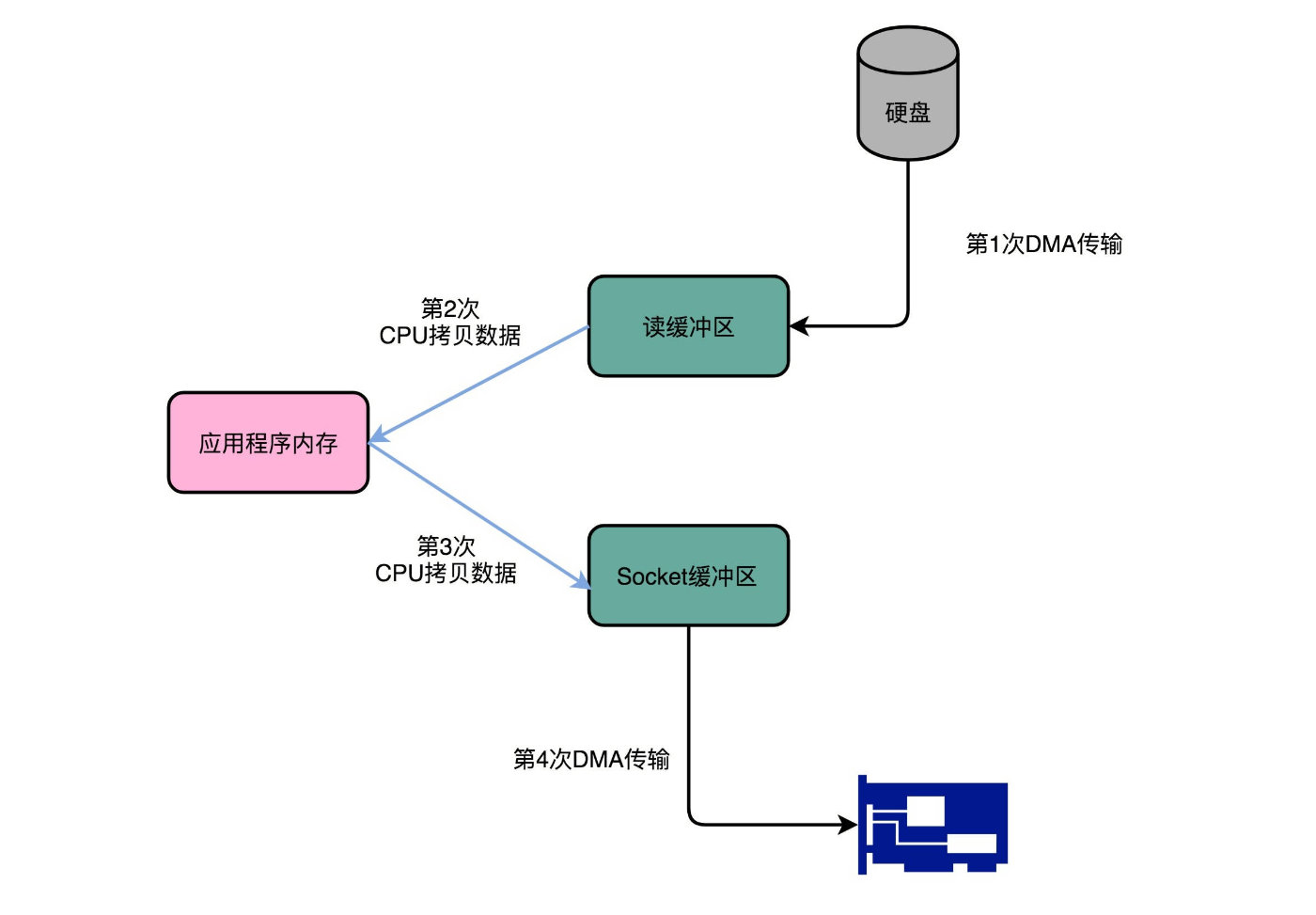
传统数据网络传输:
Kafka 零拷贝(Zero-Copy):
如果我们始终让 CPU 来进行各种数据传输工作,会特别浪费。一方面,我们的数据传输工作用不到多少 CPU 核心的“计算”功能。 另一方面,CPU 的运转速度也比 I/O 操作要快很多。所以,我们希望能够给 CPU “减负”。
于是,工程师们就在主板上放上了 DMAC 这样一个协处理器芯片(Direct Memory Access Controller)。 通过这个芯片,CPU 只需要告诉 DMAC,我们要传输什么数据,从哪里来,到哪里去,就可以放心离开了。 后续的实际数据传输工作,都会由 DMAC 来完成。随着现代计算机各种外设硬件越来越多,光一个通用的DMAC 芯片不够了, 我们在各个外设上都加上了 DMAC 芯片,使得 CPU 很少再需要关心数据传输的工作了。
在我们实际的系统开发过程中,利用好 DMA 的数据传输机制,也可以大幅提升 I/O 的吞吐率。最典型的例子就是 Kafka。
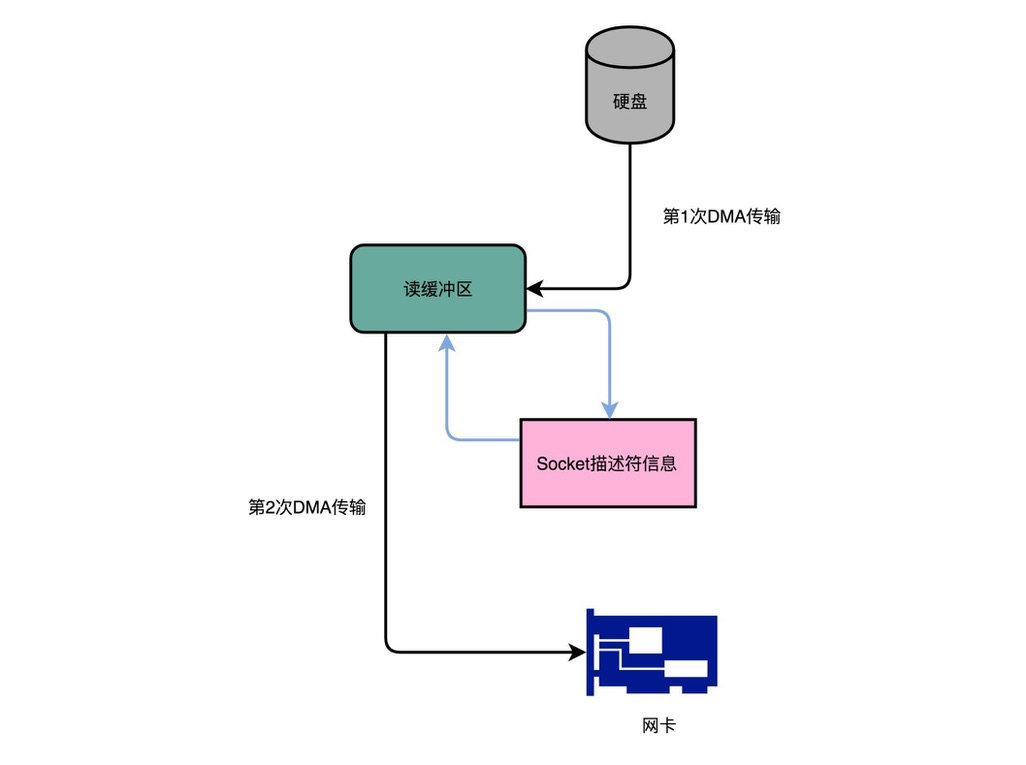
传统地从硬盘读取数据,然后再通过网卡向外发送,我们需要进行四次数据传输,其中有两次是发生在内存里的缓冲区和对应的硬件设备之间, 我们没法节省掉。但是还有两次,完全是通过CPU 在内存里面进行数据复制。
在 Kafka 里,通过Java 的 NIO 里面 FileChannel 的 transferTo 方法调用,我们可以不用把数据复制到我们应用程序的内存里面。 通过 DMA 的方式,我们可以把数据从内存缓冲区直接写到网卡的缓冲区里面。 在使用了这样的零拷贝的方法之后呢,我们传输同样数据的时间,可以缩减为原来的 1/3,相当于提升了 3 倍的吞吐率。
这也是为什么,Kafka 是目前实时数据传输管道的标准解决方案。
零拷贝
传统IO
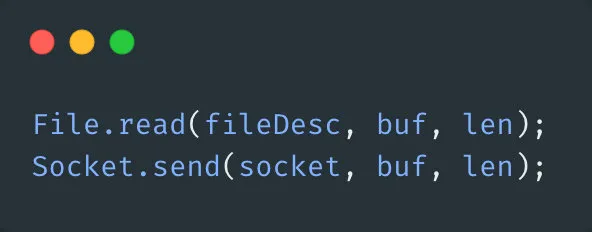
基于传统的IO方式,底层实际上通过调用read()和write()来实现。
通过read()把数据从硬盘读取到内核缓冲区,再复制到用户缓冲区;然后再通过write()写入到socket缓冲区,最后写入网卡设备。
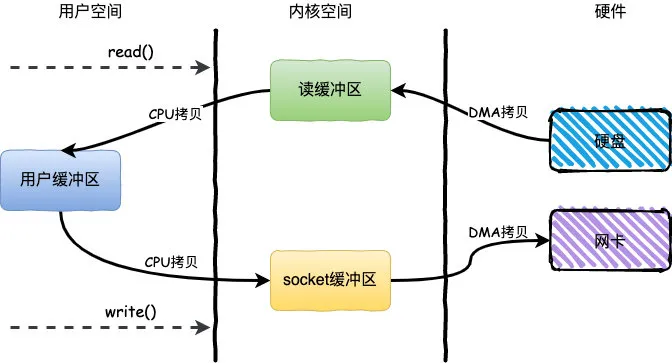
整个过程发生了4次用户态和内核态的上下文切换和4次拷贝,具体流程如下:
- 用户进程通过
read()方法向操作系统发起调用,此时上下文从用户态转向内核态 - DMA控制器把数据从硬盘中拷贝到读缓冲区
- CPU把读缓冲区数据拷贝到应用缓冲区,上下文从内核态转为用户态,
read()返回 - 用户进程通过
write()方法发起调用,上下文从用户态转为内核态 - CPU将应用缓冲区中数据拷贝到socket缓冲区
- DMA控制器把数据从socket缓冲区拷贝到网卡,上下文从内核态切换回用户态,
write()返回
那么,这里指的用户态、内核态指的是什么?上下文切换又是什么?
简单来说,用户空间指的就是用户进程的运行空间,内核空间就是内核的运行空间。
如果进程运行在内核空间就是内核态,运行在用户空间就是用户态。
为了安全起见,他们之间是互相隔离的,而在用户态和内核态之间的上下文切换也是比较耗时的。
从上面我们可以看到,一次简单的IO过程产生了4次上下文切换,这个无疑在高并发场景下会对性能产生较大的影响。
那么什么又是DMA拷贝呢?
因为对于一个IO操作而言,都是通过CPU发出对应的指令来完成,但是相比CPU来说,IO的速度太慢了,CPU有大量的时间处于等待IO的状态。
因此就产生了DMA(Direct Memory Access)直接内存访问技术,本质上来说他就是一块主板上独立的芯片,通过它来进行内存和IO设备的数据传输,从而减少CPU的等待时间。
但是无论谁来拷贝,频繁的拷贝耗时也是对性能的影响。
零拷贝
零拷贝技术是指计算机执行操作时,CPU不需要先将数据从某处内存复制到另一个特定区域,这种技术通常用于通过网络传输文件时节省CPU周期和内存带宽。
那么对于零拷贝而言,并非真的是完全没有数据拷贝的过程,只不过是减少用户态和内核态的切换次数以及CPU拷贝的次数。
这里,仅仅有针对性的来谈谈几种常见的零拷贝技术。
mmap+write
mmap+write简单来说就是使用mmap替换了read+write中的read操作,减少了一次CPU的拷贝。
mmap主要实现方式是将读缓冲区的地址和用户缓冲区的地址进行映射,内核缓冲区和应用缓冲区共享,从而减少了从读缓冲区到用户缓冲区的一次CPU拷贝。
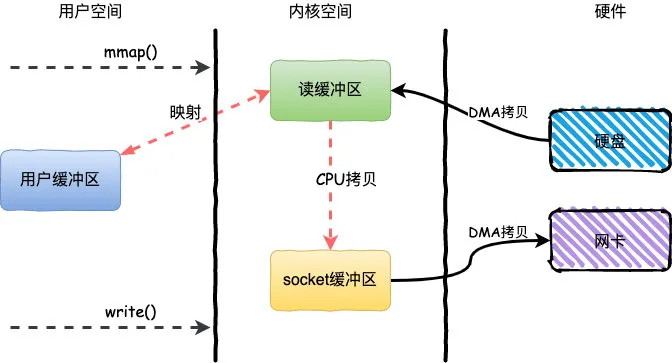
整个过程发生了4次用户态和内核态的上下文切换和3次拷贝,具体流程如下:
- 用户进程通过
mmap()方法向操作系统发起调用,上下文从用户态转向内核态 - DMA控制器把数据从硬盘中拷贝到读缓冲区
- 上下文从内核态转为用户态,mmap调用返回
- 用户进程通过
write()方法发起调用,上下文从用户态转为内核态 - CPU将读缓冲区中数据拷贝到socket缓冲区
- DMA控制器把数据从socket缓冲区拷贝到网卡,上下文从内核态切换回用户态,
write()返回
mmap的方式节省了一次CPU拷贝,同时由于用户进程中的内存是虚拟的,只是映射到内核的读缓冲区,所以可以节省一半的内存空间,比较适合大文件的传输。
sendfile
相比mmap来说,sendfile同样减少了一次CPU拷贝,而且还减少了2次上下文切换。
#include <sys/sendfile.h>
ssize_t sendfile(int out_fd, int in_fd, off_t *offset, size_t count);
sendfile是Linux2.1内核版本后引入的一个系统调用函数,通过使用sendfile数据可以直接在内核空间进行传输,
因此避免了用户空间和内核空间的拷贝,同时由于使用sendfile替代了read+write从而节省了一次系统调用,也就是2次上下文切换。
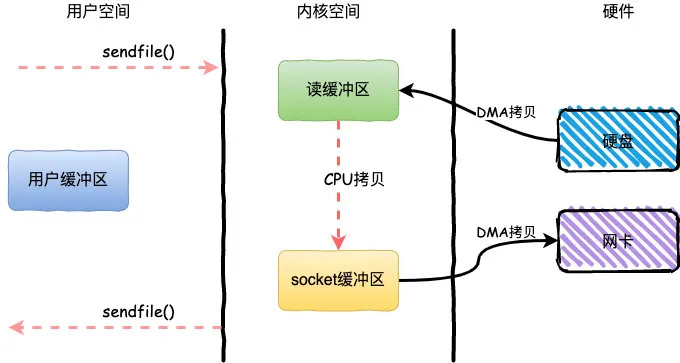
整个过程发生了2次用户态和内核态的上下文切换和3次拷贝,具体流程如下:
- 用户进程通过
sendfile()方法向操作系统发起调用,上下文从用户态转向内核态 - DMA控制器把数据从硬盘中拷贝到读缓冲区
- CPU将读缓冲区中数据拷贝到socket缓冲区
- DMA控制器把数据从socket缓冲区拷贝到网卡,上下文从内核态切换回用户态,
sendfile调用返回
sendfile方法IO数据对用户空间完全不可见,所以只能适用于完全不需要用户空间处理的情况,比如静态文件服务器。
sendfile+DMA Scatter/Gather
Linux2.4内核版本之后对sendfile做了进一步优化,通过引入新的硬件支持,这个方式叫做DMA Scatter/Gather 分散/收集功能。
它将读缓冲区中的数据描述信息–内存地址和偏移量记录到socket缓冲区,由 DMA 根据这些将数据从读缓冲区拷贝到网卡,相比之前版本减少了一次CPU拷贝的过程
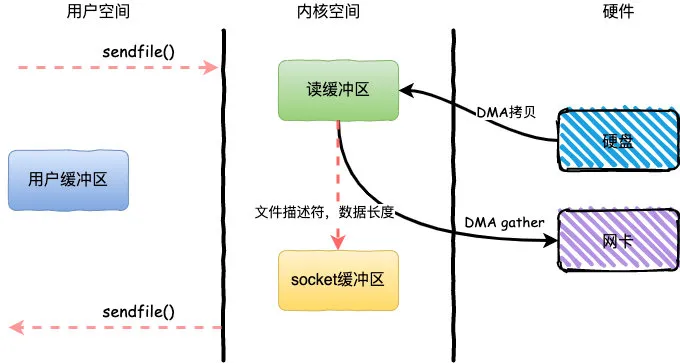
整个过程发生了2次用户态和内核态的上下文切换和2次拷贝,其中更重要的是完全没有CPU拷贝,具体流程如下:
- 用户进程通过
sendfile()方法向操作系统发起调用,上下文从用户态转向内核态 - DMA控制器利用scatter把数据从硬盘中拷贝到读缓冲区离散存储
- CPU把读缓冲区中的文件描述符和数据长度发送到socket缓冲区
- DMA控制器根据文件描述符和数据长度,使用scatter/gather把数据从内核缓冲区拷贝到网卡
sendfile()调用返回,上下文从内核态切换回用户态
DMA gather和sendfile一样数据对用户空间不可见,而且需要硬件支持,同时输入文件描述符只能是文件,但是过程中完全没有CPU拷贝过程,极大提升了性能。
应用场景
对于文章开头说的两个场景:RocketMQ和Kafka都使用到了零拷贝的技术。
对于MQ而言,无非就是生产者发送数据到MQ然后持久化到磁盘,之后消费者从MQ读取数据。
对于RocketMQ来说这两个步骤使用的是mmap+write,而Kafka则是使用mmap+write持久化数据,发送数据使用sendfile。
总结
由于CPU和IO速度的差异问题,产生了DMA技术,通过DMA搬运来减少CPU的等待时间。
传统的IOread+write方式会产生2次DMA拷贝+2次CPU拷贝,同时有4次上下文切换。
而通过mmap+write方式则产生2次DMA拷贝+1次CPU拷贝,4次上下文切换,通过内存映射减少了一次CPU拷贝,可以减少内存使用,适合大文件的传输。
sendfile方式是新增的一个系统调用函数,产生2次DMA拷贝+1次CPU拷贝,但是只有2次上下文切换。
因为只有一次调用,减少了上下文的切换,但是用户空间对IO数据不可见,适用于静态文件服务器。
sendfile+DMA gather方式产生2次DMA拷贝,没有CPU拷贝,而且也只有2次上下文切换。虽然极大地提升了性能,但是需要依赖新的硬件设备支持。
参考资料
kafka Quickstart http://kafka.apache.org/quickstart
Kafka史上最详细原理总结上 https://www.jianshu.com/p/734cf729d77b
Ubuntu简单安装Kafka https://www.cnblogs.com/yanghe123/p/11937914.html
Kafka史上最详细原理总结上 https://www.jianshu.com/p/734cf729d77b
Kafka史上最详细原理总结下 https://www.jianshu.com/p/acf010e67a19
深入详解 Kafka,从源码到架构全部讲透 https://mp.weixin.qq.com/s/7Jm0cCNlxrCfTVRnVoXivw
DMA:为什么Kafka这么快? https://weibo.com/ttarticle/p/show?id=2309404597571816391045
什么是mmap? https://mp.weixin.qq.com/s/-W3oh_fFugZLMF8P5RFSjQ
https://juejin.cn/post/6844903949359644680#heading-19
https://www.cnblogs.com/xiaolincoding/p/13719610.html
https://time.geekbang.org/column/article/118657
https://www.toutiao.com/i6898240850917114380/
Kafka 3.0.0正式发布,脱离ZooKeeper,Kafka Controller Quorum(KRaft)可抢先体验 https://mp.weixin.qq.com/s/T3s-inLA6PuzwKMfb1InIQ