正文
Unicode 是“字符集”,UTF-8 是“编码规则”。
其中,“字符集”的意思是:为每一个“字符‘”分配一个唯一的 ID(学名为码位 / 码点 / Code Point); “编码规则”的意思是:将“码位”转换为字节序列的规则(编码/解码 可以理解为 加密/解密 的过程)。
广义的Unicode是一个标准,定义了一个“字符集”以及一系列的“编码规则”,即Unicode“字符集”和UTF-8等“编码规则”。
Unicode字符集为每一个字符分配一个码位。UTF-8,是一套以8位为一个编码单位的可变长编码,会将一个码位编码为1到4个字节。
utf8mb4
MySQL在5.5.3之后增加了这个utf8mb4的编码,mb4就是most bytes 4的意思,专门用来兼容四字节的unicode。 好在utf8mb4是utf8的超集,除了将编码改为utf8mb4外不需要做其他转换。当然,为了节省空间,一般情况下使用utf8也就够了。
最初的 UTF-8 格式使用一至六个字节,最大能编码 31 位字符。 最新的 UTF-8 规范只使用一到四个字节,最大能编码21位,正好能够表示所有的 17个 Unicode 平面。 utf8 是 Mysql 中的一种字符集,只支持最长三个字节的 UTF-8字符,也就是 Unicode 中的基本多文本平面。
那上面说了既然utf8能够存下大部分中文汉字,那为什么还要使用utf8mb4呢? 原来mysql支持的 utf8 编码最大字符长度为 3 字节,如果遇到 4 字节的宽字符就会插入异常了。 三个字节的 UTF-8 最大能编码的 Unicode 字符是 0xffff,也就是 Unicode 中的基本多文种平面(BMP)。 也就是说,任何不在基本多文本平面的 Unicode字符,都无法使用 Mysql 的 utf8 字符集存储。 包括 Emoji 表情(Emoji 是一种特殊的 Unicode 编码,常见于 ios 和 android 手机上),和很多不常用的汉字, 以及任何新增的 Unicode 字符等等。
utf8mb4对应的排序字符集有 utf8mb4_unicode_ci、utf8mb4_general_ci。
ci 是 case insensitive, 即 “大小写不敏感”, a 和 A 会在字符判断中会被当做一样的。
- 准确性:
- utf8mb4_unicode_ci是基于标准的Unicode来排序和比较,能够在各种语言之间精确排序
- utf8mb4_general_ci没有实现Unicode排序规则,在遇到某些特殊语言或者字符集,排序结果可能不一致。
- 但是,在绝大多数情况下,这些特殊字符的顺序并不需要那么精确。
- 性能
- utf8mb4_general_ci在比较和排序的时候更快
- utf8mb4_unicode_ci在特殊情况下,Unicode排序规则为了能够处理特殊字符的情况,实现了略微复杂的排序算法。
- 但是在绝大多数情况下,不会发生此类复杂比较。相比选择哪一种collation,使用者更应该关心字符集与排序规则在db里需要统一。
总而言之,utf8mb4_general_ci 和 utf8mb4_unicode_ci 是我们最常使用的排序规则。 utf8mb4_general_ci 校对速度快,但准确度稍差。 utf8mb4_unicode_ci 准确度高,但校对速度稍慢,两者都不区分大小写。 这两个选哪个视自己情况而定,还是那句话尽可能保持db中的字符集和排序规则的统一。
ASCII与Unicode区别
ASCII 与 Unicode 区别:
- ASCII编码是1个字节,而Unicode编码通常是2个字节。
- ASCII是单字节编码,无法用来表示中文;而Unicode可以表示所有语言。
- 用Unicode编码比ASCII编码需要多一倍的存储空间。
ASCII编码
ASCII 码使用指定的7 位或8 位二进制数组合来表示128 或256 种可能的字符。标准ASCII 码也叫基础ASCII码, 使用7 位二进制数(剩下的1位二进制为0)来表示所有的大写和小写字母,数字0 到9、标点符号, 以及在美式英语中使用的特殊控制字符。其中最后一位用于奇偶校验。
问题:ASCII是单字节编码,无法用来表示中文(中文编码至少需要2个字节),所以,中国制定了GB2312编码,用来把中文编进去。 但世界上有许多不同的语言,所以需要一种统一的编码。
Unicode
Unicode把所有语言都统一到一套编码里,这样就不会再有乱码问题了。
Unicode最常用的是用两个字节表示一个字符(如果要用到非常偏僻的字符,就需要4个字节)。现代操作系统和大多数编程语言都直接支持Unicode。
Unicode和ASCII的区别
ASCII编码是1个字节,而Unicode编码通常是2个字节。
字母A用ASCII编码是十进制的65,二进制的01000001;而在Unicode中,只需要在前面补0,即为:00000000 01000001。
新的问题:如果统一成Unicode编码,乱码问题从此消失了。但是,如果你写的文本基本上全部是英文的话, 用Unicode编码比ASCII编码需要多一倍的存储空间,在存储和传输上就十分不划算。
UTF8
所以,本着节约的精神,又出现了把Unicode编码转化为“可变长编码”的UTF-8编码。
UTF-8编码把一个Unicode字符根据不同的数字大小编码成1-6个字节,常用的英文字母被编码成1个字节,汉字通常是3个字节, 只有很生僻的字符才会被编码成4-6个字节。如果你要传输的文本包含大量英文字符,用UTF-8编码就能节省空间。
字符 ASCII Unicode UTF-8
A 01000001 00000000 01000001 01000001
中文 x 01001110 00101101 01001110 00101101
从上面的表格还可以发现,UTF-8编码有一个额外的好处,就是ASCII编码实际上可以被看成是UTF-8编码的一部分, 所以,大量只支持ASCII编码的历史遗留软件可以在UTF-8编码下继续工作。
计算机中通用的字符编码的工作方式
在计算机内存中,统一使用Unicode编码,当需要保存到硬盘或者需要传输的时候,就转换为UTF-8编码。
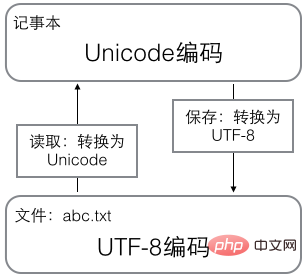
用记事本编辑的时候,从文件读取的UTF-8字符被转换为Unicode字符到内存里,编辑完成后,保存的时候再把Unicode转换为UTF-8保存到文件:
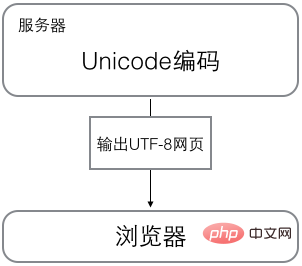
浏览网页的时候,服务器会把动态生成的Unicode内容转换为UTF-8再传输到浏览器:
参考资料
Unicode 和 UTF-8 的关系与区别 https://blog.csdn.net/mahoon411/article/details/115586090
Unicode 和 UTF-8 有什么区别? https://www.zhihu.com/question/23374078/answer/69732605
最为透彻的utf-8、unicode详解 https://blog.csdn.net/TCF_JingFeng/article/details/80134600
Mysql—utf8、utf8mb4、utf8mb4_unicode_ci、utf8mb4_general_ci区别 https://blog.csdn.net/qq_41653753/article/details/107706711
mysql中的utf8mb4、utf8mb4_unicode_ci、utf8mb4_general_ci https://blog.csdn.net/Ezerbel/article/details/111566683
unicode和ascii的区别是什么 https://www.php.cn/faq/483053.html