正文
无意中发现了这本书,Go 语言编程之旅, 这本书中的 示例代码 地址也找到了。
书的作者 煎鱼 的博客地址是 煎鱼博客 , 博客的 Github地址 , 作者的 Github地址。
里面看到了 Gin框架示例, 相应的一系列 博文, 里面说是 Gin实践 的连载,在 segmentfault 网站上, 另外在作者博客中也记录了这个系列,不过内容看着不一样, gin, 看着内容是作者博客 Go语言入门系列 中的一部分。 对比看了下,segmentfault 上那个是2018年写的,好多已经过时了,就不要看了。
作者还有 Go 语言进阶之旅。
《Go 语言编程之旅》 这个系列作为入门,是种选择。本书概览:
可以先看下 附录 A:Go Modules 终极入门 熟悉一下编程环境, 工欲善其事必先利其器,这样就不会为 GOPATH、Go Modules 所乱花渐欲迷人眼了。
第一章 命令行应用
1.1 打开工具之旅
我想,绝大部分工程师,都会想拥有一个属于自己的工具集,那一定是一件很酷又非常有趣的事情。 因为它在给你带来极大的生活和工作效率提高的同时也能给你带来不少的成就感,更重要的是在你持续不断的维护迭代你的项目的时候, 你的技术也会得到磨炼,而你遇到的问题,别人可能也有,当你更进一步地开源出去了,也有可能会给别人带来非常大的帮助, 事实上,GitHub 里许许多多的优秀个人开源项目也是这么来的,这必然是一件一举多得的事情。
因此在本章节中,我们将做一个简单的通用工具集,这是最直接的方式,我们用它解决在平时工作中经常会遇到的一些小麻烦, 让我们不再去借助其它的快捷网站,让我们自己的产品为自己服务,不断的迭代它。
1.1.1 用什么
本次工具类别的项目我们会在一开始使用标准库 flag 来作为引子,标准库 flag 是在 Go 语言中的一个大利器, 它主要的功能是实现了命令行参数的解析,能够让我们在开发的过程中非常方便的解析和处理命令行参数, 是一个需要必知必会的基础标准库,因此在本章我们会先对标准库 flag 进行基本的讲解。
在后续项目的具体开发和进一步拓展中,我们将使用开源项目 Cobra 来协助我们快速构建我们的 CLI 应用程序, Cobra 的主要功能是创建功能强大的现代 CLI 应用程序,同时也是一个生成应用程序和命令文件的程序。它非常的便捷和强大, 目前市面上许多的著名的 Go 语言开源项目都是使用 Cobra 来构建的,例如:Kubernetes、Hugo、etcd、Docker 等等,是非常可靠的一个开源项目。
1.1.2 初始化项目
开始之前,我们通过如下命令初始化 tour 项目(若为 Windows 系统,可根据实际情况自行调整项目的路径),执行如下命令:
$ mkdir -p $HOME/go-programming-tour-book/tour
$ cd $HOME/go-programming-tour-book/tour
$ go mod init github.com/go-programming-tour-book/tour
在执行命令完毕后,我们就已经完成了初始化项目的第一步,各命令的含义如下:
确定本书的项目工作路径,并循环递归创建 tour 项目目录。
切换当前工作区到 tour 项目目录下。
初始化项目的 Go modules,设置项目的模块路径(示例中是github.com/go-programming-tour-book/tour,我们可以直接写如tour2)。
需要注意的一点是,我们在依赖管理上使用的是 Go modules 的模式(详细介绍可见附录), 也就是系统环境变量 GO111MODULE 为 auto 或 on(开启状态),若你在初始化 Go modules 时出现了相关错误提示, 应当将 Go modules 开启,如下命令:
$ go env -w GO111MODULE=on
执行这条命令后,Go 工具链将会将系统环境变量 GO111MODULE 设置为 on,但是需要注意的是若语句 go env -w 并不支持覆写,
你手动进行 export GO111MODULE=on 设置亦可。
另外若是初次使用 Go modules,建议设置国内镜像代理,否则会出现外网模块拉不下来的问题,设置命令如下:
$ go env -w GOPROXY=https://goproxy.cn,direct
1.1.3 示例
1.1.3.1 flag 基本使用和长短选项
我们编写一个简单的示例,用于了解标准库 flag 的基本使用,代码如下:
func main() {
var name string
flag.StringVar(&name, "name", "Go 语言编程之旅", "帮助信息")
flag.StringVar(&name, "n", "Go 语言编程之旅", "帮助信息")
flag.Parse()
log.Printf("name: %s", name)
}
通过上述代码,我们调用标准库 flag 的 StringVar 方法实现了对命令行参数 name 的解析和绑定, 其各个形参的含义分别为命令行标识位的名称、默认值、帮助信息。针对命令行参数,其支持如下三种命令行标志语法,分别如下:
-flag:仅支持布尔类型。
-flag x :仅支持非布尔类型。
-flag=x:均支持
同时 flag 标准库还提供了多种类型参数绑定的方式,根据各自的应用程序使用情况选用即可,接下来我们运行该程序,检查输出结果与预想的是否一致,如下:
$ go run main.go -name=eddycjy -n= 煎鱼
name: 煎鱼
我们可以发现输出的结果是最后一个赋值的变量,也就是 -n。
你可能会有一些疑惑,为什么长短选项要分开两次调用,一个命令行参数的标志位有长短选项,是常规需求,这样子岂不是重复逻辑,有没有优化的办法呢。
实际上标准库 flag 并不直接支持该功能,但是我们可以通过其它第三方库来实现这个功能,这块我们在后续也会使用到。
1.1.3.3 子命令的实现
在我们日常使用的 CLI 应用中,另外一个最常见的功能就是子命令的使用,一个工具它可能包含了大量相关联的功能命令以此形成工具集, 可以说是刚需,那么这个功能在标准库 flag 中可以如何实现呢,如下述示例:
var name string
func main() {
flag.Parse()
args := flag.Args()
if len(args) <= 0 {
return
}
switch args[0] {
case "go":
goCmd := flag.NewFlagSet("go", flag.ExitOnError)
goCmd.StringVar(&name, "name", "Go 语言", "帮助信息")
_ = goCmd.Parse(args[1:])
case "php":
phpCmd := flag.NewFlagSet("php", flag.ExitOnError)
phpCmd.StringVar(&name, "n", "PHP 语言", "帮助信息")
_ = phpCmd.Parse(args[1:])
}
log.Printf("name: %s", name)
}
在上述代码中,我们首先调用了 flag.Parse 方法,将命令行解析为定义的标志,便于我们后续的参数使用。
另外由于我们需要处理子命令的情况,因此我们调用了 flag.NewFlagSet 方法, 该方法会返回带有指定名称和错误处理属性的空命令集给我们去使用,相当于就是创建一个新的命令集了去支持子命令了。
这里需要特别注意的是 flag.NewFlagSet 方法的第二个参数是 ErrorHandling,用于指定处理异常错误的情况处理,其内置提供以下三种模式:
const (
// 返回错误描述
ContinueOnError ErrorHandling = iota
// 调用 os.Exit(2) 退出程序
ExitOnError
// 调用 panic 语句抛出错误异常
PanicOnError
)
接下来我们运行针对子命令的示例程序,对正确和异常场景进行检查,如下:
$ go run main.go go -name=eddycjy
name: eddycjy
$ go run main.go php -n= 煎鱼
name: 煎鱼
$ go run main.go go -n=eddycjy
flag provided but not defined: -n
Usage of go:
-name string
帮助信息 (default "Go 语言")
exit status 2
通过输出结果可以知道这段示例程序已经准确的识别了不同的子命令,并且因为我们 ErrorHandling 传递的是 ExitOnError 级别, 因此在识别到传递的命令行参数标志是未定义时,会进行直接退出程序并提示错误信息。
1.1.4 分析
从使用上来讲,标准库 flag 非常方便,一个简单的 CLI 应用很快就搭建起来了,但是它又是怎么实现的呢, 我们一起来深入看看,要做到知其然知其所以然,肯定非常有意思,整体分析流程如下:
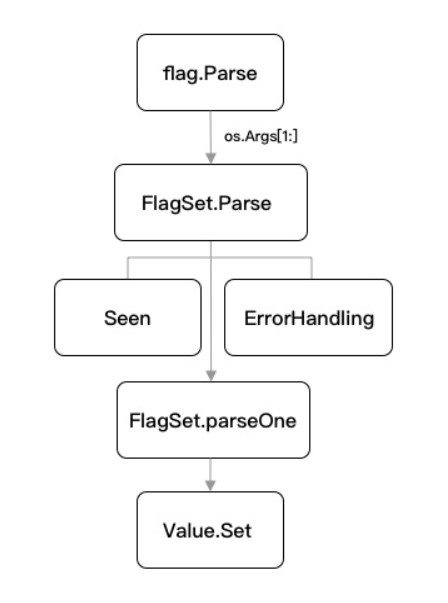
1.1.4.1 flag.Parse
首先我们看到 flag.Parse 方法,它总是在所有命令行参数注册的最后进行调用,函数功能是解析并绑定命令行参数,我们一起看看其内部实现:
type FlagSet struct {
Usage func()
name string
parsed bool
actual map[string]*Flag
formal map[string]*Flag
args []string // arguments after flags
errorHandling ErrorHandling
output io.Writer // nil means stderr; use out() accessor
}
func NewFlagSet(name string, errorHandling ErrorHandling) *FlagSet {
f := &FlagSet{
name: name,
errorHandling: errorHandling,
}
f.Usage = f.defaultUsage
return f
}
var CommandLine = NewFlagSet(os.Args[0], ExitOnError)
func Parse() {
CommandLine.Parse(os.Args[1:])
}
该方法是调用 NewFlagSet 方法实例化一个新的空命令集,然后通过调用 os.Args 作为外部参数传入。
但这里需要注意一个点,Parse 方法使用的是 CommandLine 变量,它所默认传入的 ErrorHandling 是 ExitOnError, 也就是如果在解析时遇到异常或错误,就会直接退出程序,因此如果你的应用程序不希望解析命令行参数失败, 就导致应用启动中断的话,需要进行额外的处理。
1.1.4.2 FlagSet.Parse
接下来是 FlagSet.Parse,其主要承担了 parse 方法的异常分流处理,如下:
func (f *FlagSet) Parse(arguments []string) error {
f.parsed = true
f.args = arguments
for {
seen, err := f.parseOne()
if seen {
continue
}
if err == nil {
break
}
switch f.errorHandling {
case ContinueOnError:
return err
case ExitOnError:
os.Exit(2)
case PanicOnError:
panic(err)
}
}
return nil
}
该方法是对解析方法的进一步封装,实质的解析逻辑放在 parseOne 中,而解析过程中遇到的一些特殊情况, 例如:重复解析、异常处理等,均直接由该方法处理,这实际上是一个分层明显,结构清晰的方法设计,很值得大家去参考。
1.1.4.3 FlagSet.parseOne
最后会流转到命令行解析的核心方法 FlagSet.parseOne 下进行处理,如下:
func (f *FlagSet) parseOne() (bool, error) {
if len(f.args) == 0 {
return false, nil
}
s := f.args[0]
if len(s) < 2 || s[0] != '-' {
return false, nil
}
numMinuses := 1
if s[1] == '-' {
numMinuses++
if len(s) == 2 { // "--" terminates the flags
f.args = f.args[1:]
return false, nil
}
}
name := s[numMinuses:]
if len(name) == 0 || name[0] == '-' || name[0] == '=' {
return false, f.failf("bad flag syntax: %s", s)
}
...
}
在上述代码中,我们可以看到主要是针对一些不符合命令行参数绑定规则的校验处理,大致分为以下四种情况:
如果命令行参数长度为 0。
如果遇到长度小于 2 或不满足 flag 标识符 -。
如果 flag 标志位为 - 的情况下,则中断处理,并跳过该字符,也就是后续会以 - 进行处理。
如果在处理 flag 标志位后,取到的参数名不符合规则,也将中断处理,例如:go run main.go go ---name=eddycjy,就会导致返回 bad flag syntax 的错误提示。
在定位命令行参数节点上,采用的依据是根据“-”的索引定位解析出上下的参数名(name)和参数的值(value),部分核心代码如下:
func (f *FlagSet) parseOne() (bool, error) {
f.args = f.args[1:]
hasValue := false
value := ""
for i := 1; i < len(name); i++ { // equals cannot be first
if name[i] == '=' {
value = name[i+1:]
hasValue = true
name = name[0:i]
break
}
}
...
}
最后在设置参数值上,会对值类型进行判断,若是布尔类型,则调用定制的 boolFlag 类型进行判断和处理, 最后通过该 flag 所提供的 Value.Set 方法将参数值设置到对应的 flag 中去,核心代码如下:
func (f *FlagSet) parseOne() (bool, error) {
if fv, ok := flag.Value.(boolFlag); ok && fv.IsBoolFlag() {
if hasValue {
if err := fv.Set(value); err != nil {
return false, f.failf("invalid boolean value %q for -%s: %v", value, name, err)
}
} else {
if err := fv.Set("true"); err != nil {
return false, f.failf("invalid boolean flag %s: %v", name, err)
}
}
} else {
...
if err := flag.Value.Set(value); err != nil {
return false, f.failf("invalid value %q for flag -%s: %v", value, name, err)
}
}
}
FlagSet.parseOne 方法完整代码:
// parseOne parses one flag. It reports whether a flag was seen.
func (f *FlagSet) parseOne() (bool, error) {
if len(f.args) == 0 {
return false, nil
}
s := f.args[0]
if len(s) < 2 || s[0] != '-' {
return false, nil
}
numMinuses := 1
if s[1] == '-' {
numMinuses++
if len(s) == 2 { // "--" terminates the flags
f.args = f.args[1:]
return false, nil
}
}
name := s[numMinuses:]
if len(name) == 0 || name[0] == '-' || name[0] == '=' {
return false, f.failf("bad flag syntax: %s", s)
}
// it's a flag. does it have an argument?
f.args = f.args[1:]
hasValue := false
value := ""
for i := 1; i < len(name); i++ { // equals cannot be first
if name[i] == '=' {
value = name[i+1:]
hasValue = true
name = name[0:i]
break
}
}
m := f.formal
flag, alreadythere := m[name] // BUG
if !alreadythere {
if name == "help" || name == "h" { // special case for nice help message.
f.usage()
return false, ErrHelp
}
return false, f.failf("flag provided but not defined: -%s", name)
}
if fv, ok := flag.Value.(boolFlag); ok && fv.IsBoolFlag() { // special case: doesn't need an arg
if hasValue {
if err := fv.Set(value); err != nil {
return false, f.failf("invalid boolean value %q for -%s: %v", value, name, err)
}
} else {
if err := fv.Set("true"); err != nil {
return false, f.failf("invalid boolean flag %s: %v", name, err)
}
}
} else {
// It must have a value, which might be the next argument.
if !hasValue && len(f.args) > 0 {
// value is the next arg
hasValue = true
value, f.args = f.args[0], f.args[1:]
}
if !hasValue {
return false, f.failf("flag needs an argument: -%s", name)
}
if err := flag.Value.Set(value); err != nil {
return false, f.failf("invalid value %q for flag -%s: %v", value, name, err)
}
}
if f.actual == nil {
f.actual = make(map[string]*Flag)
}
f.actual[name] = flag
return true, nil
}
1.1.5 自定义参数类型
刚刚看到上述的分析后,不知道你是否注意到,flag 的命令行参数类型是可以自定义的, 也就是我们的 Value.Set 方法,我们只需要实现其对应的 Value 相关的两个接口就可以了,如下:
type Value interface {
String() string
Set(string) error
}
我们将原先的字符串变量 name 修改为类别别名,并为其定义符合 Value 的两个结构体方法,示例代码如下:
type Name string
func (i *Name) String() string {
return fmt.Sprint(*i)
}
func (i *Name) Set(value string) error {
if len(*i) > 0 {
return errors.New("name flag already set")
}
*i = Name("eddycjy:" + value)
return nil
}
func main() {
var name Name
flag.Var(&name, "name", "帮助信息")
flag.Parse()
log.Printf("name: %s", name)
}
该示例最终的输出结果为 name: eddycjy:Go 语言编程之旅 ,也就是只要我们实现了 Value 的 String 和 Set 方法, 就可以进行定制化,然后无缝地接入我们的命令行参数的解析中,这就是 Go 语言的接口设计魅力之处。
1.1.6 小结
我们初步介绍了本章的一个基本思路,并对我们最常用的标准库 flag 进行了介绍和使用说明, 标准库 flag 的使用将始终穿插在所有的章节中,因为我们常常会需求读取外部命令行的参数,例如像是启动端口号、日志路径设置等等,非常常用。
1.2 单词格式转换
在日常的生活和工作中,我们经常拿到一些单词的命名字符串,需要将它转换为各种各样格式的命名,像是在程序中, 你原本已经定义了某个命名,但你可能会需要将其转为一个或多个 const 常量,这时候如果你人工一个个的修改,那就太繁琐了, 并且还有可能改错,如此来往多次,那这工作效率实在是太低了。
实际上我们可以通过编写一个小工具来实现这个功能,一来能够满足自己的需求,二来也能不断迭代,甚至满足一些定制化需求, 因此我们将在本章节中开始打造属于自己的工具链,首先我们将把工具的项目架子给搭建起来, 然后开始实现一个工具,也就是支持多种单词格式转换的功能。
1.2.1 安装
首先需要安装本项目所依赖的基础库 Cobra,便于我们后续快速搭建 CLI 应用程序,在项目根目录执行命令如下:
$ go get -u github.com/spf13/cobra@v1.0.0
1.2.2 初始化 cmd 和 word 子命令
接下来需要进行项目目录的初始化,目录结构如下:
tour
├── main.go
├── go.mod
├── go.sum
├── cmd
├── internal
└── pkg
在本项目中,我们创建了入口文件 main.go,并新增了三个目录,分别是 cmd、internal 以及 pkg, 并在 cmd 目录下新建 word.go 文件,用于单词格式转换的子命令 word 的设置,写入如下代码:
var wordCmd = &cobra.Command{
Use: "word",
Short: "单词格式转换",
Long: "支持多种单词格式转换",
Run: func(cmd *cobra.Command, args []string) {},
}
func init() {}
接下来还是在 cmd 目录下,增加 root.go 文件,作为根命令,写入如下代码:
var rootCmd = &cobra.Command{}
func Execute() error {
return rootCmd.Execute()
}
func init() {
rootCmd.AddCommand(wordCmd)
}
最后在启动 main.go 文件中,写入如下运行代码:
func main() {
err := cmd.Execute()
if err != nil {
log.Fatalf("cmd.Execute err: %v", err)
}
}
1.2.3 单词转换
在功能上我们需要针对所计划兼容的单词转换类型进行具体的编码,分为四种类型支持:
单词全部转为小写。
单词全部转为大写。
下划线单词转为大写驼峰。
下划线单词转为小写驼峰。
驼峰转为小写驼峰。
我们将在项目的 internal 目录下,新建 word 目录及文件,并在 word.go 写入后面的章节代码, 完成对上述的四种单词类型转换的功能支持,目录结构如下:
├── internal
│ └── word
│ └── word.go
1.2.3.1 全部转为小写/大写
第一部分是针对任何单词进行大小写的转换,这一块比较简单,直接就是分别调用标准库 strings 中的 ToUpper 和 ToLower 方法直接进行转换, 其原生方法的作用就是转为大写和小写,写入代码如下:
func ToUpper(s string) string {
return strings.ToUpper(s)
}
func ToLower(s string) string {
return strings.ToLower(s)
}
1.2.3.2 下划线转大写驼峰
第二部分是针对下划线命名方式的单词进行大写驼峰的转换,主体逻辑是将下划线替换为空格字符, 然后将其所有字符修改为其对应的首字母大写的格式,最后将先前的空格字符替换为空, 就可以确保各个部分所返回的首字母是大写并且是完整的一个字符串了,写入代码如下:
func UnderscoreToUpperCamelCase(s string) string {
s = strings.Replace(s, "_", " ", -1)
s = strings.Title(s)
return strings.Replace(s, " ", "", -1)
}
1.2.3.3 下线线转小写驼峰
第三部分是针对下划线命名方式的单词进行小写驼峰的转换,主体逻辑可以直接复用大写驼峰的转换方法, 然后只需要对其首字母进行处理就好了,在该方法中我们直接将字符串的第一位取出来,然后利用 unicode.ToLower 转换就可以了, 写入代码如下:
func UnderscoreToLowerCamelCase(s string) string {
s = UnderscoreToUpperCamelCase(s)
return string(unicode.ToLower(rune(s[0]))) + s[1:]
}
1.2.3.4 驼峰转下划线
第四部分是针对大写或小写驼峰的单词进行下划线转换,也就是与第二和第三点相反的转换操作, 这里我们直接使用 govalidator 库所提供的转换方法,主体逻辑为将字符串转换为小写的同时添加下划线, 比较特殊的一点在于,当前字符若不为小写、下划线、数字,那么进行处理的同时将对 segment 置空, 保证其每一段的区间转换是正确的,写入代码如下:
func CamelCaseToUnderscore(s string) string {
var output []rune
for i, r := range s {
if i == 0 {
output = append(output, unicode.ToLower(r))
continue
}
if unicode.IsUpper(r) {
output = append(output, '_')
}
output = append(output, unicode.ToLower(r))
}
return string(output)
}
1.2.4 word 子命令
在完成了单词的各个转换方法后,我们开始编写 word 子命令,将其对应的方法集成到我们的 Command 中, 打开项目下的 cmd/word.go 文件,定义目前单词所支持的转换模式枚举值,新增代码如下:
const (
ModeUpper = iota + 1 // 全部转大写
ModeLower // 全部转小写
ModeUnderscoreToUpperCamelCase // 下划线转大写驼峰
ModeUnderscoreToLowerCamelCase // 下线线转小写驼峰
ModeCamelCaseToUnderscore // 驼峰转下划线
)
接下来进行具体的单词子命令的设置和集成,继续新增如下代码:
var desc = strings.Join([]string{
"该子命令支持各种单词格式转换,模式如下:",
"1:全部转大写",
"2:全部转小写",
"3:下划线转大写驼峰",
"4:下划线转小写驼峰",
"5:驼峰转下划线",
}, "\n")
var wordCmd = &cobra.Command{
Use: "word",
Short: "单词格式转换",
Long: desc,
Run: func(cmd *cobra.Command, args []string) {
var content string
switch mode {
case ModeUpper:
content = word.ToUpper(str)
case ModeLower:
content = word.ToLower(str)
case ModeUnderscoreToUpperCamelCase:
content = word.UnderscoreToUpperCamelCase(str)
case ModeUnderscoreToLowerCamelCase:
content = word.UnderscoreToLowerCamelCase(str)
case ModeCamelCaseToUnderscore:
content = word.CamelCaseToUnderscore(str)
default:
log.Fatalf("暂不支持该转换模式,请执行 help word 查看帮助文档")
}
log.Printf("输出结果: %s", content)
},
}
在上述代码中,核心在于子命令 word 的 cobra.Command 调用和设置,其一共包含如下四个常用选项,分别是:
Use:子命令的命令标识。
Short:简短说明,在 help 输出的帮助信息中展示。
Long:完整说明,在 help 输出的帮助信息中展示。
接下来我们根据单词转换所需的参数,分别是单词内容和转换的模式进行命令行参数的设置和初始化,继续写入如下代码:
var str string
var mode int8
func init() {
wordCmd.Flags().StringVarP(&str, "str", "s", "", "请输入单词内容")
wordCmd.Flags().Int8VarP(&mode, "mode", "m", 0, "请输入单词转换的模式")
}
在 VarP 系列的方法中,第一个参数为需绑定的变量、第二个参数为接收该参数的完整的命令标志, 第三个参数为对应的短标识,第四个参数为默认值,第五个参数为使用说明。
1.2.5 验证
在完成了单词格式转换的功能后,已经初步的拥有了一个工具了,现在我们来验证一下功能是否正常, 一般我们拿到一个 CLI 应用程序,我们会先执行 help 来先查看其帮助信息,如下:
$ go run main.go help word
该子命令支持各种单词格式转换,模式如下:
1:全部转大写
2:全部转小写
3:下划线转大写驼峰
4:下划线转小写驼峰
5:驼峰转下划线
Usage:
word [flags]
Flags:
-h, --help help for word
-m, --mode int8 请输入单词转换的模式
-s, --str string 请输入单词内容
手工验证四种单词的转换模式的功能点是否正常,如下:
$ go run main.go word -s=eddycjy -m=1
输出结果: EDDYCJY
$ go run main.go word -s=EDDYCJY -m=2
输出结果: eddycjy
$ go run main.go word -s=eddycjy -m=3
输出结果: Eddycjy
$ go run main.go word -s=EDDYCJY -m=4
输出结果: eDDYCJY
$ go run main.go word -s=EddyCjy -m=5
输出结果: eddy_cjy
1.2.6 小结
作为第一个实战项目,我们基于第三方开源库 Cobra 和标准库 strings、unicode 实现了多种模式的单词转换, 非常简单,也是在日常的工作中较实用的一环,因为我们经常会需要对输入、输出数据进行各类型的转换和拼装。
1.3 便捷的时间工具
平时在查看原始数据时,有时候要看格式化后的个性化时间,又或是直接看时间戳等等,这些都是我们时不时会接触到的。 更甚的是,如果不同系统中的时间格式不一样,比较规则不一样,那你每用一次都要做一轮转换。又有可能是, 你的业务接口的入参开始时间和结束时间是一个时间戳的值,在通常情况下,你是不是要靠外部的一些快捷站点, 又或是内部的 Web 站点去获取、调整呢,这其实还是有些麻烦的,要连上网,要输入站点地址,还要鼠标操作…., 这显然不符合我们的小极客思维,因此在本章节我们将做一个时间相关的工具,尽可能的优化我们日常获取时间的相关手工行为效率。
1.3.1 获取时间
我们在项目的 internal 目录下新建 timer 目录,并新建 time.go 文件,目录结构如下:
├── internal
│ ├── timer
│ │ └── time.go
在 time.go 文件中写入如下代码:
func GetNowTime() time.Time {
return time.Now()
}
我们在 GetNowTime 方法中对标准库 time 的 Now 方法进行了封装,用于返回当前本地时间的 Time 对象, 此处的封装主要是为了便于后续对 Time 对象做进一步的统一处理,因为可能会涉及时区的一些问题处理。
1.3.2 时间推算
接下来针对时间推算,我们继续在 time.go 文件中新增方法,如下:
func GetCalculateTime(currentTimer time.Time, d string) (time.Time, error) {
duration, err := time.ParseDuration(d)
if err != nil {
return time.Time{}, err
}
return currentTimer.Add(duration), nil
}
在上述代码中,我们比较核心的是调用了两个方法来处理,分别是 ParseDuration 和 Add 方法, ParseDuration 方法用于在字符串中解析出 duration(持续时间), 其支持的有效单位有”ns”, “us” (or “µ s”), “ms”, “s”, “m”, “h”,例如:“300ms”, “-1.5h” or “2h45m”。 而在 Add 方法中,我们可以将其返回的 duration 传入,就可以得到当前 timer 时间加上 duration 后所得到的最终时间。
可能会有的人会有疑惑,为什么不直接用 Add 方法来做,还要转多一道 ParseDuration 方法,效率会不会没有那么好, 实际上在我们的这个时间工具中,你预先并不知道他传入的值是什么,因此利用 ParseDuration 方法先处理是最好的办法之一。
如果你预先知道准确的 duration,也不需要适配,那你就可以直接使用 Add 方法和 Duration 类型进行处理,例如:
const (
Nanosecond Duration = 1
Microsecond = 1000 * Nanosecond
Millisecond = 1000 * Microsecond
Second = 1000 * Millisecond
Minute = 60 * Second
Hour = 60 * Minute
)
...
timer.GetNowTime().Add(time.Second * 60)
1.3.3 初始化子命令
在完成了获取时间和推算时间的处理方法后,我们需要将其集成到我们的子命令中,也就是创建项目的 time 子命令, 我们需要项目的 cmd 目录下新建 time.go 文件,新增如下代码:
var calculateTime string
var duration string
var timeCmd = &cobra.Command{
Use: "time",
Short: "时间格式处理",
Long: "时间格式处理",
Run: func(cmd *cobra.Command, args []string) {},
}
完成 time 子命令编写后,再到项目的 cmd/root.go 文件中进行相应的注册即可:
func init() {
rootCmd.AddCommand(wordCmd)
rootCmd.AddCommand(timeCmd)
}
每一个子命令,都是需要到 rootCmd 中进行注册的,否则将无法使用。
1.3.3.1 time now 子命令
接下来针对获取当前时间,我们在 time 子命令下再新增一个 now 子命令,用于处理其具体的逻辑,在 time.go 文件中新增如下代码:
var nowTimeCmd = &cobra.Command{
Use: "now",
Short: "获取当前时间",
Long: "获取当前时间",
Run: func(cmd *cobra.Command, args []string) {
nowTime := timer.GetNowTime()
log.Printf("输出结果: %s, %d", nowTime.Format("2006-01-02 15:04:05"), nowTime.Unix())
},
}
我们在获取当前时间的 Time 对象后,一共输出了两个不同格式的时间,分别如下:
第一个格式:通过调用 Format 方法设定约定的 2006-01-02 15:04:05 格式来进行时间的标准格式化。
第二个格式:通过调用 Unix 方法返回 Unix 时间,就是我们通俗说的时间戳,其值为自 UTC 1970 年 1 月 1 日起经过的秒数。
如果你想要定义其它时间格式的话,标准库 time 中还支持(内部预定义)如下格式:
const (
ANSIC = "Mon Jan _2 15:04:05 2006"
UnixDate = "Mon Jan _2 15:04:05 MST 2006"
RubyDate = "Mon Jan 02 15:04:05 -0700 2006"
RFC822 = "02 Jan 06 15:04 MST"
RFC822Z = "02 Jan 06 15:04 -0700" // RFC822 with numeric zone
RFC850 = "Monday, 02-Jan-06 15:04:05 MST"
RFC1123 = "Mon, 02 Jan 2006 15:04:05 MST"
RFC1123Z = "Mon, 02 Jan 2006 15:04:05 -0700" // RFC1123 with numeric zone
RFC3339 = "2006-01-02T15:04:05Z07:00"
...
)
可以像这样子使用这些预定义格式,例如:
t := time.Now().Format(time.RFC3339)
1.3.3.2 time calc 子命令
接下来针对时间推算的处理,我们在 time 子命令下再新增一个 calc 子命令,在 time.go 文件中继续新增如下代码:
var calculateTimeCmd = &cobra.Command{
Use: "calc",
Short: "计算所需时间",
Long: "计算所需时间",
Run: func(cmd *cobra.Command, args []string) {
var currentTimer time.Time
var layout = "2006-01-02 15:04:05"
if calculateTime == "" {
currentTimer = timer.GetNowTime()
} else {
var err error
space := strings.Count(calculateTime, " ")
if space == 0 {
layout = "2006-01-02"
}
if space == 1 {
layout = "2006-01-02 15:04:05"
// 写成下面这种格式,time.Parse() 会报错
// layout = "2006-01-02 15:04"
}
currentTimer, err = time.Parse(layout, calculateTime)
if err != nil {
t, _ := strconv.Atoi(calculateTime)
currentTimer = time.Unix(int64(t), 0)
}
}
t, err := timer.GetCalculateTime(currentTimer, duration)
if err != nil {
log.Fatalf("timer.GetCalculateTime err: %v", err)
}
log.Printf("输出结果: %s, %d", t.Format(layout), t.Unix())
},
}
在上述代码中,一共支持了三种常用时间格式的处理,分别是:时间戳、2006-01-02 以及 2006-01-02 15:04:05。
在时间格式处理上,我们调用了 strings.Contains 方法,对空格进行了包含判断, 若存在则按既定的 2006-01-02 15:04:05 格式进行格式化,否则以 2006-01-02 格式进行处理,若出现异常错误, 则直接按时间戳的方式进行转换处理。
在最后我们针对 time 子命令进行 now、calc 的子命令和所需的命令行参数进行注册即可,如下:
func init() {
timeCmd.AddCommand(nowTimeCmd)
timeCmd.AddCommand(calculateTimeCmd)
calculateTimeCmd.Flags().StringVarP(&calculateTime, "calculate", "c", "", ` 需要计算的时间,有效单位为时间戳或已格式化后的时间 `)
calculateTimeCmd.Flags().StringVarP(&duration, "duration", "d", "", ` 持续时间,有效时间单位为"ns", "us" (or "µs"), "ms", "s", "m", "h"`)
}
1.3.4 验证
在完成功能开发后,我们将进行功能验证,在下述命令分别获取了当前的时间,以及推算了所传入时间的后五分钟和前两小时,输出结果如下:
$ go run main.go time now
输出结果: 2029-09-04 12:02:33, 1883188953
$ go run main.go time calc -c="2029-09-04 12:02:33" -d=5m
输出结果: 2029-09-04 12:07:33, 1883218053
$ go run main.go time calc -c="2029-09-04 12:02:33" -d=-2h
输出结果: 2029-09-04 10:02:33, 1883210553
需要注意的是,这里的时间我进行了虚构,因此你需要根据本地的实际输出时间进行结果确定和验证。
1.3.5 有没有时区问题
如果你在上一步的验证命令中,没有遇到少了八小时的之类的问题,那你是相对顺利的。但是这也有一个问题, 可能以后你会忽略掉这一个”坑“,那就是时区的问题,实际上在使用标准库 time 时是存在遇到时区问题的风险的, 因此我们需要对这个问题注意,接下来我们将针对这块内容进行介绍,并作出一定的调整和设置。
不同的国家(有时甚至是同一个国家内的不同地区)使用着不同的时区。对于要输入和输出时间的程序来说, 必须对系统所处的时区加以考虑。而在 Go 语言中使用 Location 来表示地区相关的时区,一个 Location 可能表示多个时区。
在标准库 time 上,提供了 Location 的两个实例:Local 和 UTC。Local 代表当前系统本地时区;UTC 代表通用协调时间, 也就是零时区,在默认值上,标准库 time 使用的是 UTC 时区。
1.3.5.1 Local 是如何表示本地时区的
时区信息既浩繁又多变,Unix 系统以标准格式存于文件中,这些文件位于 /usr/share/zoneinfo, 而本地时区可以通过 /etc/localtime 获取,这是一个符号链接,指向 /usr/share/zoneinfo 中某一个时区。 比如我本地电脑指向的是:/var/db/timezone/zoneinfo/Asia/Shanghai。
因此在初始化 Local 时,标准库 time 通过读取/etc/localtime 就可以获取到系统的本地时区,如下:
tz, ok := syscall.Getenv("TZ")
switch {
case !ok:
z, err := loadLocation("localtime", []string{"/etc/"})
if err == nil {
localLoc = *z
localLoc.name = "Local"
return
}
case tz != "" && tz != "UTC":
if z, err := loadLocation(tz, zoneSources); err == nil {
localLoc = *z
return
}
}
1.3.5.2 如何设置时区
既然发现了这个问题,那么有什么办法处理呢,我们可以通过标准库 time 中的 LoadLocation 方法来根据名称获取特定时区的 Location 实例,原型如下:
func LoadLocation(name string) (*Location, error)
在该方法中,如果所传入的 name 是”UTC”或为空,返回 UTC;如果 name 是 “Local”, 返回当前的本地时区 Local;否则 name 应该是 IANA 时区数据库(IANA Time Zone Database,简称 tzdata)里 有记录的地点名(该数据库记录了地点和对应的时区),如 “America/New_York”。
另外要注意的是 LoadLocation 方法所需要的时区数据库可能不是所有系统都有提供,特别是在非 Unix 系统, 此时 LoadLocation 方法会查找环境变量 ZONEINFO 指定目录或解压该变量指定的 zip 文件(如果有该环境变量); 然后查找 Unix 系统约定的时区数据安装位置。最后如果都找不到,就会查找 $GOROOT/lib/time/zoneinfo.zip 里的时区数据库, 简单来讲就是会在不同的约定路径中尽可能的查找到所需的时区数据库。
那么为了保证我们所获取的时间,与我们所期望的时区一致,我们要对获取时间的代码进行修改,设置当前时区为 Asia/Shanghai,修改如下:
func GetNowTime() time.Time {
location, _ := time.LoadLocation("Asia/Shanghai")
return time.Now().In(location)
}
1.3.5.3 要注意的 time.Parse/Format
在前面的实践代码中,我们用到了 time.Format 方法,与此还有一个相对应的方法并没有介绍到它,就是 time.Parse 方法, Parse 方法会解析格式化的字符串并返回它表示的时间值,它非常的常见,并且有一个非常需要注意的点。 首先我们一起看看下面这个示例程序,如下:
func main() {
location, _ := time.LoadLocation("Asia/Shanghai")
inputTime := "2029-09-04 12:02:33"
layout := "2006-01-02 15:04:05"
t, _ := time.Parse(layout, inputTime)
dateTime := time.Unix(t.Unix(), 0).In(location).Format(layout)
log.Printf("输入时间:%s,输出时间:%s", inputTime, dateTime)
}
那么你觉得这个示例程序的输出时间的结果是什么呢,还是 2029-09-04 12:02:33 吗,我们一起来看看最终的输出结果,如下:
输入时间:2029-09-04 12:02:33,输出时间:2029-09-04 20:02:33
从输出结果上来看,输入和输出时间竟然相差了八个小时,这显然是时区的设置问题,但是这里你可能又打起了嘀咕, 明明在调用 Format 方法前我们已经设置了时区…这究竟是为什么呢?
实际上这与 Parse 方法有直接关系,因为 Parse 方法会尝试在入参的参数中中分析并读取时区信息, 但是如果入参的参数没有指定时区信息的话,那么就会默认使用 UTC 时间。因此在这种情况下我们要采用 ParseInLocation 方法, 指定时区就可以解决这个问题,如下:
t, _ := time.ParseInLocation(layout, inputTime, location)
dateTime := time.Unix(t.Unix(), 0).In(location).Format(layout)
也就是所有解析与格式化的操作都最好指定时区信息,否则当你遇到时区问题的时候,并且已经上线,那么后期再进行数据清洗就比较麻烦了。
1.3.5.4 我的系统时区是对的
我们常常会说,程序运行在我的本地是正常的…这个经典答复,在时区上好像又是说的过去。实际上,我们常常在开发时, 用的可能是本地或预装好的开发环境,时区往往都是设置正确(符合我们东八区的需求)的,你可以在本地查看 localtime 文件,如下:
$ cat /etc/localtime
...
CST-8
你会发现实际上输出的就是 CST-8,也就是中国标准时间,UTC+8,因此你在本地不需要设置时区,你也不会发现异样。 但是,到了其它部署环境就不一定了,举一个例子,在 Kubernetes、Docker 盛行的现在, 你被编译后的 Go 程序很有可能就运行在 Docker 中,假设该镜像并没有经过时区调整,你在编译和启动时也没有指定时区, 那么你就会遇到很多问题,像是日志的写入时间不对,标准库 time 的转换存在问题, 又或是数据库写入的时候有问题…如果是遇到事故时,才察觉到这个问题,那就非常麻烦了。
因此确保你的所有部署环境的系统时区是正确的,这个能够给你基本的保障。
但你以为这就万无一失了吗,并不,例如当你所部署的环境并不存在所设置时区的时区数据库时, 也会导致 fallback 到 UTC 时区,因此与对接的运维人员确保部署时区的各方面设置是非常重要的。
1.3.6 为什么是 2006-01-02 15:04:05
另外可能你已经注意到 2006-01-02 15:04:05 这个格式字符串了,这是很多刚学 Go 语言的小伙伴会感到疑惑的点之一, 它是什么,怎么和其它语言的表示方式不一样,为什么是 2006-01-02 15:04:05,这是随便写的时间点吗, 甚至还曾经有传言说这是 Go 语言的诞生时间…
实际上,2006-01-02 15:04:05 是一个参考时间的格式,也就是其它语言中 Y-m-d H:i:s 格式, 在功能上用于时间的格式化处理,这个我们在前面章节中已经进行过验证。
那么为什么要用 2006-01-02 15:04:05 呢,其实这些”数字“是有意义的,在 Go 语言中强调必须显示参考时间的格式, 因此每个布局字符串都是一个时间戳的表示,并非随便写的时间点,如果你觉得记忆困难,可参见官方例子中的如下方式:
Jan 2 15:04:05 2006 MST
1 2 3 4 5 6 -7
而转换到 2006-01-02 15:04:05 的时间格式,我们也可以将其记忆为 2006 年 1 月 2 日 3 点 4 分 5 秒。
1.3.7 小结
在 Go 语言中,标准库 time 的各类问题或疑问,是很多刚入门的小伙伴会疑惑的, 尤其是在时区设置、格式化时间、2006-01-02 15:04:05 的问题更是来一个,踩一个坑,也有很多的讲解不清的。
因此在本章节,我们在基于标准库 time 完成的时间工具的需求上,还进行了进一步的说明, 争取让你能够对常见问题心里有底,知道为什么,是怎么出现的。
1.4 SQL 语句到结构体的转换
在项目初始化或添加新数据表时,我们常常需要添加模型(Model)结构,这时就会遇到一个新问题,即需要写Model结构体。 如果是手写Model结构体,则太低效了,因此本节我们实现数据库表到Go结构体的转换。
从本节起,我们将用到 MySQL 数据库,笔者的 MySQL 数据库版本为 5.7。 读者需了解MySQL数据库的一些基本知识,并注意MySQL的安装,以保证对本书后续内容的正常学习。
1.4.1 需要转换的数据结构
需要转换的数据结构其实是MySQL数据库中的表结构,本质上是SQL语句,例子如下:
CREATE TABLE `blog_tag` (
`id` int(10) unsigned NOT NULL AUTO_INCREMENT,
`name` varchar(100) DEFAULT '' COMMENT '标签名称',
`created_on` int(10) unsigned DEFAULT '0' COMMENT '创建时间',
`created_by` varchar(100) DEFAULT '' COMMENT '创建人',
`modified_on` int(10) unsigned DEFAULT '0' COMMENT '修改时间',
`modified_by` varchar(100) DEFAULT '' COMMENT '修改人',
`deleted_on` int(10) unsigned DEFAULT '0' COMMENT '删除时间',
`is_del` tinyint(3) unsigned DEFAULT '0' COMMENT '是否删除 0 为未删除、1 为已删除',
`state` tinyint(3) unsigned DEFAULT '1' COMMENT '状态 0 为禁用、1 为启用',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=4 DEFAULT CHARSET=utf8mb4 COMMENT='标签管理';
我们希望最终能得到表中的所有列信息,并根据所有列信息生成所期望的结构体。
1.4.2 生成结构体
是不是要去指定的数据库里先遍历一遍所有的表,然后一个个分析表的SQL语句,接着再进行转换呢?其实不需要那么麻烦, 因为在 MySQL 数据库中,有一个神奇的“东西”,那就是 information_schema 数据库。 它可以非常便捷地帮助我们实现这个功能,下面就来了解一下其所提供的功能。
1.确定数据源
(1)information_schema数据库。
information_schema数据库在MySQL中提供了对数据库元数据的访问,可以获得MySQL服务器自身相关的信息, 如数据库、表名称、列数据类型、访问权限等。
- SCHEMATA:提供有关数据库的信息,可与SHOW DATABASES语句等效。
- COLUMNS:提供有关表中列的信息,可与SHOW COLUMNS语句等效。
- TABLES:提供有关数据库中表的信息,可与SHOW FULL TABLES语句等效。
- STATISTICS:提供有关表索引的信息,可与SHOW INDEX语句等效。
- USER_PRIVILEGES:提供有关全局权限的信息,从mysql.user系统表中获取值。
- CHARACTER_SETS:提供数据库可用字符集的信息,可与SHOW CHARACTER SET语句等效。
(2)COLUMNS表。
COLUMNS表提供了整个数据库中列的信息,其包含以下几个常用字段。
- TABLE_NAME:列所属的表名称。
- COLUMN_NAME:列的名称。
- COLUMN_DEFAULT:列的默认值。
- IS_NULLABLE:列是否允许为NULL,值为YES或NO。
- DATA_TYPE:列的数据类型,仅包含类型信息。
- COLUMN_TYPE:列的数据类型,包含类型名称和可能的其他信息。例如,精度、长度、是否无符号等。
- COLUMN_KEY:列是否被索引。
- COLUMN_COMMENT:列的注释信息。
在Go语言中,一个结构体的最小包含为字段名和字段类型。实际上,可以看到COLUMNS表中基本都具备了, 它能够直接帮助程序进行表到结构体的映射转换。
2.转换和生成
在确定了获取表结构的列信息数据源后,接下来需要思考的问题就是如何转换并生成 Go结构体。在把表转为Go结构体时, 数据类型比较简单,一般来说,不存在过多层级Go结构体的问题,也就是说,不会出现如下所示的多层级嵌套的情况:
type GoModel struct {
Go []Go
}
type Go struct {
Goroutine []Goroutine
}
type Goroutine struct {}
因此,在面对这类数据类型比较简单的基本转换时,是不必大费周章的做递归循环嵌套判断的,可以直接使用Go的template实现相关逻辑,非常的方便。
(1)template.
template是Go语言的文本模板引擎,它提供了两个标准库。这两个标准库使用了同样的接口,但功能略有不同,具体如下:
- text/template:基于模板输出文本内容。
- html/template:基于模板输出安全的HTML格式的内容,可以理解为其进行了转义,以避免受某些注入攻击。
下面我们对template进行一个快速入门,以便更好地理解和使用它,示例代码如下:

const templateText = `
Output 0: \{\{title .Name1\}\}
Output 1: \{\{title .Name2\}\}
Output 2: \{\{.Name3 | title\}\}
`
func main() {
funcMap := template.FuncMap{"title": strings.Title}
tpl := template.New("go-programming-tour)
tpl, _ = tpl.Funcs(funcMap).Parse(templateText)
data := map[string]string{
"Name1": "go",
"Name2": "programming",
"Name3": "tour",
}
_ = tpl.Execute(os.Stdout, data)
}
输出结果如下:
Output 0: Go
Output 1: Programming
Output 2: Tour
在上述代码中,首先调用标准库text/template中的New方法,其根据我们给定的名称标识创建了一个全新的模板对象。 接下来调用Parse方 法,将常量templateText(预定义的待解析模板)解析为当前文本模板的主体内容。 最后调用 Execute 方法,进行模板渲染。简单来说,就是将传入的data动态参数渲染到对应的模板标识位上。 因为我们将Execute方法的io.Writer指定到了 os.Stdout中,所以其最终输出到标准控制台中。
(2)template模板定义。
前文提到了预定义的待解析模板和模板的标识位,下面对它们进行具体讲解。
- 双层大括号:也就是标识符,在template中,所有的动作(Actions)、数据评估(Data Evaluations)、 控制流转都需要用标识符双层大括号包裹,其余的模板内容均全部原样输出。
- 点(DOT):会根据点(DOT)标识符进行模板变量的渲染,其参数可以为任何值,但特殊的复杂类型需进行特殊处理。 例如,当为指针时,内部会在必要时自动表示为指针所指向的值。如果执行结果生成了一个函数类型的值, 如结构体的函数类型字段,那么该函数不会自动调用。
- 函数调用:在前面的代码中,通过FuncMap方法注册了名title的自定义函数。
在模板渲染中一共用了两类处理方法,即使用
\{\{title.Name1\}\}和管道符(|)对.Name3进行处理。在template中, 会把管道符前面的运算结果作为参数传递给管道符后面的函数,最终,命令的输出结果就是这个管道的运算结果。
1.4.3 表到结构体的转换
在项目的internal下新建sql2struct目录,用于存储表转为结构体的工具库代码,目录结构如下:
├── internal
│ └── sql2struct
1.连接MySQL数据库
想要获取表中列的信息,即需要访问information_schema数据库中的COLUMNS表,在程序中进行连接、查询、数据组装等处理, 那么就需要在项目的 sql2struct 目录下新建 mysql.go文件,写入如下声明代码:
type DBModel struct {
DBEngine *sql.DB
DBInfo *DBInfo
}
type DBInfo struct {
DBType string
Host string
UserName string
Password string
Charset string
}
type TableColumn struct {
ColumnName string
DataType string
IsNullable string
ColumnKey string
ColumnType string
ColumnComment string
}
func NewDBModel(info *DBInfo) *DBModel {
return &DBModel{DBInfo: info}
}
上述代码声明了初始化方法 NewDBModel 和三个核心的结构体对象。DBModel 是整个数据库连接的核心对象, 结构体DBInfo用于存储连接MySQL的一些基本信息,TableColumn用于存储COLUMNS表中我们需要的一 些字段,其字段含义在1.4.2节曾介绍过。
下面编写连接MySQL数据库的具体方法,在mysql.go文件中新增如下代码:
package sql2struct
import (
"database/sql"
"errors"
"fmt"
_ "github.com/go-sql-driver/mysql"
)
...
func (m *DBModel) Connect() error {
var err error
s := "%s:%s@tcp(%s)/information_schema?" + "charset=%s&parseTime=True&loc=Local"
dsn := fmt.Sprintf(
s,
m.DBInfo.UserName,
m.DBInfo.Password,
m.DBInfo.Host,
m.DBInfo.Charset,
)
m.DBEngine, err = sql.Open(m.DBInfo.DBType, dsn)
if err != nil {
return err
}
return nil
}
在连接MySQL数据库时使用的是标准库database/sql的Open方法,第一个参数为驱动名称(如mysql),
第二个参数为驱动连接数据库的连接信息。需要注意的是,在程序中必须导入github.com/go-sql-driver/mysql进行MySQL驱动程序的初始化,否则会出现错误。
2.获取表中列的信息
在编写完连接MySQL数据库的连接方法后,由于需要针对COLUMNS表进行查询和数据组装,所以继续在mysql.go文件中新增如下代码:
func (m *DBModel) GetColumns(dbName, tableName string) ([]*TableColumn, error) {
query := "SELECT COLUMN_NAME, DATA_TYPE, COLUMN_KEY, " +
"IS_NULLABLE, COLUMN_TYPE, COLUMN_COMMENT " +
"FROM COLUMNS WHERE TABLE_SCHEMA = ? AND TABLE_NAME = ? "
rows, err := m.DBEngine.Query(query, dbName, tableName)
if err != nil {
return nil, err
}
if rows == nil {
return nil, errors.New("没有数据")
}
defer rows.Close()
var columns []*TableColumn
for rows.Next() {
var column TableColumn
err := rows.Scan(&column.ColumnName, &column.DataType, &column.ColumnKey, &column.IsNullable, &column.ColumnType, &column.ColumnComment)
if err != nil {
return nil, err
}
columns = append(columns, &column)
}
return columns, nil
}
3.表字段类型映射
由于DataType字段的类型与Go 结构体中的类型不是完全一致的(如varchar、longtext、TimeStamp 等), 因此需要做一层简单的类型转换。这里用的是最简单的枚举,然后再用 map作映射获取。继续在mysql.go中声明全局变量,代码如下:
var DBTypeToStructType = map[string]string{
"int": "int32",
"tinyint": "int8",
"smallint": "int",
"mediumint": "int64",
"bigint": "int64",
"bit": "int",
"bool": "bool",
"enum": "string",
"set": "string",
"varchar": "string",
"char": "string",
"tinytext": "string",
"mediumtext": "string",
"text": "string",
"longtext": "string",
"blob": "string",
"tinyblob": "string",
"mediumblob": "string",
"longblob": "string",
"date": "time.Time",
"datetime": "time.Time",
"timestamp": "time.Time",
"time": "time.Time",
"float": "float64",
"double": "float64",
}
这里并没有把所有类型的代码段都展示出来,更多代码可到线上示例代码处获取。
4.模板对象声明
在编写完数据库相关的查询、映射的方法后,接下来就需要把得到的列信息按照特定的规则转为Go结构体。 这里采用的是模板渲染的方案,在项目的sql2struct目录下新建template.go文件,写入如下预定义模板:

package sql2struct
import (
"fmt"
"os"
"text/template"
"github.com/go-programming-tour-book/tour/internal/word"
)
const strcutTpl = `type {\{.TableName | ToCamelCase}\} struct {
{\{range .Columns}\} {\{ $length := len .Comment}\} {\{ if gt $length 0 }\}// {\{.Comment}\} {\{else}\}// {\{.Name}\} {\{ end }\}
{\{ $typeLen := len .Type }\} {\{ if gt $typeLen 0 }\}{\{.Name | ToCamelCase}\} {\{.Type}\} {\{.Tag}\}{\{ else }\}{\{.Name}\}{\{ end }\}
{\{end}\}}
func (model {\{.TableName | ToCamelCase}\}) TableName() string {
return "{\{.TableName}\}"
}`
在上述预定义模板中,其基本结构由一个Go结构体(type struct)和其所属的TableName方法组成,生成后的原型大致如下:
type 大写驼峰的表名称 struct {
// 注释
字段名 字段类型
// 注释
字段名 字段类型
...
}
func (model 大写驼峰的表名称) TableName() string {
return "表名称"
}
在定义完预定义模板后,我们需要对后续模板渲染对象进行声明,继续在template.go文件中写入如下代码:
type StructTemplate struct {
strcutTpl string
}
type StructColumn struct {
Name string
Type string
Tag string
Comment string
}
type StructTemplateDB struct {
TableName string
Columns []*StructColumn
}
func NewStructTemplate() *StructTemplate {
return &StructTemplate{strcutTpl: strcutTpl}
}
上述代码一共定义了三个结构体,分别是承担主轴的 StructTemplate、StructColumn 和StructTemplateDB。 StructColumn 用来存储转换后的 Go 结构体中的所有字段信息,StructTemplateDB用来存储最终用于渲染的模板对象信息。
5.模板渲染
前文代码中的StructColumn和StructTemplateDB结构体,实际上对应的是不同阶段的模板对象信息。 下面围绕这两者编写相关方法。打开template.go文件,写入如下代码:
func (t *StructTemplate) AssemblyColumns(tbColumns []*TableColumn) []*StructColumn {
tplColumns := make([]*StructColumn, 0, len(tbColumns))
for _, column := range tbColumns {
tag := fmt.Sprintf("`"+"json:"+"\"%s\""+"`", column.ColumnName)
tplColumns = append(tplColumns, &StructColumn{
Name: column.ColumnName,
Type: DBTypeToStructType[column.DataType],
Tag: tag,
Comment: column.ColumnComment,
})
}
return tplColumns
}
在上述代码中,对通过查询COLUMNS表所组装得到的tbColumns进行进一步的分解和转换。 例如,数据库类型到Go结构体的转换和对JSON Tag的处理,都在这一层完成了。
在处理完模板对象后,接下来对模块渲染的自定义函数和模板对象进行处理,继续写入如下代码:
func (t *StructTemplate) Generate(tableName string, tplColumns []*StructColumn) error {
tpl := template.Must(template.New("sql2struct").Funcs(template.FuncMap{
"ToCamelCase": word.UnderscoreToUpperCamelCase,
}).Parse(t.strcutTpl))
tplDB := StructTemplateDB{
TableName: tableName,
Columns: tplColumns,
}
err := tpl.Execute(os.Stdout, tplDB)
if err != nil {
return err
}
return nil
}
在上述代码中,首先声明了一个名为 sql2struct 的新模板对象,接着定义了自定义函数ToCamelCase, 并与word.UnderscoreToUpperCamelCase方法进行了绑定,最后组装符合预定义模板的模板对象,再调用Execute方法进行渲染。
1.4.4 初始化子命令
下面将其集成到我们的子命令中。打开项目的cmd目录,新建sql.go文件。
首先声明7个cmd全局变量,用于接收外部的命令行参数,新增代码如下:
package cmd
import (
"log"
"github.com/go-programming-tour-book/tour/internal/sql2struct"
"github.com/spf13/cobra"
)
var username string
var password string
var host string
var charset string
var dbType string
var dbName string
var tableName string
分别用于指定数据库的账号、密码、HOST、编码、数据库类型、数据库名称及表名称。 接下来定义其对应的子命令,继续在sql.go文件中写入如下代码:
var sqlCmd = &cobra.Command{
Use: "sql",
Short: "sql转换和处理",
Long: "sql转换和处理",
Run: func(cmd *cobra.Command, args []string) {},
}
var sql2structCmd = &cobra.Command{
Use: "struct",
Short: "sql转换",
Long: "sql转换",
Run: func(cmd *cobra.Command, args []string) {
dbInfo := &sql2struct.DBInfo{
DBType: dbType,
Host: host,
UserName: username,
Password: password,
Charset: charset,
}
dbModel := sql2struct.NewDBModel(dbInfo)
err := dbModel.Connect()
if err != nil {
log.Fatalf("dbModel.Connect err: %v", err)
}
columns, err := dbModel.GetColumns(dbName, tableName)
if err != nil {
log.Fatalf("dbModel.GetColumns err: %v", err)
}
template := sql2struct.NewStructTemplate()
templateColumns := template.AssemblyColumns(columns)
err = template.Generate(tableName, templateColumns)
if err != nil {
log.Fatalf("template.Generate err: %v", err)
}
},
}
在上述代码中,声明了sql子命令和sql子命令对应的子命令struct, 并在sql2structCmd中完成了对数据库的查询、模板对象的组装、渲染等动作的流转, 相当于一个控制器。这部分逻辑也可以抽离为独立的一层进行调用,根据具体情况编写即可。
最后进行默认的cmd初始化动作和命令行参数的绑定,继续在sql.go文件中写入如下代码:
func init() {
sqlCmd.AddCommand(sql2structCmd)
sql2structCmd.Flags().StringVarP(&username, "username", "", "", "请输入数据库的账号")
sql2structCmd.Flags().StringVarP(&password, "password", "", "", "请输入数据库的密码")
sql2structCmd.Flags().StringVarP(&host, "host", "", "127.0.0.1:3306", "请输入数据库的HOST")
sql2structCmd.Flags().StringVarP(&charset, "charset", "", "utf8mb4", "请输入数据库的编码")
sql2structCmd.Flags().StringVarP(&dbType, "type", "", "mysql", "请输入数据库实例类型")
sql2structCmd.Flags().StringVarP(&dbName, "db", "", "", "请输入数据库名称")
sql2structCmd.Flags().StringVarP(&tableName, "table", "", "", "请输入表名称")
}
在完成sql2structCmd子命令的注册后,必须将sqlCmd注册到root.go中,代码如下:
func init() {
...
rootCmd.AddCommand(sqlCmd)
}
1.4.5 验证
在编写完程序后,进行转换的手动验证,代码如下:
go run main.go sql struct --username 数据库的账号 --password 数据库的密码 --db=数据库名称 --table "需要转换的表名"
输出:
type BlogTag struct {
// id
Id int32 `json:"id"`
// 标签名称
Name string `json:"name"`
// 创建时间
CreatedOn int32 `json:"created_on"`
// 创建人
CreatedBy string `json:"created_by"`
// 修改时间
ModifiedOn int32 `json:"modified_on"`
// 修改人
ModifiedBy string `json:"modified_by"`
// 删除时间
DeletedOn int32 `json:"deleted_on"`
// 是否删除 0 为未删除、1 为已删除
IsDel int8 `json:"is_del"`
// 状态 0 为禁用、1 为启用
State int8 `json:"state"`
}
func (model BlogTag) TableName() string {
return "blog_tag"
}
这里用的是1.4.1节提到的示例表结构,读者可以根据实际数据库中存在的表进行转换, 若遇到工具中并没有完美支持的情况,也可以自行尝试改写。
1.4.6 小结
本节首先访问了MySQL数据库中的information_schema数据库,读取了COLUMNS表中对应的所需表的列信息,
并基于标准库database/sql和text/template实现了表列信息到Go语言结构体的转换。
此后再新建表时,只需调用该工具,直接转换就可以获取对应的模型结构了,非常方便。
第二章 HTTP 应用
https://ibaiyang.github.io/blog/golang/2021/10/31/Go-语言编程之旅-第二章-HTTP-应用.html
2.1 开启博客之路
2.2 进行项目设计
2.3 编写公共组件
2.4 生成接口文档
2.5 为接口做参数校验
2.6 模块开发:标签管理
2.7 上传图片和文件服务
2.8 对接口进行访问控制
2.9 应用中间件
2.10 进行链路追踪
2.11 应用配置
2.12 应用编译
2.13 优雅重启和停止
2.14 思考
第三章 RPC 应用
https://ibaiyang.github.io/blog/golang/2021/11/01/Go-语言编程之旅-第三章-RPC-应用.html
3.1 遨游 gRPC 和 Protobuf
3.2 Protobuf 的使用和了解
3.3 gRPC 的使用和了解
3.4 运行一个 gRPC 服务
3.5 进行服务间内调
3.6 同时提供 HTTP 接口
3.7 生成接口文档
3.8 拦截器介绍和实际使用
3.9 Metadata 和 RPC 自定义认证
3.10 进行链路追踪
3.11 服务注册和发现
3.12 实现自定义的 protoc 插件
3.13 对接口进行版本管理
3.14 思考
第四章 Websocket 应用
https://ibaiyang.github.io/blog/golang/2021/11/02/Go-语言编程之旅-第四章-Websocket-应用.html
4.1 基于 TCP 的聊天室
4.2 WebSocket 介绍、握手协议和细节
4.3 聊天室需求分析和设计
4.4 实现聊天室:项目组织和基础代码框架
4.5 实现聊天室:核心流程
4.6 实现聊天室:广播器
4.7 非核心功能
4.8 关键性能分析和优化
4.9 Nginx 部署
4.10 总结
第五章 进程内缓存
https://ibaiyang.github.io/blog/golang/2021/11/02/Go-语言编程之旅-第五章-进程内缓存.html
5.1 缓存简介
5.2 缓存淘汰算法
5.3 实现一个进程内缓存
5.4 缓存的性能和优化思路
5.5 高性能缓存库:BigCache
5.6 进程内缓存的优化版
第六章 Go 语言中的大杀器
https://ibaiyang.github.io/blog/golang/2021/11/02/Go-语言编程之旅-第六章-Go-语言中的大杀器.html
6.1 Go 大杀器之性能剖析 PProf(上)
6.2 Go 大杀器之性能剖析 PProf(下)
6.3 Go 大杀器之跟踪剖析 trace
6.4 用 GODEBUG 看调度跟踪
6.5 用 GODEBUG 看 GC
6.6 Go 进程诊断工具 gops
6.7 公开和发布度量指标
6.8 逃逸分析:变量在哪儿
附录
https://ibaiyang.github.io/blog/golang/2021/11/02/Go-语言编程之旅-附录.html
附录 A:Go Modules 终极入门
附录 B:Goroutine 与 panic、recover 的小问题
附录 C:Go 在容器运行时要注意这个细节
附录 D:让 Go panic 的十种方法
参考资料
Go语言编程之旅:一起用Go做项目 https://golang2.eddycjy.com/
煎鱼github https://github.com/eddycjy
Go 语言编程之旅:一起用 Go 做项目 github https://github.com/go-programming-tour-book
Gin实践 https://github.com/EDDYCJY/go-gin-example/blob/master/README_ZH.md
Go Gin Example https://github.com/EDDYCJY/go-gin-example/blob/master/README_ZH.md
Go Gin Example github project https://github.com/eddycjy/go-gin-example
Gin实践 的连载 https://eddycjy.com/tags/gin/
电子书 https://m.zhangyue.com/readbook/12307188/2.html?p2=104155
MySQL 中的 information_schema 数据库 https://blog.csdn.net/kikajack/article/details/80065753