- 正文
- 参考资料
正文
一、golang介绍
1. 语言介绍
Go 是一个开源的编程语言,它能让构造简单、可靠且高效的软件变得容易。
Go是从2007年末由Robert Griesemer, Rob Pike, Ken Thompson主持开发,后来还加入了Ian Lance Taylor, Russ Cox等人, 并最终于2009年11月开源,在2012年早些时候发布了Go 1稳定版本。现在Go的开发已经是完全开放的,并且拥有一个活跃的社区。
Go 语言是谷歌为充分利用现代硬件性能又兼顾开发效率而设计的一种全新语言。
Go 是一种跨平台(Mac OS、Windows、Linux 等)静态编译型语言。拥有媲美 C 语言的强大性能,支持静态类型安全, 在普通计算机上能几秒内快速编译一个大项目,开发效率跟动态语言相差无几。
Go 语言在国内拥有非常活跃的社区、不仅大公司的 Go 项目越来越多,中小公司也都在考虑 Go 的应用。 当前 Go 语言主要应用于后端服务的开发,未来随着 Go 项目的完善,在系统、游戏、UI界面、AI、物联网等领域,都将被广泛使用。
当然 Go 语言有优点也有一些缺点,完美的东西毕竟太少,如果看好 Go 的未来发展,那么不如抛开成见先来体验一番。
2. 特性说明
跨平台即最终可以执行到Windows,Linux,Unix等操作系统;
静态语言:1)编译工具代码感知更友好;2)商业系统大型开发更有保障;3)静态语言相对封闭,第三方开发包侵害性小;
动态语言:1)代码编写更灵活;2)相对代码更简洁;
编译型和非编译型语言
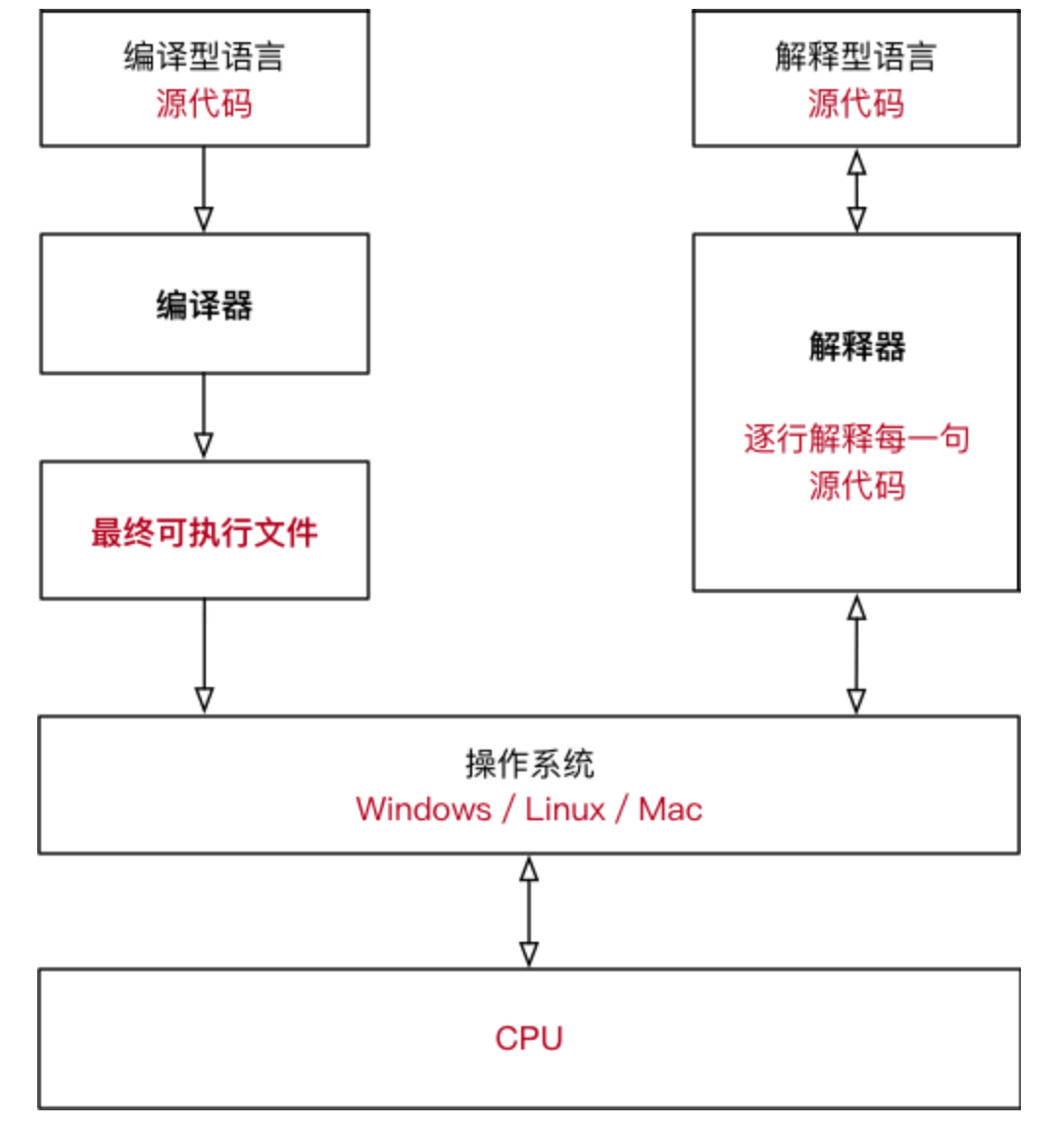
Java 和 C# 比较特殊,源代码需要先转换成一种中间文件(字节码文件),然后再将中间文件拿到虚拟机中执行;
3. 核心开发团队
Ken Thompson(肯·汤普森)

大名鼎鼎、如雷贯耳,Unix操作系统的发明人之一(排在第一号),C语言前身B语言的设计者,UTF-8编码设计者之一,图灵奖得主。 老爷子今年快76岁了(1943年生)。早年一直在贝尔实验室做研究,60多岁的时候被谷歌尊养起来。 2007年,老爷子和Rob Pike、Robert Griesemer一起设计了做出的Go语言。老爷子目前基本不参与Go的设计和开发。
在2011年的一次采访中,老爷子幽默地谈到设计Go语言的初衷是他们很不喜欢C++,因为C++中充满了大量的垃圾特性。
Rob Pike(罗布·派克)

早年在贝尔实验室和Ken Thompson结对编程的小弟,早已成长为业内的领军人物。UTF-8两个发明人之一。Go设计团队第一任老大。 如今也退休并被谷歌尊养起来了。Rob Pike仍旧活跃在各个Go论坛组中,适当地发表自己的意见。
顺便说一句,Go语言的地鼠吉祥物是由Rob Pike的媳妇Renee French设计的。
顺便另说一句,Rob Pike曾获得1980年奥运会射箭银牌。
Robert Griesemer(罗伯特·格瑞史莫)

Go语言三名最初的设计者之一,比较年轻。曾参与V8 JavaScript引擎和Java HotSpot虚拟机的研发。目前主要维护Go白皮书和代码解析器等。
4. 开发的优秀项目
语言的目标是用于项目开发,并能打造出很多优秀的产品。那么,Golang有哪些好像优秀的项目呢?不搜不知道,一搜吓一跳! 列举一下我收集到的golang开发的优秀项目,如下:
-
docker,golang头号优秀项目,通过虚拟化技术实现的操作系统与应用的隔离,也称为容器;
-
kubernetes,是来自 Google 云平台的开源容器集群管理系统。简称k8s,k8s和docker是当前容器化技术的重要基础设施;
-
etcd,一种可靠的分布式KV存储系统,有点类似于zookeeper,可用于快速的云配置;
-
codis,由国人开发提供的一套优秀的redis分布式解决方案;
-
tidb,国内PingCAP 团队开发的一个分布式SQL 数据库,国内很多互联网公司在使用;
-
influxdb,时序型DB,着力于高性能查询与存储时序型数据,常用于系统监控与金融领域;
5. 大厂都在用
- 腾讯蓝鲸
- 百度APP
- 知乎python用go重构
- 字节跳动:抖音
- 七牛云
6 学习方法
- 多写多写再多写………
- 实践:自己设计项目,工作中使用
二、安装部署
go官网: https://golang.google.cn/dl/ ,请选择自己对应的系统
中文社区:https://studygolang.com/dl
1. win环境
1.下载go.{version}.windows-amd64.msi或者go.{version}.windows-amd64.zip包,此次使用go.{version}.windows-amd64.zip包
2.解压压缩文件(这里使用的是D:\Project,后面都基于这个目录)
3.配置环境变量GOPATH和GOROOT
GOPATH 表示当前的工作目录
GOROOT 表示 Go 软件包的安装目录
# 打开cmd设置
set GOPATH=D:\Project\GOPATH
set GOROOT=D:\Project\GO
set PATH=%PATH%;%GOROOT%\bin
当然应该将这些环境变量配置到系统环境变量中
4.此时打开cmd窗口,运行go version即可展示安装golang版本
> go version
go version go1.13.5 windows/amd64
2. linux环境
1.下载linux版本对应安装包,这里使用 go{version}.linux-amd64.tar.gz
2.进入linux对应目录,解压文件到 /usr/local 目录
tar -zxf go{version}.linux-amd64.tar.gz -C /usr/local
3.设置环境变量
使用 vi 在环境变量配置文件 /etc/profile 中增加如下内容:
export PATH=$PATH:/usr/local/go/bin
然后保存文件,并使文件生效
source /etc/profile
定义 GOPATH 环境变量到 workspace 目录
export GOPATH="$HOME/workspace
4.运行go version查看版本信息
# go version
go version go1.15.14 linux/amd64
三、运行第一个程序
1. 运行和编译
当然还是hello word示例。创建文件hello.go,使用文本编辑器编辑,一定要注意文件编码为UTF-8
package main
import "fmt"
func main() {
fmt.Println("Hello World !")
}
保存文件后,运行
>go run hello.go
Hello World !
go编译运行
>go build hello.go
>hello.exe
hello world!
2. 交叉编译
交叉编译linux文件
set CGO_ENABLED=0
set GOOS=linux
set GOARCH=amd64
go build hello.go
交叉编译参数
$GOOS $GOARCH
android arm
darwin 386
darwin amd64
darwin arm
darwin arm64
dragonfly amd64
freebsd 386
freebsd amd64
freebsd arm
linux 386
linux amd64
linux arm
linux arm64
linux ppc64
linux ppc64le
linux mips
linux mipsle
linux mips64
linux mips64le
netbsd 386
netbsd amd64
netbsd arm
openbsd 386
openbsd amd64
openbsd arm
plan9 386
plan9 amd64
solaris amd64
windows 386
windows amd64
四、开发环境IDE安装
工欲善其事,必先利其器
这里推荐两款golang开发工具,一个是goland,一个是VSCode;goland是收费的,收费还是有收费的道理,确实比较好用,个人比较推荐;
VSCode需要安装插件,免费版本,这个是前端开发的利器,go语言开发感觉还是差一点;
1. Goland
JetBrains旗下的产品众多,最出名的就是IDEA,java开发工具;当然PHP,Python,Scala等开发语言,数据库版本都是有的;
JetBrains的官方网站为:https://www.jetbrains.com/go/
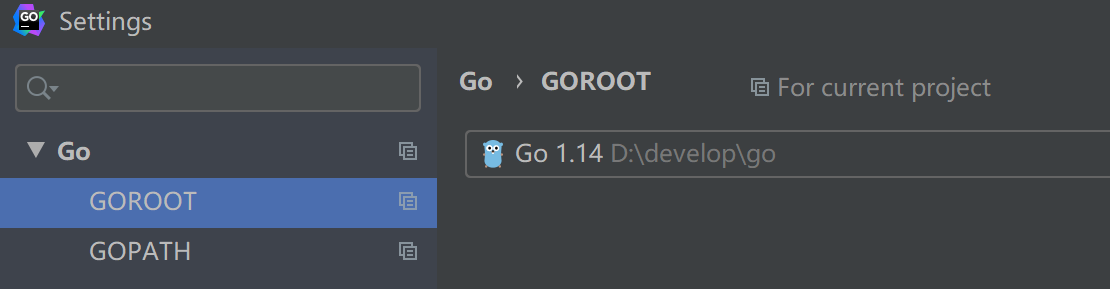
1.首先打开File->Setting或者Ctrl+Alt+S,设置goroot和gopath,默认会获取环境变量配置
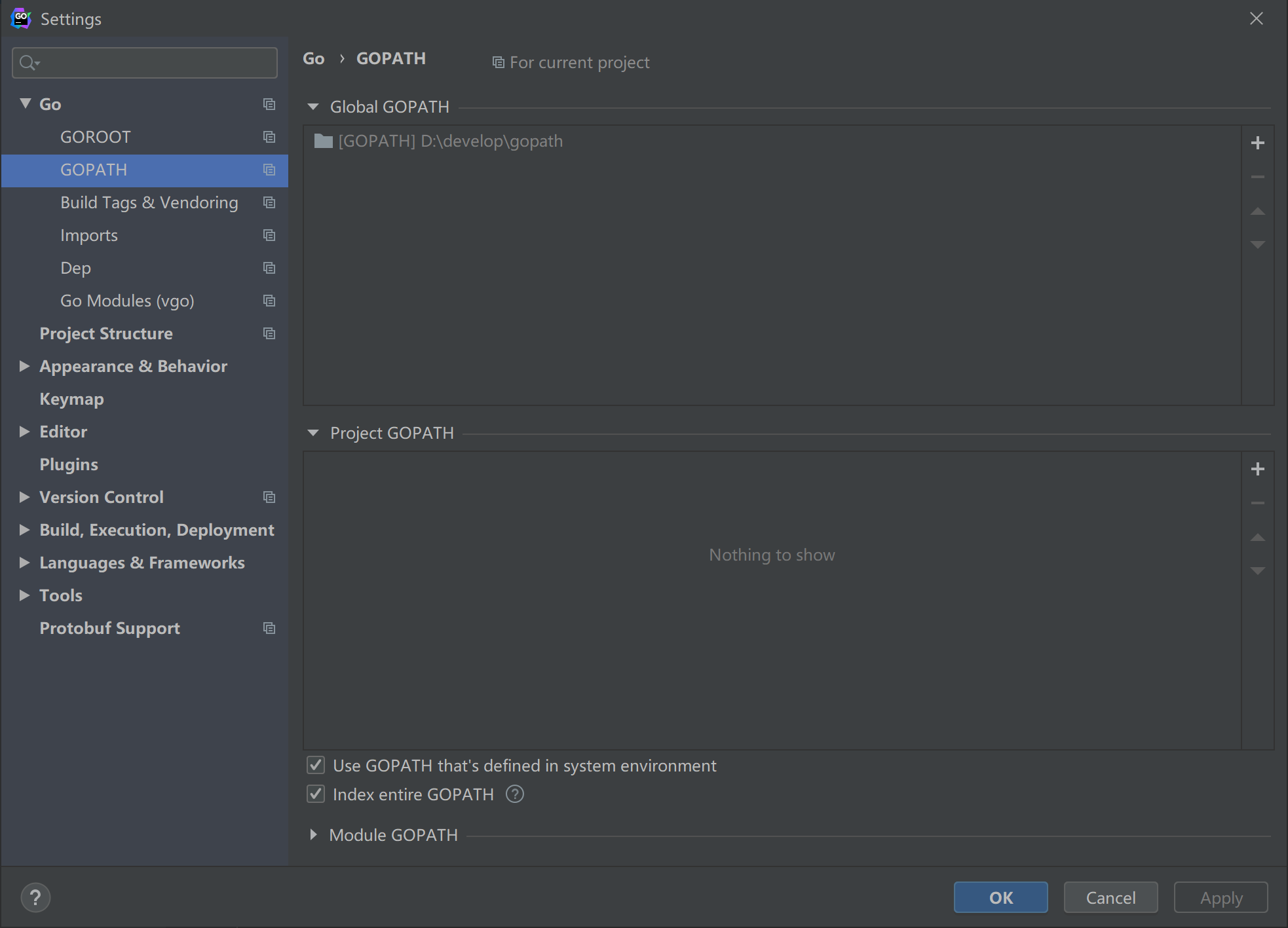
特别提醒 Goland 2020.1版 对 Go版本有要求,不能高于1.14,
不然设置 GOROOT 时会提示:The selected directory is not valid home for SDK。我们就选择1.14版 Go 。
2.如果我们需要使用go modules功能,需要进行开启设置;
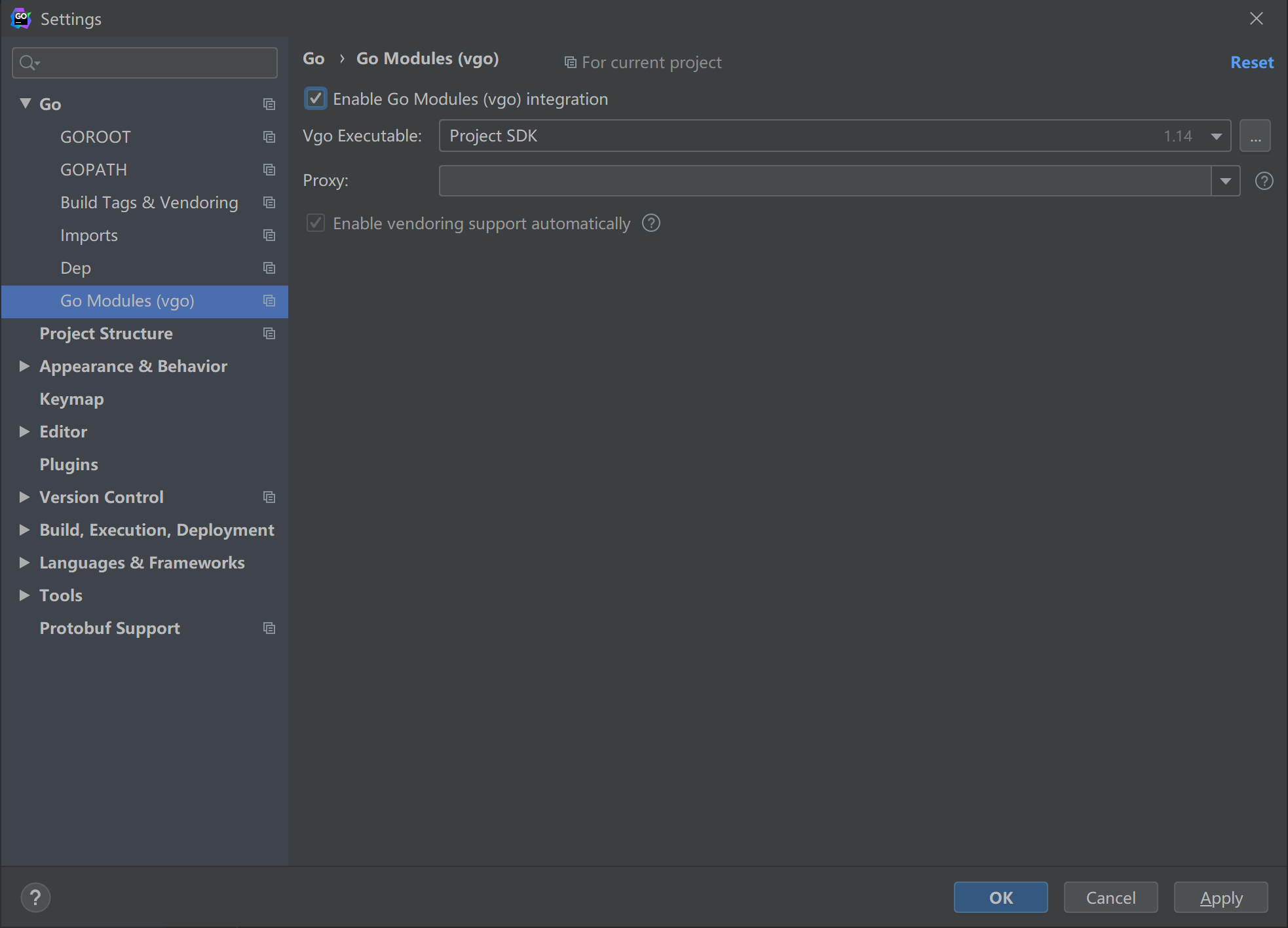
设置 Go Modules 的 Environment 时,是添加KV形式,我们把 GOPROXY=https://goproxy.io,direct 填上去,然后点击 Apply 。
3.最好我们编写helloworld运行
新建项目study1,选择目录
新建go文件
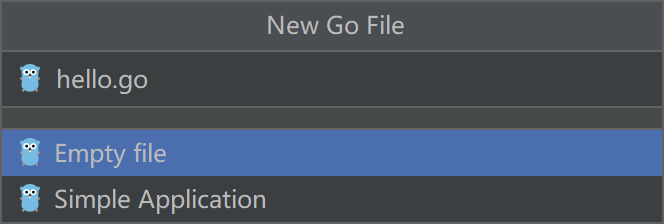
编写 hello.go
package main
import "fmt"
func main(){
fmt.Println("hello world!")
}
最后点击左侧启动运行,或者按Ctrl+Shift+F10运行程序
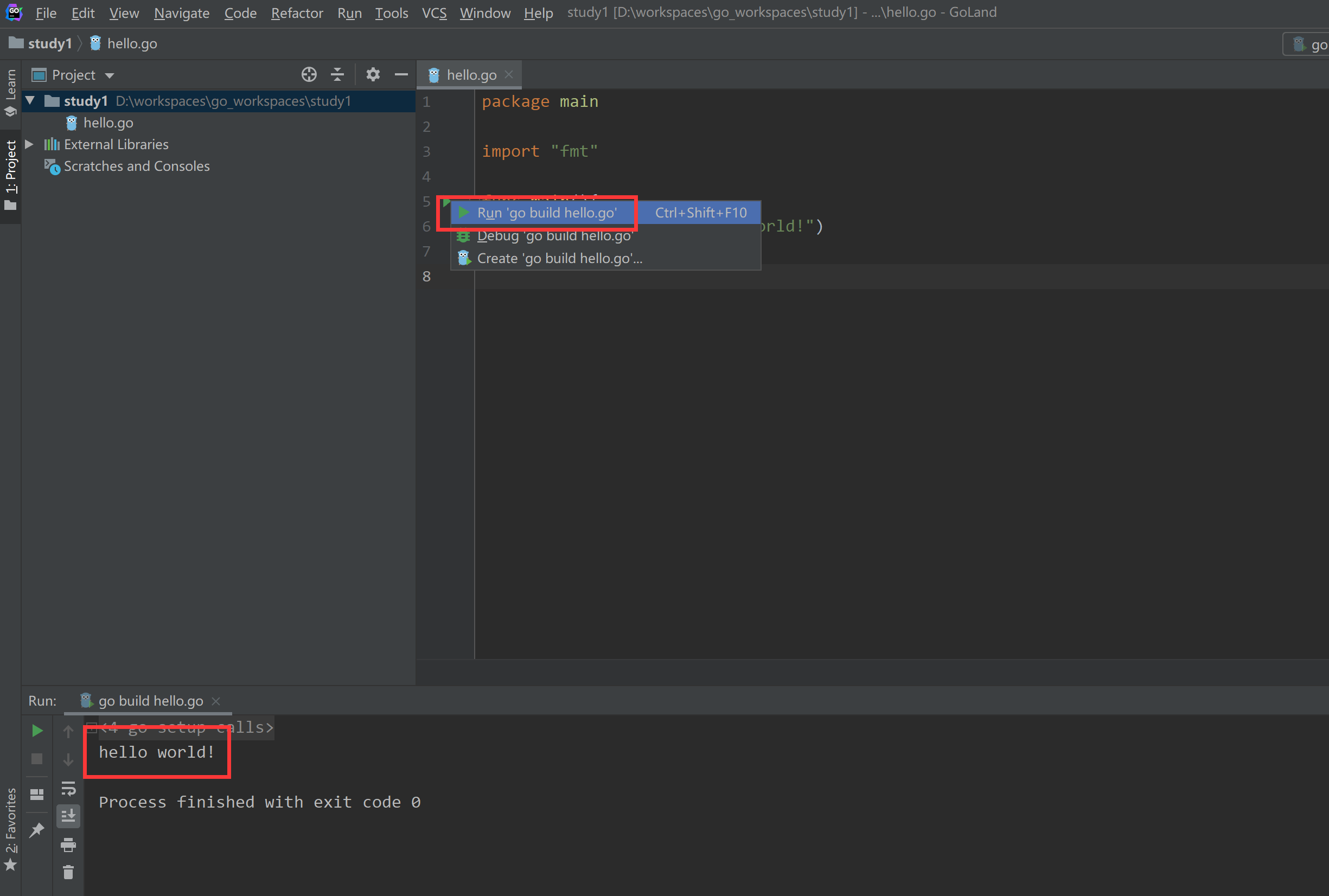
最终我们看到hello world运行成功!
2. Goland 常用快捷键
下面列举了一些 Goland 中经常使用到的快捷键。
文件操作
| 快捷键 | 作用 |
|---|---|
| Ctrl + E | 打开最近浏览过的文件 |
| Ctrl + N | 快速打开某个 struct 结构体所在的文件 |
| Ctrl + Shift + N | 快速打开文件 |
| Shift + F6 | 重命名文件夹、文件、方法、变量名等 |
代码格式化
| 快捷键 | 作用 |
|---|---|
| Ctrl + Alt + L | 格式化代码 |
| Ctrl + 空格 | 代码提示 |
| Ctrl + / | 单行注释 |
| Ctrl + Shift + / | 多行注释 |
| Ctrl + B 或 F4 | 快速跳转到结构体或方法的定义位置(需将光标移动到结构体或方法的名称上) |
| Ctrl +“+ 或 -” | 可以将当前(光标所在位置)的方法进行展开或折叠 |
查找和定位
| 快捷键 | 作用 |
|---|---|
| Ctrl + R | 替换文本 |
| Ctrl + F | 查找文本 |
| Ctrl + Shift + F | 全局查找 |
| Ctrl + G | 显示当前光标所在行的行号 |
| Ctrl + Shift + Alt + N | 查找类中的方法或变量 |
编辑代码
| 快捷键 | 作用 |
|---|---|
| Ctrl + J | 快速生成一个代码片段 |
| Shift+Enter | 向光标的下方插入一行,并将光标移动到该行的开始位置 |
| Ctrl + X | 删除当前光标所在行 |
| Ctrl + D | 复制当前光标所在行 |
| Ctrl + Shift + 方向键上或下 | 将光标所在的行进行上下移动(也可以使用 Alt+Shift+方向键上或下) |
| Alt + 回车 | 自动导入需要导入的包 |
| Ctrl + Shift + U | 将选中的内容进行大小写转化 |
| Alt + Insert | 生成测试代码 |
| Alt + Up/Down | 快速移动到上一个或下一个方法 |
| Ctrl + Alt + Space | 类名或接口名提示(代码提示) |
| Ctrl + P | 提示方法的参数类型(需在方法调用的位置使用,并将光标移动至( )的内部或两侧) |
编辑器相关的快捷键
| 快捷键 | 作用 |
|---|---|
| Ctrl + Alt + left/right | 返回至上次浏览的位置 |
| Alt + left/right | 切换代码视图 |
| Ctrl + W | 快速选中代码 |
| Alt + F3 | 逐个向下查找选中的代码,并高亮显示 |
| Tab | 代码标签输入完成后,按 Tab,生成代码 |
| F2 或 Shift + F2 | 快速定位错误或警告 |
| Alt + Shift + C | 查看最近的操作 |
| Alt + 1 | 快速打开或隐藏工程面板 |
3. VSCode
VSCode 全称 Visual Studio Code,是微软出的一款轻量级代码编辑器,免费、开源而且功能强大。 它支持几乎所有主流的程序语言的语法高亮、智能代码补全、自定义热键、括号匹配、代码片段、代码对比 Diff、GIT 等特性, 支持插件扩展,并针对网页开发和云端应用开发做了优化。
VSCode的官网:https://code.visualstudio.com/
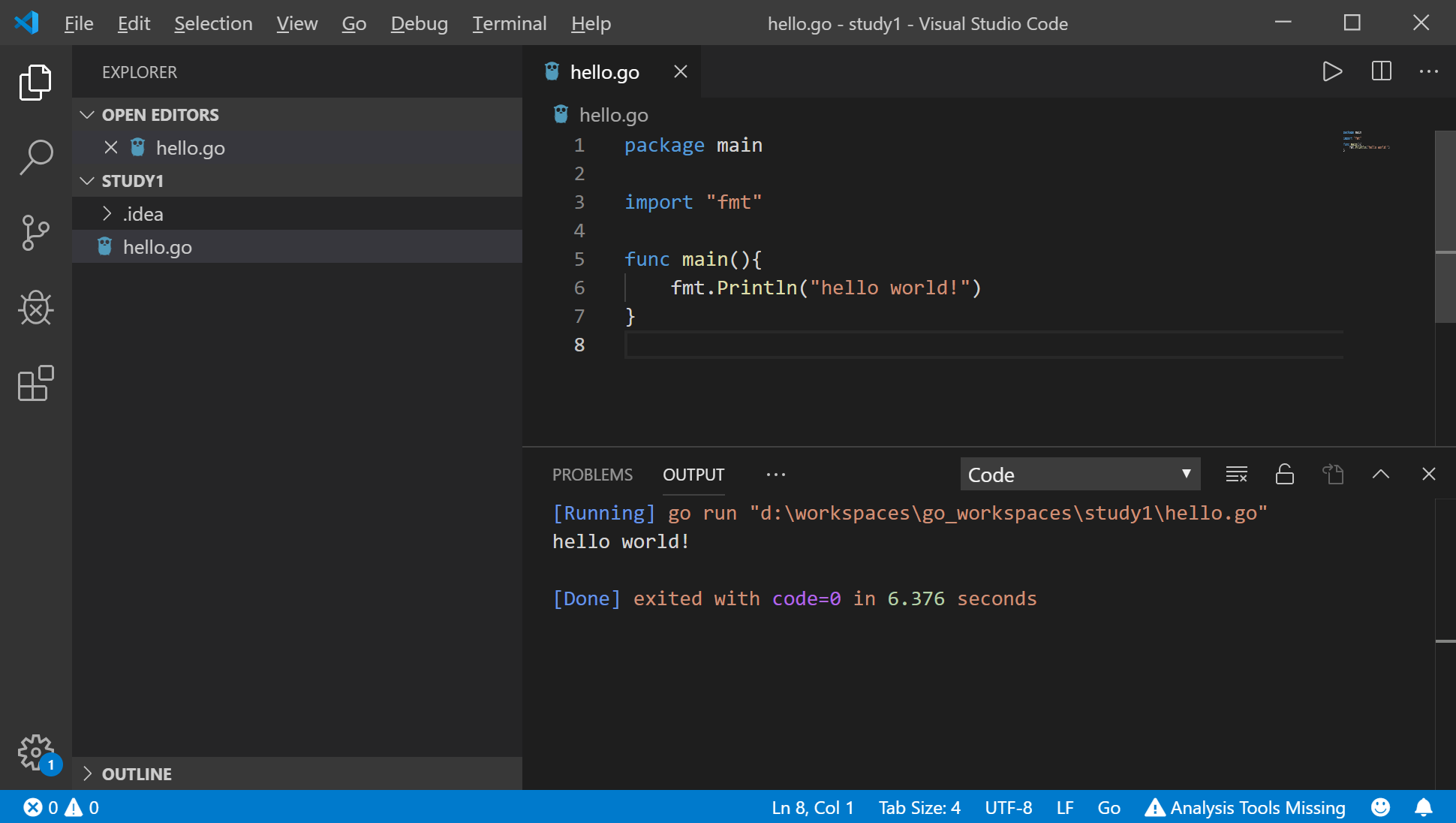
在VSCode中安装Go插件
进入Extensions后直接搜索go,即可安装
在编辑代码时会提示安装一些插件,选择安装即可;
如果没有提示也可以自行安装,大致如下
go get -u -v github.com/bytbox/golint
go get -u -v github.com/golang/tools
go get -u -v github.com/lukehoban/go-outline
go get -u -v github.com/newhook/go-symbols
go get -u -v github.com/josharian/impl
go get -u -v github.com/sqs/goreturns
go get -u -v github.com/cweill/gotests
4. VSCode 常用快捷键
| 快捷键 | 功能 |
|---|---|
| F2 | 重命名符号 |
| Ctrl + L | 选中当前行 |
| Ctrl + / | 添加/关闭行注释 |
| Ctrl + ←/→ | 按单词移动光标 |
| Ctrl + Shift + ←/→ | 按单词进行选中 |
| Shift + Alt +A | 添加/关闭块区域注释 |
| Ctrl + Space | 输入建议 |
| Ctrl + Shift + Space | 参数提示 |
| F12 | 跳转到定义处 |
| Alt + F12 | 代码片段显示定义 |
| Shift + F12 | 显示所有引用 |
| Shift + Alt + F | 格式化代码 |
通用快捷键
| 快捷键 | 作用 |
|---|---|
| Ctrl+Shift+P,F1 | 展示全局命令面板 |
| Ctrl+P | 快速打开最近打开的文件 |
| Ctrl+Shift+N | 打开新的编辑器窗口 |
| Ctrl+Shift+W | 关闭编辑器 |
| Ctrl+, | 首选项 |
| Ctrl+K Ctrl+S | 快捷键设置 |
基础编辑
| 快捷键 | 作用 |
|---|---|
| Ctrl + X | 剪切 |
| Ctrl + C | 复制 |
| Alt + ↑/↓ | 移动行上下 |
| Shift + Alt + ↑/↓ | 在当前行上下复制当前行 |
| Ctrl + Shift + K | 删除行 |
| Ctrl + Enter | 在当前行下插入新的一行 |
| Ctrl + Shift + Enter | 在当前行上插入新的一行 |
| Ctrl + Shift + \ | 匹配花括号的闭合处,跳转 |
| Ctrl + ] / [ | 行缩进 |
| Home / End | 光标跳转到行头/行尾 |
| Ctrl + Home | 跳转到页头 |
| Ctrl + End | 跳转到页尾 |
| Ctrl + ↑/↓ | 行视图上下偏移 |
| Alt + PgUp/PgDown | 屏视图上下偏移 |
| Ctrl + Shift + [ | 折叠区域代码 |
| Ctrl + Shift + ] | 展开区域代码 |
| Ctrl + K Ctrl + [ | 折叠所有子区域代码 |
| Ctrl + k Ctrl + ] | 展开所有折叠的子区域代码 |
| Ctrl + K Ctrl + 0 | 折叠所有区域代码 |
| Ctrl + K Ctrl + J | 展开所有折叠区域代码 |
| Ctrl + K Ctrl + C | 添加行注释 |
| Ctrl + K Ctrl + U | 删除行注释 |
| Ctrl + / | 添加/关闭行注释 |
| Shift + Alt +A | 添加/关闭块区域注释 |
| Alt + Z | 添加/关闭词汇包含 |
导航
| 快捷键 | 作用 |
|---|---|
| Ctrl + T | 列出所有符号 |
| Ctrl + G | 跳转行 |
| Ctrl + P | 跳转文件 |
| Ctrl + Shift + O | 跳转到符号处 |
| Ctrl + Shift + M | 打开问题展示面板 |
| F8 | 跳转到下一个错误或者警告 |
| Shift + F8 | 跳转到上一个错误或者警告 |
| Ctrl + Shift + Tab | 切换到最近打开的文件 |
| Alt + ←/→ | 向后、向前 |
| Ctrl + M | 进入用Tab来移动焦点 |
查询与替换
| 快捷键 | 作用 |
|---|---|
| Ctrl + F | 查询 |
| Ctrl + H | 替换 |
| F3 / Shift + F3 | 查询下一个/上一个 |
| Alt + Enter | 选中所有出现在查询中的 |
| Ctrl + D | 匹配当前选中的词汇或者行 |
| Ctrl + K Ctrl + D | 移动当前选择到下个匹配选择的位置 |
| Alt + C / R / W | 不分大小写/使用正则/全字匹配 |
多行光标操作与选择
| 快捷键 | 作用 |
|---|---|
| Alt + Click | 插入光标-支持多个 |
| Ctrl + Alt + ↑/↓ | 上下插入光标-支持多个 |
| Ctrl + U | 撤销最后一次光标操作 |
| Shift + Alt + I | 插入光标到选中范围内所有行结束符 |
| Ctrl + L | 选中当前行 |
| Ctrl + Shift + L | 选择所有出现在当前选中的行-操作 |
| Ctrl + F2 | 选择所有出现在当前选中的词汇-操作 |
| Shift + Alt + → | 从光标处扩展选中全行 |
| Shift + Alt + ← | 收缩选择区域 |
| Shift + Alt + (drag mouse) | 鼠标拖动区域,同时在多个行结束符插入光标 |
| Ctrl + Shift + Alt + (Arrow Key) | 也是插入多行光标的[方向键控制] |
| Ctrl + Shift + Alt + PgUp/PgDown | 也是插入多行光标的[整屏生效] |
丰富的语言操作
| 快捷键 | 作用 |
|---|---|
| Ctrl + Space | 输入建议[智能提示] |
| Ctrl + Shift + Space | 参数提示 |
| Tab | Emmet指令触发/缩进 |
| Shift + Alt + F | 格式化代码 |
| Ctrl + K Ctrl + F | 格式化选中部分的代码 |
| F12 | 跳转到定义处 |
| Alt + F12 | 代码片段显示定义 |
| Ctrl + K F12 | 在其他窗口打开定义处 |
| Ctrl + . | 快速修复部分可以修复的语法错误 |
| Shift + F12 | 显示所有引用 |
| F2 | 重命名符号 |
| Ctrl + Shift + . / , | 替换下个值 |
| Ctrl + K Ctrl + X | 移除空白字符 |
| Ctrl + K M | 更改页面文档格式 |
编辑器管理
| 快捷键 | 作用 |
|---|---|
| Ctrl + F4, Ctrl + W | 关闭编辑器 |
| Ctrl + k F | 关闭当前打开的文件夹 |
| Ctrl + \ | 切割编辑窗口 |
| Ctrl + 1/2/3 | 切换焦点在不同的切割窗口 |
| Ctrl + K Ctrl ←/→ | 切换焦点在不同的切割窗口 |
| Ctrl + Shift + PgUp/PgDown | 切换标签页的位置 |
| Ctrl + K ←/→ | 切割窗口位置调换 |
文件管理
| 快捷键 | 作用 |
|---|---|
| Ctrl + N | 新建文件 |
| Ctrl + O | 打开文件 |
| Ctrl + S | 保存文件 |
| Ctrl + Shift + S | 另存为 |
| Ctrl + K S | 保存所有当前已经打开的文件 |
| Ctrl + F4 | 关闭当前编辑窗口 |
| Ctrl + K Ctrl + W | 关闭所有编辑窗口 |
| Ctrl + Shift + T | 撤销最近关闭的一个文件编辑窗口 |
| Ctrl + K Enter | 保持开启 |
| Ctrl + Shift + Tab | 调出最近打开的文件列表,重复按会切换 |
| Ctrl + Tab | 与上面一致,顺序不一致 |
| Ctrl + K P | 复制当前打开文件的存放路径 |
| Ctrl + K R | 打开当前编辑文件存放位置【文件管理器】 |
| Ctrl + K O | 在新的编辑器中打开当前编辑的文件 |
显示
| 快捷键 | 作用 |
|---|---|
| F11 | 切换全屏模式 |
| Shift + Alt + 1 | 切换编辑布局【目前无效】 |
| Ctrl + =/- | 放大 / 缩小 |
| Ctrl + B | 侧边栏显示隐藏 |
| Ctrl + Shift + E | 资源视图和编辑视图的焦点切换 |
| Ctrl + Shift + F | 打开全局搜索 |
| Ctrl + Shift + G | 打开Git可视管理 |
| Ctrl + Shift + D | 打开DeBug面板 |
| Ctrl + Shift + X | 打开插件市场面板 |
| Ctrl + Shift + H | 在当前文件替换查询替换 |
| Ctrl + Shift + J | 开启详细查询 |
| Ctrl + Shift + U | 打开输出窗口 |
| Ctrl + Shift + V | 预览Markdown文件 |
| Ctrl + K V | 在边栏打开Markdown预览 |
| Ctrl + K Z | Zen模式 |
调试
| 快捷键 | 作用 |
|---|---|
| F9 | 添加/解除断点 |
| F5 | 启动调试 / 继续 |
| F11 / Shift + F11 | 单步进入 / 单步跳出 |
| F10 | 单步跳过 |
| Ctrl + K Ctrl + I | 显示悬浮 |
集成终端
| 快捷键 | 作用 |
|---|---|
| Ctrl + ` | 打开集成终端 |
| Ctrl + Shift + ` | 创建一个新的终端 |
| Ctrl + C | 复制所选 |
| Ctrl + V | 复制到当前激活的终端 |
| Shift + PgUp / PgDown | 页面上下翻屏 |
| Ctrl + Home / End | 滚动到页面头部或尾部 |
五、goModules介绍
1. 介绍
Go modules是官方提供的go包管理工具,用于解决go包管理和依赖问题;从1.11开始引入,到现在1.14已经比较完善, 1.16已经全面推荐使用,并且默认为开启;Go Modules类似于JS的NPM,Java的maven和gradle。
- GO111MODULE=off: 不使用 modules 功能。
- GO111MODULE=on: 使用 modules 功能,不会去 GOPATH 下面查找依赖包。
- GO111MODULE=auto: Golang 自己检测是不是使用 modules 功能。
- 计划在 Go 1.17 中放弃对
GOPATH的支持,忽略GO111MODULE设置,需要关注默认下载目录如何设置,此特性静观1.17版本发布;
2. 关于go.mod
go.mod是Go项目的依赖描述文件:
module hello
go 1.14
require github.com/gogf/gf v1.15.3
-
module是配置项目名称
-
go配置的是使用的golang版本
-
require配置引用第三方依赖包路径和版本,latest表示最新版本;
配置完编译成功后,生成go.sum依赖分析结果,里面会有当前所有的依赖详细信息;
3. go modules指令
1.go get
go get -u (没有参数)下载、更新当前包下 直接和间接的依赖的最新版本,并不会更新整个项目。
go get -u ./... 下载、更新当前项目根目录下直接或间接的依赖的最新版本,但是会排除测试包的依赖;例如将v1.2.1更新为v2.0.1
go get -u=patch ./... 下载、更新当前项目根目录下直接或间接的依赖的大版本的最新小版本,例如,将v1.2.1更新为v1.2.5
go get -u -t ./... 和 go get -u ./... 相似,但是会更新测试包的依赖
go get -d 只执行下载动作,而不执行安装动作;不再支持go get -m ,使用go get -d替代。
2.go list
go list -m all 列出当前项目build时需要使用直接或间接依赖的版本。
go list -u -m all 不仅会列出当前使用模块的版本,还会列出当前使用模块的最新小版本和最新版本。
3.go build ./… 构建当前项目
4.go test ./… 执行当前项目下的测试
5.go mod
go mod tidy 删除不必要的依赖,添加OS, architecture, and build tags组合所需要的依赖。
go mod vendor 可选步骤,用于建立vendor文件夹,用于vendor机制的包管理
go mod init 将go项目初始化成module-mode,使用go modules进行依赖管理。
go mod verify 校验go.sum记录的依赖信息是否正确
4. go modules需要注意的地方
- 在项目根目录下生成
go.mod - 项目中的包引用使用
import "[module名称]/[包所在文件在项目中的相对路径]"
Goland配置
首先我们需要开启go modules功能,然后配置代理;不配置代理会访问国外地址,会很慢;建议使用以下三个地址:
https://goproxy.iohttps://goproxy.cnhttps://mirrors.aliyun.com/goproxy/
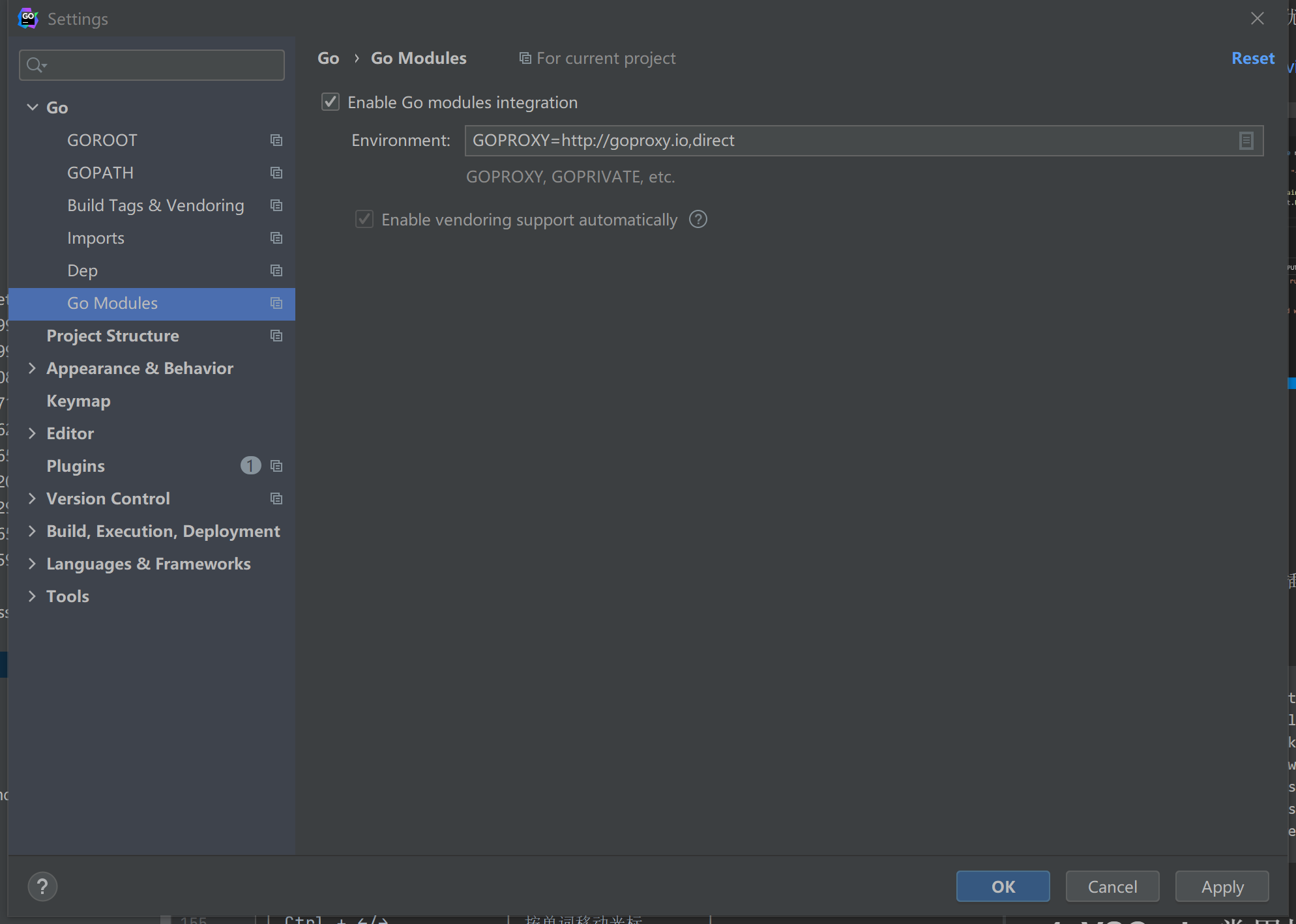
设置 Go Modules 的 Environment 时,是添加KV形式,我们把 GOPROXY=https://goproxy.io,direct 填上去,然后点击 Apply 。
项目结构:
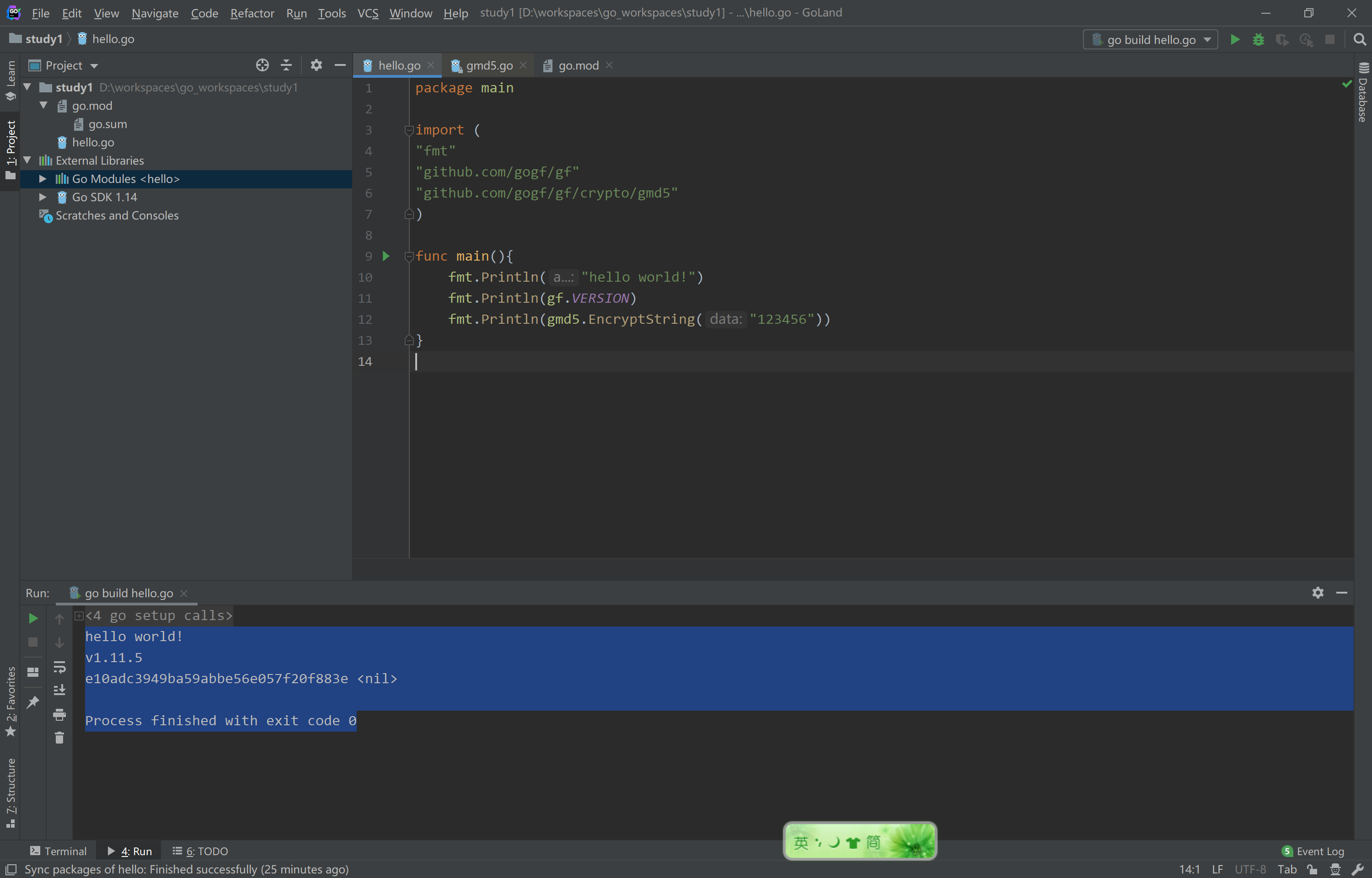
使用上节课我们的hello world程序,创建go.mod,内容如下
module hello
go 1.14
require (
github.com/gogf/gf v1.15.3
)
代码内容如下:
hello.go
package main
import (
"fmt"
"github.com/gogf/gf"
"github.com/gogf/gf/crypto/gmd5"
)
func main(){
fmt.Println("hello world!")
fmt.Println(gf.VERSION)
fmt.Println(gmd5.EncryptString("123456"))
}
第一次我们需要下载依赖包,可以选择go.mod文件右键选择Go Mod Tidy
或者点击没下载的包,alt+enter键,选择Sync packages of hello
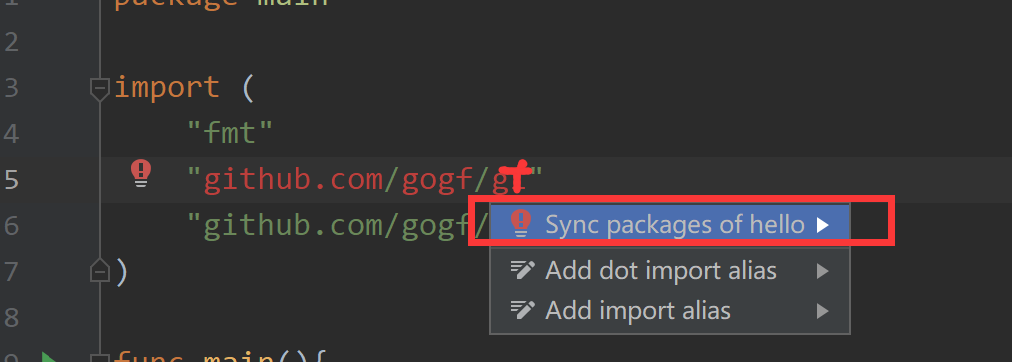
然后运行程序看到运行结果
hello world!
v1.15.3
e10adc3949ba59abbe56e057f20f883e <nil>
Process finished with exit code 0
六、基础语法
Go 程序可以由多个标记组成,可以是关键字,标识符,常量,字符串,符号。
Go 语言的基础组成有以下几个部分:
- 包声明
- 引入包
- 函数
- 变量
- 语句 & 表达式
- 注释
1、基本语法介绍
行分隔符
在 Go 程序中,一行代表一个语句结束。不像其它语言一样以分号 ; 结尾,因为这些工作都将由 Go 编译器自动完成。
注释
单行注释是最常见的注释形式,你可以在任何地方使用以 // 开头的单行注释。多行注释也叫块注释,均已以 /* 开头,并以 */ 结尾。
字符串连接
Go 语言的字符串可以通过 + 实现:
关键字
下面列举了 Go 代码中会使用到的 25 个关键字或保留字:
| break | default | func | interface | select |
|---|---|---|---|---|
| case | defer | go | map | struct |
| chan | else | goto | package | switch |
| const | fallthrough | if | range | type |
| continue | for | import | return | var |
程序一般由关键字、常量、变量、运算符、类型和函数组成。
程序中可能会使用到这些分隔符:括号 (),中括号 [] 和大括号 {}。
程序中可能会使用到这些标点符号: . , ; : 和 … 。
2、示例代码
package main
import (
"fmt"
"math"
"time"
)
func main() {
// hello world
/**
hello world
*/
fmt.Println("hello world")
fmt.Println("##################### values")
values()
fmt.Println("##################### variables")
variables()
fmt.Println("##################### constants")
constants()
fmt.Println("##################### forFunc")
forFunc()
fmt.Println("##################### ifElse")
ifElse()
fmt.Println("##################### switchFunc")
switchFunc()
}
// 值
func values() {
// 字符串拼接用 +
fmt.Println("hello " + "world " + "!")
// 整数和浮点数
fmt.Println("1+2 =", 1+2)
fmt.Println("11-1 =", 11-1)
fmt.Println("99*99 =", 99*99)
fmt.Println("8.0/3.0 =", 8.0/3.0)
// 布尔型
fmt.Println(true && false)
fmt.Println(true || false)
fmt.Println(!true)
}
// 变量
func variables() {
// var 声明 1 个或者多个变量。
var a string = "hello"
fmt.Println(a)
var b, c int = 3, 5
fmt.Println(b, c)
// 会自动推断已经初始化的变量类型。
var d = true
fmt.Println(d)
// 声明变量且 初始化为0
var e int
fmt.Println(e)
// := 简写会自动推断类型,只能用在初始化
f := "short"
fmt.Println(f)
}
// 常量
// 全局常量
const con = "const"
func constants() {
fmt.Println(con)
// const 语句可以出现在任何 var 语句可以出现的地方
const num = 500 * 500 * 500
// 常数表达式可以执行任意精度的运算
const num2 = 4e21 / num
fmt.Println(num2)
// 数值型常量是没有确定的类型的,直到它们被给定了一个类型,比如说一次显示的类型转化。
fmt.Println(int64(num2))
// 当上下文需要时,一个数可以被给定一个类型,比如变量赋值或者函数调用。
// 举个例子,这里的 math.Sin函数需要一个 float64 的参数。
fmt.Println(math.Sin(num))
}
// For循环
func forFunc() {
// 最常用的方式,带单个循环条件。
i := 1
for i <= 4 {
fmt.Println(i)
i = i + 1
}
// 经典的初始化/条件/后续形式 for 循环。
for j := 6; j <= 8; j++ {
fmt.Println(j)
}
// 不带条件的 for 循环将一直执行,直到在循环体内使用了 break 或者 return 来跳出循环。
for {
fmt.Println("for...")
break
}
for n := 0; n <= 7; n++ {
if n%2 == 0 {
continue
}
fmt.Println(n)
}
}
// if/else
func ifElse() {
if 9%2 == 0 {
fmt.Println("9 is even")
} else {
fmt.Println("9 is odd")
}
// 你可以不要 else 只用 if 语句。
if 12%4 == 0 {
fmt.Println("12 is divisible by 4")
}
// 在条件语句之前可以有一个语句;
// 任何在这里声明的变量都可以在所有的条件分支中使用。
if num := 7; num < 0 {
fmt.Println(num, "正数")
} else if num < 10 {
fmt.Println(num, "小于10")
} else {
fmt.Println(num, "其他")
}
// 注意,在 Go 中,你可以不适用圆括号,但是花括号是需要的。
// Go 里没有三目运算符,
// 所以即使你只需要基本的条件判断,你仍需要使用完整的 if 语句。
}
// 分支结构
func switchFunc() {
i := 2
switch i {
case 1:
fmt.Println("1")
case 2:
fmt.Println("2")
case 3:
fmt.Println("3")
}
// 在一个 case 语句中,你可以使用逗号来分隔多个表达式。
// 在这个例子中,我们很好的使用了可选的default 分支。
switch time.Now().Weekday() {
case time.Saturday, time.Sunday:
fmt.Println("星期天")
default:
fmt.Println("工作日")
}
// 不带表达式的 switch 是实现 if/else 逻辑的另一种方式。
// 这里展示了 case 表达式是如何使用非常量的。
t := time.Now()
switch {
case t.Hour() < 12:
fmt.Println("12点前")
default:
fmt.Println("12点后,包含12点")
}
// 这里是一个函数变量
whatAmI := func(i interface{}) {
switch t := i.(type) {
case bool:
fmt.Println("bool")
case int:
fmt.Println("int")
default:
fmt.Printf("什么类型 %T\n", t)
}
}
whatAmI(true)
whatAmI(1)
whatAmI("嘿")
}
运行输出:
hello world
##################### values
hello world !
1+2 = 3
11-1 = 10
99*99 = 9801
8.0/3.0 = 2.6666666666666665
false
true
false
##################### variables
hello
3 5
true
0
short
##################### constants
const
3.2e+13
32000000000000
-0.6542751377793741
##################### forFunc
1
2
3
4
6
7
8
for...
1
3
5
7
##################### ifElse
9 is odd
12 is divisible by 4
7 小于10
##################### switchFunc
工作日
12点前
bool
int
什么类型 string
Process finished with exit code 0
七、常用数据结构
1、常用数据类型介绍
Go 语言提供了数组,切片Slice,集合Map以及循环遍历Range;
数组
数组是具有相同唯一类型的一组已编号且长度固定的数据项序列,这种类型可以是任意的原始类型例如整型、字符串或者自定义类型。
切片(Slice)
Go 数组的长度不可改变,在特定场景中这样的集合就不太适用,Go 中提供了一种灵活,功能强悍的内置类型切片(“动态数组”), 与数组相比切片的长度是不固定的,可以追加元素,在追加时可能使切片的容量增大。
集合(Map)
Map 是一种集合,所以我们可以像迭代数组和切片那样迭代它。不过,Map 是无序的,我们无法决定它的返回顺序, 这是因为 Map 是使用 hash 表来实现的。
循环遍历(Range)
Go 语言中 range 关键字用于 for 循环中迭代数组(array)、切片(slice)、通道(channel)或集合(map)的元素。 在数组和切片中它返回元素的索引和索引对应的值,在集合中返回 key-value 对。
2、示例
package main
import "fmt"
func main() {
// hello world
fmt.Println("hello world")
fmt.Println("##################### arrays")
arrays()
fmt.Println("##################### slice")
slice()
fmt.Println("##################### mapFunc")
mapFunc()
fmt.Println("##################### rangeFunc")
rangeFunc()
}
// 数组
func arrays() {
// 这里我们创建了一个数组 test1 来存放刚好 6 个 int。
// 元素的类型和长度都是数组类型的一部分。
// 数组默认是零值的,对于 int 数组来说也就是 0。
var test1 [6]int
fmt.Println("内容:", test1)
// 我们可以使用 array[index] = value 语法来设置数组指定位置的值,或者用 array[index] 得到值。
test1[4] = 100
fmt.Println("设置:", test1)
fmt.Println("获取:", test1[4])
// 使用内置函数 len 返回数组的长度
fmt.Println("长度:", len(test1))
// 使用这个语法在一行内初始化一个数组
test2 := [6]int{1, 2, 3, 4, 5, 6}
fmt.Println("数据:", test2)
// 数组的存储类型是单一的,但是你可以组合这些数据来构造多维的数据结构。
var twoTest [3][4]int
for i := 0; i < 3; i++ {
for j := 0; j < 4; j++ {
twoTest[i][j] = i + j
}
}
// 注意,在使用 fmt.Println 来打印数组的时候,会使用[v1 v2 v3 ...] 的格式显示
fmt.Println("二维: ", twoTest)
}
// 切片
func slice() {
// Slice 是 Go 中一个关键的数据类型,是一个比数组更加强大的序列接口
// 不像数组,slice 的类型仅由它所包含的元素决定(不像数组中还需要元素的个数)。
// 要创建一个长度非零的空slice,需要使用内建的方法 make。
// 这里我们创建了一个长度为3的 string 类型 slice(初始化为零值)。
test1 := make([]string, 3)
fmt.Println("数据:", test1)
// 我们可以和数组一样设置和得到值
test1[0] = "A"
test1[1] = "C"
test1[2] = "B"
fmt.Println("数据:", test1)
fmt.Println("获取:", test1[2])
// 如你所料,len 返回 slice 的长度
fmt.Println("长度:", len(test1))
// 作为基本操作的补充,slice 支持比数组更多的操作。
// 其中一个是内建的 append,它返回一个包含了一个或者多个新值的 slice。
// 注意我们接受返回由 append返回的新的 slice 值。
test1 = append(test1, "D")
test1 = append(test1, "E", "F")
fmt.Println("追加:", test1)
// Slice 也可以被 copy。这里我们创建一个空的和 test1 有相同长度的 slice test2,并且将 test1 复制给 test2。
test2 := make([]string, len(test1))
copy(test2, test1)
fmt.Println("拷贝:", test2)
// Slice 支持通过 slice[low:high] 语法进行“切片”操作。例如,这里得到一个包含元素 test1[2], test1[3],test1[4] 的 slice。
l := test1[2:5]
fmt.Println("切片1:", l)
// 这个 slice 从 test1[0] 到(但是不包含)test1[5]。
l = test1[:5]
fmt.Println("切片2:", l)
// 这个 slice 从(包含)test1[2] 到 slice 的后一个值。
l = test1[2:]
fmt.Println("切片3:", l)
// 我们可以在一行代码中声明并初始化一个 slice 变量。指定长度就是数组,没指定长度就是切片。
t := []string{"g", "h", "i"}
fmt.Println("数据:", t)
// Slice 可以组成多维数据结构。内部的 slice 长度可以不同,这和多位数组不同。
twoTest := make([][]int, 3)
for i := 0; i < 3; i++ {
innerLen := i + 1
twoTest[i] = make([]int, innerLen)
for j := 0; j < innerLen; j++ {
twoTest[i][j] = i + j
}
}
// 注意,slice 和数组不同,虽然它们通过 fmt.Println 输出差不多。
fmt.Println("二维: ", twoTest)
}
// 键值对 key/value
func mapFunc() {
// 要创建一个空 map,需要使用内建的 make: make(map[key-type]val-type).
map1 := make(map[string]int)
// 使用典型的 make[key] = val 语法来设置键值对。
map1["k1"] = 7
map1["k2"] = 13
// 使用例如 Println 来打印一个 map 将会输出所有的键值对。
fmt.Println("数据:", map1)
// 使用 name[key] 来获取一个键的值
v1 := map1["k1"]
fmt.Println("值: ", v1)
// 当对一个 map 调用内建的 len 时,返回的是键值对数目
fmt.Println("长度:", len(map1))
// 内建的 delete 可以从一个 map 中移除键值对
delete(map1, "k2")
fmt.Println("数据:", map1)
// 当从一个 map 中取值时,可选的第二返回值指示这个键是在这个 map 中。
// 这可以用来消除键不存在和键有零值,像 0 或者 "" 而产生的歧义。
_, prs := map1["k2"]
fmt.Println("是否存在:", prs)
// 你也可以通过这个语法在同一行申明和初始化一个新的map。
map2 := map[string]int{"F": 1, "B": 2}
// 注意一个 map 在使用 fmt.Println 打印的时候,是以 map[k:v k:v]的格式输出的。
fmt.Println("数据:", map2)
}
// Range 遍历
func rangeFunc() {
// 这里我们使用 range 来统计一个 slice 的元素个数。数组也可以采用这种方法。
array1 := []int{2, 3, 4}
sum := 0
for _, num := range array1 {
sum += num
}
fmt.Println("求和:", sum)
// range 在数组和 slice 中都同样提供每个项的索引和值。
// 上面我们不需要索引,所以我们使用 空值定义符_ 来忽略它。
// 有时候我们实际上是需要这个索引的。
for i, num := range array1 {
if num == 3 {
fmt.Println("索引:", i)
}
}
// range 在 map 中迭代键值对。
map1 := map[string]string{"A": "苹果", "B": "香蕉"}
for k, v := range map1 {
fmt.Printf("%s -> %s\n", k, v)
}
for k := range map1 {
fmt.Println("键:", k)
}
// range 在字符串中迭代 unicode 编码。
// 第一个返回值是rune 的起始字节位置,然后第二个是 rune 自己。
for i, c := range "abA" {
fmt.Println(i, c)
}
}
运行输出:
hello world
##################### arrays
内容: [0 0 0 0 0 0]
设置: [0 0 0 0 100 0]
获取: 100
长度: 6
数据: [1 2 3 4 5 6]
二维: [[0 1 2 3] [1 2 3 4] [2 3 4 5]]
##################### slice
数据: [ ]
数据: [A C B]
获取: B
长度: 3
追加: [A C B D E F]
拷贝: [A C B D E F]
切片1: [B D E]
切片2: [A C B D E]
切片3: [B D E F]
数据: [g h i]
二维: [[0] [1 2] [2 3 4]]
##################### mapFunc
数据: map[k1:7 k2:13]
值: 7
长度: 2
数据: map[k1:7]
是否存在: false
数据: map[B:2 F:1]
##################### rangeFunc
求和: 9
索引: 1
B -> 香蕉
A -> 苹果
键: A
键: B
0 97
1 98
2 65
Process finished with exit code 0
八、函数介绍
函数是基本的代码块,用于执行一个任务。
Go 语言最少有个 main() 函数。
你可以通过函数来划分不同功能,逻辑上每个函数执行的是指定的任务。
函数声明告诉了编译器函数的名称,返回类型,和参数。
Go 语言标准库提供了多种可用的内置的函数。例如,len() 函数可以接受不同类型参数并返回该类型的长度。 如果我们传入的是字符串则返回字符串的长度,如果传入的是数组,则返回数组中包含的元素个数。
函数定义
Go 语言函数定义格式如下:
func function_name( [parameter list] ) [return_types] {
函数体
}
函数定义解析:
- func:函数由 func 开始声明
- function_name:函数名称,函数名和参数列表一起构成了函数签名。
- parameter list:参数列表,参数就像一个占位符,当函数被调用时,你可以将值传递给参数,这个值被称为实际参数。 参数列表指定的是参数类型、顺序、及参数个数。参数是可选的,也就是说函数也可以不包含参数。
- return_types:返回类型,函数返回一列值。return_types 是该列值的数据类型。有些功能不需要返回值, 这种情况下 return_types 不是必须的。
- 函数体:函数定义的代码集合。
函数的作用域
作用域:变量可以使用的范围
局部变量:函数内部(if、for语句中)定义的变量,叫做局部变量
全部变量:函数外部定义的变量,叫做全局变量
defer
defer函数或者方法:一个函数或方法的执行被延迟了
- 你可以在函数中添加多个defer语句,当函数执行到最后时,这些defer语句会按照逆序执行(栈:后进先出),最后该函数返回, 特别是当你在进行一些打开资源的操作时,遇到错误需要提前返回,在返回前你需要关闭相应的资源,不然很容易造成资源泄露等问题
- 如果有很多调用defer,那么defer是采用后进先出(栈)模式。
- defer定义时,内存信息已写入
defer函数传递参数的时候:
package main
import "fmt"
func main() {
a := 10
fmt.Println("main a:", a)
defer f(a) //先调用,后执行
a++
fmt.Println("main end a:", a)
}
func f(a int) {
fmt.Println("函数中a:", a)
}
输出:
main a: 10
main end a: 11
函数中a: 10
defer的用法:
1、对象.close()临时文件的删除
文件.open()
defer 文件.close()
读或写操作
2、go语言中关于异常的处理,使用panic()和recover()
- panic函数用于引发恐慌,导致程序中断执行
- recover函数用于恢复程序的执行,recover()语法上要求必须在defer中执行。
示例
package main
import "fmt"
func main() {
// hello world
fmt.Println("hello world")
// 1. 加法
res := plus(1, 2)
fmt.Println("1+2 =", res)
res = plusPlus(1, 2, 3)
fmt.Println("1+2+3 =", res)
// 2. 多值返回
// 这里我们通过多赋值 操作来使用这两个不同的返回值。
a, b := vals()
fmt.Println(a)
fmt.Println(b)
// 如果你仅仅想返回值的一部分的话,你可以使用空白定义符 _。
_, c := vals()
fmt.Println(c)
// 3. 可变参数
// 变参函数使用常规的调用方式,除了参数比较特殊,变参函数的参数本质上是一个切片,所以可以直接传切片。
sum(1, 2)
sum(1, 2, 3)
// 如果你的 slice 已经有了多个值,想把它们作为变参使用,你要这样调用 func(slice...)。
nums := []int{1, 2, 3, 4}
sum(nums...)
// 4. 闭包
// 我们调用 intSeq 函数,将返回值(也是一个函数)赋给nextInt。
// 这个函数的值包含了自己的值 i,这样在每次调用 nextInt 时都会更新 i 的值。
nextInt := intSeq()
// 通过多次调用 nextInt 来看看闭包的效果。
fmt.Println(nextInt())
fmt.Println(nextInt())
fmt.Println(nextInt())
// 为了确认这个状态对于这个特定的函数是唯一的,我们重新创建并测试一下。
newInts := intSeq()
fmt.Println(newInts())
// 5. 递归
fmt.Println(fact(7))
}
// 函数
// 这里是一个函数,接受两个 int 并且以 int 返回它们的和
func plus(a int, b int) int {
// Go 需要明确的返回值,例如,它不会自动返回最后一个表达式的值
return a + b
}
func plusPlus(a, b, c int) int {
return a + b + c
}
// 多返回值函数
// (int, int) 在这个函数中标志着这个函数返回 2 个 int。
func vals() (int, int) {
return 3, 7
}
// 变参函数,nums本质上是一个切片
func sum(nums ...int) {
fmt.Print(nums, " ")
total := 0
for _, num := range nums {
total += num
}
fmt.Println(total)
}
// 闭包
// 这个 intSeq 函数返回另一个在 intSeq 函数体内定义的匿名函数。
// 这个返回的函数使用闭包的方式 隐藏 变量 i。
func intSeq() func() int {
i := 0
return func() int {
i += 1
return i
}
}
// 递归
// face 函数在到达 face(0) 前一直调用自身。
func fact(n int) int {
if n == 0 {
return 1
}
return n * fact(n-1)
}
运行输出:
hello world
1+2 = 3
1+2+3 = 6
3
7
7
[1 2] 3
[1 2 3] 6
[1 2 3 4] 10
1
2
3
1
5040
Process finished with exit code 0
九、指针结构体接口
1、什么是指针
C语言里,变量存放在内存中,而内存其实就是一组有序字节组成的数组,每个字节有唯一的内存地址。 CPU 通过内存寻址对存储在内存中的某个指定数据对象的地址进行定位。这里,数据对象是指存储在内存中的一个指定数据类型的数值或字符串, 它们都有一个自己的地址,而指针便是保存这个地址的变量。也就是说:指针是一种保存变量地址的变量。
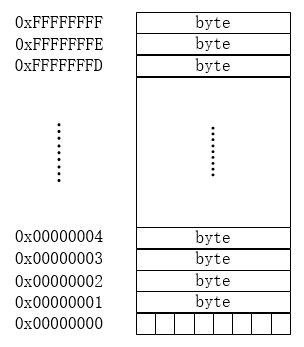
2、Go 指针
指针如何定义:
var ip *int /* 指向整型*/
var fp *float32 /* 指向浮点型 */
指针使用流程:
- 定义指针变量。
- 为指针变量赋值。
- 访问指针变量中指向地址的值。
示例:
package main
import "fmt"
// 我们将通过两个函数:val 和 ptr 来比较指针和值类型的不同。
// val 有一个 int 型参数,所以使用值传递。
// val 将从调用它的那个函数中得到一个 val1 形参的拷贝。
func val(val1 int) {
val1 = 0
}
// ptr 有一和上面不同的 *int 参数,意味着它用了一个 int指针。
// 函数体内的 *iptr 接着解引用 这个指针,从它内存地址得到这个地址对应的当前值。
// 对一个解引用的指针赋值将会改变这个指针引用的真实地址的值。
func ptr(iptr *int) {
*iptr = 0
}
func main() {
test := 1
fmt.Println("initial:", test)
val(test)
fmt.Println("val:", test)
// 通过 &test 语法来取得 test 的内存地址,例如一个变量i 的指针。
ptr(&test)
fmt.Println("ptr:", test)
// 指针也是可以被打印的。
fmt.Println("pointer:", &test)
// val 在 main 函数中不能改变 test 的值,但是ptr 可以,因为它有一个这个变量的内存地址的引用。
fmt.Println("pointer:", *&test)
}
运行输出:
initial: 1
val: 1
ptr: 0
pointer: 0xc0000180a0
pointer: 0
Process finished with exit code 0
3、Go 空指针
当一个指针被定义后没有分配到任何变量时,它的值为 nil。
nil 指针也称为空指针。
nil在概念上和其它语言的null、None、nil、NULL一样,都指代零值或空值。
4、什么结构体
Go 语言中数组可以存储同一类型的数据,但在结构体中我们可以为不同项定义不同的数据类型。
结构体是由一系列具有相同类型或不同类型的数据构成的数据集合。
结构体表示一项记录,比如保存图书馆的书籍记录,每本书有以下属性:
- Title :标题
- Author : 作者
- Subject:学科
- ID:书籍ID
5、定义结构体
结构体定义需要使用 type 和 struct 语句。struct 语句定义一个新的数据类型,结构体中有一个或多个成员。 type 语句设定了结构体的名称。结构体的格式如下:
type struct_variable_type struct {
member definition
member definition
...
member definition
}
下面我们看下示例:
package main
import "fmt"
// 这里的 person 结构体包含了 name 和 age 两个字段。
type person struct {
name string
age int
}
func main() {
// 使用这个语法创建了一个新的结构体元素。
fmt.Println(person{"Bob", 20})
// 你可以在初始化一个结构体元素时指定字段名字。
fmt.Println(person{name: "Alice", age: 30})
// 省略的字段将被初始化为零值。
fmt.Println(person{name: "Fred"})
// & 前缀生成一个结构体指针。
fmt.Println(&person{name: "Ann", age: 40})
// 使用点来访问结构体字段。
s := person{name: "Sean", age: 50}
fmt.Println(s.name)
// 也可以对结构体指针使用. - 指针会被自动解引用。
sp := &s
fmt.Println(sp.age)
// 结构体是可变的。
sp.age = 51
fmt.Println(sp.age)
}
运行输出:
{Bob 20}
{Alice 30}
{Fred 0}
&{Ann 40}
Sean
50
51
6、结构体方法
结构体即为对象,对象的行为可以称之为方法;比如人可以走,手、脚为人的属性,走为人的方法;我们看下面关于形状的例子:
package main
import "fmt"
type rectangle struct {
width, height int
}
// 这里的 area 方法有一个接收器类型 rect
// 方法是建立在结构体指针上的,说明函数内可以改变结构体中的变量值,关于这一点,这里可以反复对比琢磨下
func (r *rectangle) area() int {
r.width = 1
return r.width * r.height
}
// 可以为值类型或者指针类型的接收器定义方法。这里是一个值类型接收器的例子。
func (r rectangle) perim() int {
return 2*r.width + 2*r.height
}
func main() {
r := rectangle{width: 10, height: 5}
// 这里我们调用上面为结构体定义的两个方法。
fmt.Println("area: ", r.area())
fmt.Println("perim:", r.perim())
// Go 自动处理方法调用时的值和指针之间的转化。
// 你可以使用指针来调用方法来避免在方法调用时产生一个拷贝,或者让方法能够改变接受的数据。
rp := &r
fmt.Println("area: ", rp.area())
fmt.Println("perim:", rp.perim())
}
运行输出:
area: 5
perim: 12
area: 5
perim: 12
7、接口定义
Go 语言提供了另外一种数据类型即接口,它把所有的具有共性的方法定义在一起,任何其他类型只要实现了这些方法就是实现了这个接口。
接口其实就是物体抽象的定义,实际用才会有体会,示例
package main
import "fmt"
import "math"
// 这里是一个几何体的基本接口。
type geometry interface {
area() float64
perim() float64
}
// 在我们的例子中,我们将让 rect 和 circle 实现这个接口
type rect struct {
width, height float64
}
type circle struct {
radius float64
}
// 要在 Go 中实现一个接口,我们只需要实现接口中的所有方法。
// 这里我们让 rect 实现了 geometry 接口。
func (r rect) area() float64 {
return r.width * r.height
}
func (r rect) perim() float64 {
return 2*r.width + 2*r.height
}
// circle 的实现。
func (c circle) area() float64 {
return math.Pi * c.radius * c.radius
}
func (c circle) perim() float64 {
return 2 * math.Pi * c.radius
}
// 如果一个变量的是接口类型,那么我们可以调用这个被命名的接口中的方法。
// 这里有一个一通用的 measure 函数,利用这个特性,它可以用在任何 geometry 上。
func measure(g geometry) {
fmt.Println(g)
fmt.Println(g.area())
fmt.Println(g.perim())
}
func main() {
r := rect{width: 3, height: 4}
c := circle{radius: 5}
// 结构体类型 circle 和 rect 都实现了 geometry接口,
// 所以我们可以使用它们的实例作为 measure 的参数。
measure(r)
measure(c)
}
运行输出:
{3 4}
12
14
{5}
78.53981633974483
31.41592653589793
十、错误处理
1、错误
在Go中有一部分函数总是能成功的运行。比如strings.Contains和strconv.FormatBool函数;对于大部分函数而言,永远无法确保能否成功运行。
Go 语言通过内置的错误接口提供了非常简单的错误处理机制。
说明1
fmt.Errorf是Go标准库中的函数,可以创建一个新的错误。这个函数接受一个格式化字符串和一些参数,返回一个新的错误:
err := fmt.Errorf("an error occurred: %s", err)
fmt.Errorf的优点在于其支持格式化字符串,这使得我们可以方便地在错误信息中包含一些动态的数据。
Go 1.13中引入的新特性使fmt.Errorf通过%w谓词包装错误,这样就可以保留原始错误的信息。例如:
originalErr := errors.New("original error")
newErr := fmt.Errorf("an error occurred: %w", originalErr)
然而,尽管fmt.Errorf可以保留原始错误的信息,但它并不会保留原始错误的堆栈跟踪信息。
errors.Wrap和errors.Wrapf是github.com/pkg/errors库中的函数,用于创建新的错误。
它们接受一个原始错误和一个描述信息,返回一个新的错误:
err := errors.Wrap(err, "an error occurred")
err = errors.Wrapf(err, "an error occurred: %s", "additional context")
errors.Wrap和errors.Wrapf的优点在于它们会保留原始错误的堆栈跟踪信息。你可以使用errors.Cause函数获取到原始错误,
使用fmt.Printf("%+v", err)打印完整的错误信息和堆栈跟踪。
此外,errors.Wrapf还支持格式化字符串,这意味着我们可以在错误信息中直接包含动态的数据。
总结
- 使用
fmt.Errorf,如果我们需要在错误信息中包含动态的数据,并且不需要原始错误的堆栈跟踪信息。 不过,我仍可以使用%w谓词来包装原始错误的信息。 - 使用
errors.Wrap,如果我们需要保留原始错误的堆栈跟踪信息,并且不需要在错误信息中包含动态的数据。 - 使用
errors.Wrapf,如果我们既需要保留原始错误的堆栈跟踪信息,又需要在错误信息中包含动态的数据。
选择哪种方法取决于我们的具体需求。理解这些方法的特性和区别可以帮助你更有效地处理错误,并使我们的代码更容易理解和维护。
说明2
error类型是一个接口类型,这是它的定义:
type error interface {
Error() string
}
我们可以在编码中通过实现 error 接口类型来生成错误信息。
函数通常在最后的返回值中返回错误信息。使用errors.New 可返回一个错误信息:
func Sqrt(f float64) (float64, error) {
if f < 0 {
return 0, errors.New("math: square root of negative number")
}
// 实现
}
errors.New() 返回一个 errors对象,字符串化该对象时,调用这个对象的 Error() 方法。
这里有一个错误处理的例子:
package main
import "errors"
import "fmt"
// 按照惯例,错误通常是最后一个返回值并且是 error 类型,一个内建的接口。
func f1(arg int) (int, error) {
// errors.New 构造一个使用给定的错误信息的基本error 值。
if arg == 42 {
return -1, errors.New("can't work with 42")
}
// 返回错误值为 nil 代表没有错误。
return arg + 3, nil
}
// 通过实现 Error 方法来自定义 error 类型是可以的。
// 这里使用自定义错误类型来表示上面的参数错误。
type argError struct {
arg int
prob string
}
func (e *argError) Error() string {
return fmt.Sprintf("%d - %s", e.arg, e.prob)
}
// 指明返回 int 和 error 类型
func f2(arg int) (int, error) {
if arg == 42 {
// 在这个例子中,我们使用 &argError 语法来建立一个新的结构体,并提供了 arg 和 prob 这个两个字段的值。
return -1, &argError{arg, "can't work with it"}
}
return arg + 3, nil
}
func main() {
// 下面的两个循环测试了各个返回错误的函数。
// 注意在 if行内的错误检查代码,在 Go 中是一个普遍的用法。
for _, i := range []int{7, 42} {
if r, e := f1(i); e != nil {
fmt.Println("f1 失败:", e)
} else {
fmt.Println("f1 工作:", r)
}
}
for _, i := range []int{7, 42} {
if r, e := f2(i); e != nil {
fmt.Println("f2 失败:", e)
} else {
fmt.Println("f2 工作:", r)
}
}
// 你如果想在程序中使用一个自定义错误类型中的数据,你需要通过类型断言来得到这个错误类型的实例。
_, e := f2(42)
if ae, ok := e.(*argError); ok {
fmt.Println(ae.arg)
fmt.Println(ae.prob)
}
}
运行输出:
f1 工作: 10
f1 失败: can't work with 42
f2 工作: 10
f2 失败: 42 - can't work with it
42
can't work with it
2、Deferred函数
defer语句经常被用于处理成对的操作,如打开、关闭、连接、断开连接、加锁、释放锁。通过defer机制,不论函数逻辑多复杂, 都能保证在任何执行路径下,资源被释放。释放资源的defer应该直接跟在请求资源的语句后。
示例:
package main
import "fmt"
import "os"
func main() {
// 假设我们想要创建一个文件,向它进行写操作,然后在结束时关闭它。
// 这里展示了如何通过 defer 来做到这一切。
f := createFile("D:/defer.txt") // f := createFile("/tmp/defer.txt")
// 在 createFile 后得到一个文件对象,我们使用 defer通过 closeFile 来关闭这个文件。这会在封闭函数(main)结束时执行,就是 writeFile 结束后。
defer closeFile(f)
writeFile(f)
}
func createFile(p string) *os.File {
fmt.Println("creating")
f, err := os.Create(p)
if err != nil {
panic(err)
}
return f
}
func writeFile(f *os.File) {
fmt.Println("writing")
fmt.Fprintln(f, "data")
}
func closeFile(f *os.File) {
fmt.Println("closing")
f.Close()
}
上面这种写法是错误的,closeFile() 并不会执行,因为在 createFile() 后申明。
但把closeFile() 移动到createFile() 前面时,文件句柄并没有创建好,所以 f.Close() 应该要直接写在 os.Create(p) 后面:
package main
import "fmt"
import "os"
func main() {
f := createFile("D:/defer.txt") // f := createFile("/tmp/defer.txt")
writeFile(f)
}
func createFile(p string) *os.File {
fmt.Println("creating")
f, err := os.Create(p)
defer f.Close()
if err != nil {
panic(err)
}
return f
}
func writeFile(f *os.File) {
fmt.Println("writing")
fmt.Fprintln(f, "data")
}
看一下这个示例,理解一下:
package main
import "fmt"
func main() {
createFile("defer.txt")
writeFile()
}
func createFile(p string) string {
fmt.Println("creating")
defer closeFile()
panic("three")
return p
}
func writeFile() {
fmt.Println("writing")
}
func closeFile() {
fmt.Println("closing")
}
输出:
creating
closing
panic: three
goroutine 1 [running]:
main.createFile(0x4c2b84, 0x9, 0x0, 0x0)
/box/main.go:14 +0xd4
main.main()
/box/main.go:6 +0x3a
Exited with error status 2
3、异常
Go的类型系统会在编译时捕获很多错误,但有些错误只能在运行时检查,如数组访问越界、空指针引用等。这些运行时错误会引起painc异常。
示例如下:
package main
import (
"fmt"
"os"
)
func main() {
// 我们将在这个网站中使用 panic 来检查预期外的错误。这个是唯一一个为 panic 准备的例子。
panic("一个异常")
// panic 的一个基本用法就是在一个函数返回了错误值,但是我们并不知道(或者不想)处理时终止运行。
// 这里是一个在创建一个新文件时返回异常错误时的panic 用法。
fmt.Println("继续")
_, err := os.Create("/tmp/file")
if err != nil {
panic(err)
}
// 运行程序将会引起 panic,输出一个错误消息和 Go 运行时栈信息,并且返回一个非零的状态码。
}
运行输出:
panic: 一个异常
goroutine 1 [running]:
main.main()
D:/goweb/func/panic.go:10 +0x40
Process finished with exit code 2
4、捕获异常
通常来说,不应该对panic异常做任何处理,但有时,也许我们可以从异常中恢复,至少我们可以在程序崩溃前,做一些操作。 举个例子,当web服务器遇到不可预料的严重问题时,在崩溃前应该将所有的连接关闭;如果不做任何处理, 会使得客户端一直处于等待状态。如果web服务器还在开发阶段,服务器甚至可以将异常信息反馈到客户端,帮助调试。
如果在deferred函数中调用了内置函数recover,并且定义该defer语句的函数发生了panic异常,recover会使程序从panic中恢复, 并返回panic value。导致panic异常的函数不会继续运行,但能正常返回。在未发生panic时调用recover,recover会返回nil。
示例:
package main
import "fmt"
func main() {
// 这里我们对异常进行了捕获
defer func() {
if p := recover(); p != nil {
err := fmt.Errorf("internal error: %v", p)
if err != nil {
fmt.Println(err)
}
}
}()
// 我们将在这个网站中使用 panic 来检查预期外的错误。这个是唯一一个为 panic 准备的例子。
panic("一个异常")
}
运行输出:
internal error: 一个异常
十一、并发
1、协程(Goroutines)
在Go语言中,每一个并发的执行单元叫作一个goroutine。,我们只需要通过 go 关键字来开启 goroutine 即可。 goroutine 是轻量级线程,goroutine 的调度是由 Golang 运行时进行管理的。
goroutine 语法格式:
go 函数名( 参数列表 )
示例:
package main
import "fmt"
func f(from string) {
for i := 0; i < 3; i++ {
fmt.Println(from, ":", i)
}
}
func main() {
// 假设我们有一个函数叫做 f(s)。
// 我们使用一般的方式调并同时运行。
f("direct")
// 使用 go f(s) 在一个 Go 协程中调用这个函数。
// 这个新的 Go 协程将会并行的执行这个函数调用。
go f("goroutine")
// 你也可以为匿名函数启动一个 Go 协程。
go func(msg string) {
fmt.Println(msg)
}("going")
// 现在这两个 Go 协程在独立的 Go 协程中异步的运行,所以我们需要等它们执行结束。
// 这里的 Scanln 代码需要我们在程序退出前按下任意键结束。提前输入,直接结束,将看不到协程输出的结果。
var input string
fmt.Scanln(&input)
fmt.Println("done")
// 当我们运行这个程序时,将首先看到阻塞式调用的输出,然后是两个 Go 协程的交替输出。
// 这种交替的情况表示 Go 运行时是以异步的方式运行协程的。
}
运行输出:
direct : 0
direct : 1
direct : 2
goroutine : 0
goroutine : 1
goroutine : 2
going
123
done
改成这样,直观感受下:
package main
import "fmt"
import "time"
func f(from string) {
for i := 0; i < 3; i++ {
time.Sleep(time.Second * 5)
fmt.Println(from, ":", i)
}
}
func main() {
// 假设我们有一个函数叫做 f(s)。
// 我们使用一般的方式调并同时运行。
f("direct")
// 使用 go f(s) 在一个 Go 协程中调用这个函数。
// 这个新的 Go 协程将会并行的执行这个函数调用。
go f("goroutine")
// 你也可以为匿名函数启动一个 Go 协程。
go func(msg string) {
time.Sleep(time.Second * 3)
fmt.Println(msg)
}("going")
// 提前输入,直接结束,将看不到协程输出的结果。
var input string
fmt.Scanln(&input)
fmt.Println("done")
}
运行输出:
direct : 0
direct : 1
direct : 2
going
goroutine : 0
goroutine : 1
goroutine : 2
123
done
2、通道(channel)
如果说goroutine是Go语言程序的并发体的话,那么channels则是它们之间的通信机制。通道(channel)是用来传递数据的一个数据结构。
通道可用于两个 goroutine 之间通过传递一个指定类型的值来同步运行和通讯。操作符 <- 用于指定通道的方向,发送或接收。
如果未指定方向,则为双向通道。
ch <- v // 把 v 发送到通道 ch
v := <-ch // 从 ch 接收数据
// 并把值赋给 v
声明一个通道很简单,我们使用chan关键字即可,通道在使用前必须先创建:
ch := make(chan int)
示例:
package main
import (
"fmt"
)
// 通道 是连接多个 Go 协程的管道。
// 你可以从一个 Go 协程将值发送到通道,然后在别的 Go 协程中接收。
func main() {
// 使用 make(chan val-type) 创建一个新的通道。
// 通道类型就是他们需要传递值的类型。
messages := make(chan string)
// 使用 channel <- 语法 发送 一个新的值到通道中。
// 这里我们在一个新的 Go 协程中发送 "ping" 到上面创建的messages 通道中。
go func() {
messages <- "ping"
}()
// 使用 <-channel 语法从通道中 接收 一个值。
// 这里将接收我们在上面发送的 "ping" 消息并打印出来。
msg := <-messages
fmt.Println(msg)
// 我们运行程序时,通过通道,消息 "ping" 成功的从一个 Go 协程传到另一个中。
// 默认发送和接收操作是阻塞的,直到发送方和接收方都准备完毕。
// 这个特性允许我们,不使用任何其它的同步操作,来在程序结尾等待消息 "ping"。
}
3、通道缓冲区
通道可以设置缓冲区,通过 make 的第二个参数指定缓冲区大小:
ch := make(chan int, 100)
带缓冲区的通道允许发送端的数据发送和接收端的数据获取处于异步状态,就是说发送端发送的数据可以放在缓冲区里面, 可以等待接收端去获取数据,而不是立刻需要接收端去获取数据。
不过由于缓冲区的大小是有限的,所以还是必须有接收端来接收数据的,否则缓冲区一满,数据发送端就无法再发送数据了。
注意:如果通道不带缓冲,发送方会阻塞直到接收方从通道中接收了值。 如果通道带缓冲,发送方则会阻塞直到发送的值被拷贝到缓冲区内;如果缓冲区已满,则意味着需要等待直到某个接收方获取到一个值。 接收方在有值可以接收之前会一直阻塞。
示例:
package main
import "fmt"
// 默认通道是 无缓冲 的,这意味着只有在对应的接收(<- chan)通道准备好接收时,才允许进行发送(chan <-)。
// 可缓存通道允许在没有对应接收方的情况下,缓存限定数量的值。
func main() {
// 这里我们 make 了一个通道,最多允许缓存 2 个值。
messages := make(chan string, 2)
// 因为这个通道是有缓冲区的,即使没有一个对应的并发接收方,我们仍然可以发送这些值。
messages <- "buffered"
messages <- "channel"
// 然后我们可以像前面一样接收这两个值。
fmt.Println(<-messages)
fmt.Println(<-messages)
}
4、同步实现
我们可以通过channel实现同步,如下:
package main
import "fmt"
import "time"
// 我们可以使用通道来同步 Go 协程间的执行状态。
// 这里是一个使用阻塞的接受方式来等待一个 Go 协程的运行结束。
func worker(done chan bool) {
// 这是一个我们将要在 Go 协程中运行的函数。
// done 通道将被用于通知其他 Go 协程这个函数已经工作完毕。
fmt.Print("working...")
time.Sleep(time.Second)
fmt.Println("done")
// 发送一个值来通知我们已经完工啦。
done <- true
}
func main() {
// 运行一个 worker Go协程,并给予用于通知的通道。
done := make(chan bool, 1)
go worker(done)
// 程序将在接收到通道中 worker 发出的通知前一直阻塞。
<-done
// 如果你把 <- done 这行代码从程序中移除,程序甚至会在 worker还没开始运行时就结束了。
}
5、通道方向示例
package main
import "fmt"
// 当使用通道作为函数的参数时,你可以指定这个通道是不是只用来发送或者接收值。
// 这个特性提升了程序的类型安全性。
func ping(pings chan <- string, msg string) {
// ping 函数定义了一个只允许发送数据的通道。
// 尝试使用这个通道来接收数据将会得到一个编译时错误。
pings <- msg
}
func pong(pings <-chan string, pongs chan <- string) {
// pong 函数允许通道(pings)来接收数据,另一通道(pongs)来发送数据。
msg := <-pings
pongs <- msg
}
func main() {
pings := make(chan string, 1)
pongs := make(chan string, 1)
ping(pings, "passed message")
pong(pings, pongs)
fmt.Println(<-pongs)
}
6、Go 遍历通道与关闭通道
Go 通过 range 关键字来实现遍历读取到的数据,类似于与数组或切片。格式如下:
v, ok := <-ch
如果通道接收不到数据后 ok 就为 false,这时通道就可以使用 close() 函数来关闭。
7、通道选择器(select)
select {
case <-ch1:
// ...
case x := <-ch2:
// ...use x...
case ch3 <- y:
// ...
default:
// ...
}
select语句的一般形式。和switch语句稍微有点相似,也会有几个case和最后的default选择支。 每一个case代表一个通信操作(在某个channel上进行发送或者接收)并且会包含一些语句组成的一个语句块。 一个接收表达式可能只包含接收表达式自身(译注:不把接收到的值赋值给变量什么的),就像上面的第一个case, 或者包含在一个简短的变量声明中,像第二个case里一样;第二种形式让你能够引用接收到的值。
select会等待case中有能够执行的case时去执行。当条件满足时,select才会去通信并执行case之后的语句; 这时候其它通信是不会执行的。一个没有任何case的select语句写作select{},会永远地等待下去。
示例:
package main
import "time"
import "fmt"
// Go 的通道选择器 让你可以同时等待多个通道操作。
// Go 协程和通道以及选择器的结合是 Go 的一个强大特性。
func main() {
// 在我们的例子中,我们将从两个通道中选择。
c1 := make(chan string)
c2 := make(chan string)
// 各个通道将在若干时间后接收一个值,这个用来模拟例如并行的 Go 协程中阻塞的 RPC 操作
go func() {
time.Sleep(time.Second * 1)
c1 <- "one"
}()
go func() {
time.Sleep(time.Second * 2)
c2 <- "two"
}()
// 我们使用 select 关键字来同时等待这两个值,并打印各自接收到的值。
for i := 0; i < 2; i++ {
select {
case msg1 := <-c1:
fmt.Println("received", msg1)
case msg2 := <-c2:
fmt.Println("received", msg2)
}
}
// 我们首先接收到值 "one",然后就是预料中的 "two"了。
// 注意从第一次和第二次 Sleeps 并发执行,总共仅运行了两秒左右。
}
运行输出:
received one
received two
8、超时实现
package main
import "time"
import "fmt"
// 超时 对于一个连接外部资源,或者其它一些需要花费执行时间的操作的程序而言是很重要的。
// 得益于通道和 select,在 Go中实现超时操作是简洁而优雅的。
func main() {
c1 := make(chan string, 1)
// 在我们的例子中,假如我们执行一个外部调用,并在 2 秒后通过通道 c1 返回它的执行结果。
go func() {
time.Sleep(time.Second * 2)
c1 <- "result 1"
}()
// 这里是使用 select 实现一个超时操作。res := <- c1 等待结果,<-Time.After 等待超时时间 1 秒后发送的值。
// 由于 select 默认处理第一个已准备好的接收操作,如果这个操作超过了允许的 1 秒的话,将会执行超时 case。
select {
case res := <-c1:
fmt.Println(res)
case <-time.After(time.Second * 1):
fmt.Println("timeout 1")
}
// 如果我允许一个长一点的超时时间 3 秒,将会成功的从 c2接收到值,并且打印出结果。
c2 := make(chan string, 1)
go func() {
time.Sleep(time.Second * 2)
c2 <- "result 2"
}()
select {
case res := <-c2:
fmt.Println(res)
case <-time.After(time.Second * 3):
fmt.Println("timeout 2")
}
// 运行这个程序,首先显示运行超时的操作,然后是成功接收的。
// 使用这个 select 超时方式,需要使用通道传递结果。
// 这对于一般情况是个好的方式,因为其他重要的 Go 特性是基于通道和select 的。
}
运行输出:
timeout 1
result 2
9、非阻塞选择器
package main
import (
"fmt"
)
// 常规的通过通道发送和接收数据是阻塞的。
// 然而,我们可以使用带一个 default 子句的 select 来实现非阻塞 的发送、接收,甚至是非阻塞的多路 select。
func main() {
messages := make(chan string)
signals := make(chan bool)
// 这里是一个非阻塞接收的例子。
// 如果在 messages 中存在,然后 select 将这个值带入 <-messages case中。
// 如果不是,就直接到 default 分支中。
select {
case msg := <-messages:
fmt.Println("received message", msg)
default:
fmt.Println("no message received")
}
// 一个非阻塞发送的实现方法和上面一样。
msg := "hi"
select {
case messages <- msg:
fmt.Println("sent message", msg)
default:
fmt.Println("no message sent")
}
// 我们可以在 default 前使用多个 case 子句来实现一个多路的非阻塞的选择器。
// 这里我们试图在 messages和 signals 上同时使用非阻塞的接受操作。
select {
case msg := <-messages:
fmt.Println("received message", msg)
case sig := <-signals:
fmt.Println("received signal", sig)
default:
fmt.Println("no activity")
}
}
运行输出:
no message received
no message sent
no activity
十二、常用函数
字符串函数
package main
import s "strings"
import "fmt"
// 我们给 fmt.Println 一个短名字的别名,我们随后将会经常用到。
var p = fmt.Println
// 标准库的 strings 包提供了很多有用的字符串相关的函数。
// 这里是一些用来让你对这个包有个初步了解的例子。
func main() {
// 这是一些 strings 中的函数例子。
// 注意他们都是包中的函数,不是字符串对象自身的方法,这意味着我们需要考虑在调用时传递字符作为第一个参数进行传递。
p("Contains: ", s.Contains("test", "es"))
p("Count: ", s.Count("test", "t"))
p("HasPrefix: ", s.HasPrefix("test", "te"))
p("HasSuffix: ", s.HasSuffix("test", "st"))
p("Index: ", s.Index("test", "e"))
p("Join: ", s.Join([]string{"a", "b"}, "-"))
p("Repeat: ", s.Repeat("a", 5))
p("Replace: ", s.Replace("foo", "o", "0", -1))
p("Replace: ", s.Replace("foo", "o", "0", 1))
p("Split: ", s.Split("a-b-c-d-e", "-"))
p("ToLower: ", s.ToLower("TEST"))
p("ToUpper: ", s.ToUpper("test"))
// 你可以在 strings包文档中找到更多的函数
p()
// 虽然不是 strings 的一部分,但是仍然值得一提的是获取字符串长度和通过索引获取一个字符的机制。
p("Len: ", len("hello"))
p("Char:", "hello"[1])
}
运行输出:
Contains: true
Count: 2
HasPrefix: true
HasSuffix: true
Index: 1
Join: a-b
Repeat: aaaaa
Replace: f00
Replace: f0o
Split: [a b c d e]
ToLower: test
ToUpper: TEST
Len: 5
Char: 101
字符串格式化
package main
import "fmt"
import "os"
type point struct {
x, y int
}
func main() {
// Go 为常规 Go 值的格式化设计提供了多种打印方式。例如,这里打印了 point 结构体的一个实例。
p := point{1, 2}
fmt.Printf("%v\n", p)
// 如果值是一个结构体,%+v 的格式化输出内容将包括结构体的字段名。
fmt.Printf("%+v\n", p)
// %#v 形式则输出这个值的 Go 语法表示。例如,值的运行源代码片段。
fmt.Printf("%#v\n", p)
// 需要打印值的类型,使用 %T。
fmt.Printf("%T\n", p)
// 格式化布尔值是简单的。
fmt.Printf("%t\n", true)
// 格式化整形数有多种方式,使用 %d进行标准的十进制格式化。
fmt.Printf("%d\n", 123)
// 这个输出二进制表示形式。
fmt.Printf("%b\n", 14)
// 这个输出给定整数的对应字符。
fmt.Printf("%c\n", 33)
// %x 提供十六进制编码。
fmt.Printf("%x\n", 456)
// 对于浮点型同样有很多的格式化选项。使用 %f 进行最基本的十进制格式化。
fmt.Printf("%f\n", 78.9)
// %e 和 %E 将浮点型格式化为(稍微有一点不同的)科学技科学记数法表示形式。
fmt.Printf("%e\n", 123400000.0)
fmt.Printf("%E\n", 123400000.0)
// 使用 %s 进行基本的字符串输出。
fmt.Printf("%s\n", "\"string\"")
// 像 Go 源代码中那样带有双引号的输出,使用 %q。
fmt.Printf("%q\n", "\"string\"")
// 和上面的整形数一样,%x 输出使用 base-16 编码的字符串,每个字节使用 2 个字符表示。
fmt.Printf("%x\n", "hex this")
// 要输出一个指针的值,使用 %p。
fmt.Printf("%p\n", &p)
// 当输出数字的时候,你将经常想要控制输出结果的宽度和精度,可以使用在 % 后面使用数字来控制输出宽度。
// 默认结果使用右对齐并且通过空格来填充空白部分。
fmt.Printf("|%6d|%6d|\n", 12, 345)
// 你也可以指定浮点型的输出宽度,同时也可以通过 宽度.精度 的语法来指定输出的精度。
fmt.Printf("|%6.2f|%6.2f|\n", 1.2, 3.45)
// 要左对齐,使用 - 标志。
fmt.Printf("|%-6.2f|%-6.2f|\n", 1.2, 3.45)
// 你也许也想控制字符串输出时的宽度,特别是要确保他们在类表格输出时的对齐。
// 这是基本的右对齐宽度表示。
fmt.Printf("|%6s|%6s|\n", "foo", "b")
// 要左对齐,和数字一样,使用 - 标志。
fmt.Printf("|%-6s|%-6s|\n", "foo", "b")
// 到目前为止,我们已经看过 Printf了,它通过 os.Stdout输出格式化的字符串。
// Sprintf 则格式化并返回一个字符串而不带任何输出。
s := fmt.Sprintf("a %s", "string")
fmt.Println(s)
// 你可以使用 Fprintf 来格式化并输出到 io.Writers而不是 os.Stdout。
fmt.Fprintf(os.Stderr, "an %s\n", "error")
}
运行输出:
{1 2}
{x:1 y:2}
main.point{x:1, y:2}
main.point
true
123
1110
!
1c8
78.900000
1.234000e+08
1.234000E+08
"string"
"\"string\""
6865782074686973
0xc0000180a0
| 12| 345|
| 1.20| 3.45|
|1.20 |3.45 |
| foo| b|
|foo |b |
a string
an error
数字转换
package main
import "strconv"
import "fmt"
// 从字符串中解析数字在很多程序中是一个基础常见的任务,在Go 中是这样处理的。
func main() {
// 内置的 strconv 包提供了数字解析功能。
// 使用 ParseFloat 解析浮点数,这里的 64 表示表示解析的数的位数。
f, _ := strconv.ParseFloat("1.234", 64)
fmt.Println(f)
// 在使用 ParseInt 解析整形数时,例子中的参数 0 表示自动推断字符串所表示的数字的进制。
// 64 表示返回的整形数是以 64 位存储的。
i, _ := strconv.ParseInt("123", 0, 64)
fmt.Println(i)
// ParseInt 会自动识别出十六进制数。
d, _ := strconv.ParseInt("0x1c8", 0, 64)
fmt.Println(d)
// ParseUint 也是可用的。
u, _ := strconv.ParseUint("789", 0, 64)
fmt.Println(u)
// Atoi 是一个基础的 10 进制整型数转换函数。
k, _ := strconv.Atoi("135")
fmt.Println(k)
// 在输入错误时,解析函数会返回一个错误。
_, e := strconv.Atoi("wat")
fmt.Println(e)
}
运行输出:
1.234
123
456
789
135
strconv.Atoi: parsing "wat": invalid syntax
时间函数
package main
import "fmt"
import "time"
func main() {
p := fmt.Println
// 得到当前时间。
now := time.Now()
p(now)
// 通过提供年月日等信息,你可以构建一个 time。时间总是关联着位置信息,例如时区。
then := time.Date(2009, 11, 17, 20, 34, 58, 651387237, time.UTC)
p(then)
// 你可以提取出时间的各个组成部分。
p(then.Year())
p(then.Month())
p(then.Day())
p(then.Hour())
p(then.Minute())
p(then.Second())
p(then.Nanosecond())
p(then.Location())
// 输出是星期一到日的 Weekday 也是支持的。
p(then.Weekday())
// 这些方法来比较两个时间,分别测试一下是否是之前,之后或者是同一时刻,精确到秒。
p(then.Before(now))
p(then.After(now))
p(then.Equal(now))
// 方法 Sub 返回一个 Duration 来表示两个时间点的间隔时间。
diff := now.Sub(then)
p(diff)
// 我们计算出不同单位下的时间长度值。
p(diff.Hours())
p(diff.Minutes())
p(diff.Seconds())
p(diff.Nanoseconds())
// 你可以使用 Add 将时间后移一个时间间隔,或者使用一个 - 来将时间前移一个时间间隔。
p(then.Add(diff))
p(then.Add(-diff))
p("################")
// 格式化
// 这里是一个基本的按照 RFC3339 进行格式化的例子,使用对应模式常量。
t := time.Now()
p(t.Format(time.RFC3339))
// 时间解析使用同 Format 相同的形式值。
t1, e := time.Parse(time.RFC3339, "2012-11-01T22:08:41+00:00")
p(t1)
// Format 和 Parse 使用基于例子的形式来决定日期格式,
// 一般你只要使用 time 包中提供的模式常量就行了,但是你也可以实现自定义模式。
// 模式必须使用时间 Mon Jan 2 15:04:05 MST 2006来指定给定时间/字符串的格式化/解析方式。
// 时间一定要按照如下所示:2006为年,15 为小时,Monday 代表星期几,等等。
p(t.Format("3:04PM"))
p(t.Format("Mon Jan _2 15:04:05 2006"))
p(t.Format("2006-01-02T15:04:05.999999-07:00"))
form := "3 04 PM"
t2, e := time.Parse(form, "8 41 PM")
p(t2)
// 对于纯数字表示的时间,你也可以使用标准的格式化字符串来提出出时间值得组成。
fmt.Printf("%d-%02d-%02dT%02d:%02d:%02d-00:00\n",
t.Year(), t.Month(), t.Day(),
t.Hour(), t.Minute(), t.Second()
)
// Parse 函数在输入的时间格式不正确是会返回一个错误。
ansic := "Mon Jan _2 15:04:05 2006"
_, e = time.Parse(ansic, "8:41PM")
p(e)
}
运行输出:
2021-10-29 14:28:24.8072737 +0800 CST m=+0.002001701
2009-11-17 20:34:58.651387237 +0000 UTC
2009
November
17
20
34
58
651387237
UTC
Tuesday
true
false
false
104721h53m26.155886463s
104721.89059885735
6.283313435931441e+06
3.769988061558865e+08
376998806155886463
2021-10-29 06:28:24.8072737 +0000 UTC
1997-12-07 10:41:32.495500774 +0000 UTC
################
2021-10-29T14:28:24+08:00
2012-11-01 22:08:41 +0000 +0000
2:28PM
Fri Oct 29 14:28:24 2021
2021-10-29T14:28:24.820275+08:00
0000-01-01 20:41:00 +0000 UTC
2021-10-29T14:28:24-00:00
parsing time "8:41PM" as "Mon Jan _2 15:04:05 2006": cannot parse "8:41PM" as "Mon"
JSON转换
package main
import "encoding/json"
import "fmt"
import "os"
// 下面我们将使用这两个结构体来演示自定义类型的编码和解码。
type Response1 struct {
Page int
Fruits []string
}
type Response2 struct {
Page int `json:"page"`
Fruits []string `json:"fruits"`
}
func main() {
// 首先我们来看一下基本数据类型到 JSON 字符串的编码过程。这里是一些原子值的例子。
bolB, _ := json.Marshal(true)
fmt.Println(string(bolB))
intB, _ := json.Marshal(1)
fmt.Println(string(intB))
fltB, _ := json.Marshal(2.34)
fmt.Println(string(fltB))
strB, _ := json.Marshal("gopher")
fmt.Println(string(strB))
// 这里是一些切片和 map 编码成 JSON 数组和对象的例子。
slcD := []string{"apple", "peach", "pear"}
slcB, _ := json.Marshal(slcD)
fmt.Println(string(slcB))
mapD := map[string]int{"apple": 5, "lettuce": 7}
mapB, _ := json.Marshal(mapD)
fmt.Println(string(mapB))
// JSON 包可以自动的编码你的自定义类型。
// 编码仅输出可导出的字段,并且默认使用他们的名字作为 JSON 数据的键。
res1D := &Response1{
Page: 1,
Fruits: []string{"apple", "peach", "pear"}}
res1B, _ := json.Marshal(res1D)
fmt.Println(string(res1B))
// 你可以给结构字段声明标签来自定义编码的 JSON 数据键名称。
// 在上面 Response2 的定义可以作为这个标签这个的一个例子。
res2D := &Response2{
Page: 1,
Fruits: []string{"apple", "peach", "pear"}}
res2B, _ := json.Marshal(res2D)
fmt.Println(string(res2B))
// 现在来看看解码 JSON 数据为 Go 值的过程。
// 这里是一个普通数据结构的解码例子。
byt := []byte(`{"num":6.13,"strs":["a","b"]}`)
// 我们需要提供一个 JSON 包可以存放解码数据的变量。
// 这里的 map[string]interface{} 将保存一个 string 为键,值为任意值的map。
var dat map[string]interface{}
// 这里就是实际的解码和相关的错误检查。
if err := json.Unmarshal(byt, &dat); err != nil {
panic(err)
}
fmt.Println(dat)
// 为了使用解码 map 中的值,我们需要将他们进行适当的类型转换。
// 例如这里我们将 num 的值转换成 float64类型。
num := dat["num"].(float64)
fmt.Println(num)
// 访问嵌套的值需要一系列的转化。
strs := dat["strs"].([]interface{})
str1 := strs[0].(string)
fmt.Println(str1)
// 我们也可以解码 JSON 值到自定义类型。
// 这个功能的好处就是可以为我们的程序带来额外的类型安全加强,并且消除在访问数据时的类型断言。
str := `{"page": 1, "fruits": ["apple", "peach"]}`
res := Response2{}
json.Unmarshal([]byte(str), &res)
fmt.Println(res)
fmt.Println(res.Fruits[0])
// 在上面的例子中,我们经常使用 byte 和 string 作为使用标准输出时数据和 JSON 表示之间的中间值。
// 我们也可以和os.Stdout 一样,直接将 JSON 编码直接输出至 os.Writer流中,或者作为 HTTP 响应体。
enc := json.NewEncoder(os.Stdout)
d := map[string]int{"apple": 5, "lettuce": 7}
enc.Encode(d)
}
运行输出:
true
1
2.34
"gopher"
["apple","peach","pear"]
{"apple":5,"lettuce":7}
{"Page":1,"Fruits":["apple","peach","pear"]}
{"page":1,"fruits":["apple","peach","pear"]}
map[num:6.13 strs:[a b]]
6.13
a
{1 [apple peach]}
apple
{"apple":5,"lettuce":7}
文件写入
package main
import (
"bufio"
"fmt"
"io/ioutil"
"os"
)
// Go 写文件和我们前面看过的读操作有着相似的方式。
// 读取文件需要经常进行错误检查,这个帮助方法可以精简下面的错误检查过程。
func check(e error) {
if e != nil {
panic(e)
}
}
func main() {
d1 := []byte("hello\ngo\n")
// 开始,这里是展示如写入一个字符串(或者只是一些字节)到一个文件。
err := ioutil.WriteFile("D:/study/dat1", d1, 0644)
check(err)
// 对于更细粒度的写入,先打开一个文件。
f, err := os.Create("D:/study/dat2")
check(err)
// 打开文件后,习惯立即使用 defer 调用文件的 Close操作。
defer f.Close()
// 你可以写入你想写入的字节切片
d2 := []byte{115, 111, 109, 101, 10}
n2, err := f.Write(d2)
check(err)
fmt.Printf("wrote %d bytes\n", n2)
// WriteString 也是可用的。
n3, err := f.WriteString("writes\n")
fmt.Printf("wrote %d bytes\n", n3)
// 调用 Sync 来将缓冲区的信息写入磁盘。
f.Sync()
// bufio 提供了和我们前面看到的带缓冲的读取器一样的带缓冲的写入器。
w := bufio.NewWriter(f)
n4, err := w.WriteString("buffered\n")
fmt.Printf("wrote %d bytes\n", n4)
// 使用 Flush 来确保所有缓存的操作已写入底层写入器。
w.Flush()
}
十三、服务
HTTP服务
package main
import (
"fmt"
"log"
"net/http"
)
func main() {
http.HandleFunc("/",Index)
log.Fatal(http.ListenAndServe(":8080", nil))
}
func Index(w http.ResponseWriter, r *http.Request){
fmt.Fprint(w,"Search:www.baidu.com\nWechat:qq.com")
}
打开浏览器访问 http://localhost:8080 ,返回:
Search:www.baidu.com
Wechat:qq.com
十四、高级函数
函数的数据类型
package main
import "fmt"
func main() {
a := 10
fmt.Printf("%T\n", a)
b := [4]int{1, 2, 3, 4}
fmt.Printf("%T\n", b)
c := []int{1, 2, 3, 43}
fmt.Printf("%T\n", c)
d := make(map[int]string)
fmt.Printf("%T\n", d)
//不能加括号,否则就是调用
fmt.Printf("%T\n", f1) //func
fmt.Printf("%T\n", f2) //func(int)int
}
func f1() {
}
func f2(a int) int {
return 0
}
输出:
int
[4]int
[]int
map[int]string
func()
func(int) int
函数的类型:func(参数类型)(返回值类型)
函数也是一种数据类型
函数的本质
函数类型的变量
package main
import "fmt"
func main() {
//函数也是一个变量
fmt.Printf("%T\n", f1)
fmt.Println(f1)
//f1看着对应函数名对应函数体的地址0x27fd40
//f1()带括号就是将函数直接调用
//直接定义一个函数类型的变量
var c func(int, int)
fmt.Println(c)
//将格式相同的f1给c进行函数赋值
c = f1
fmt.Println(c) //和f1地址相同
f1(1, 2)
c(10, 20) //c也是函数类型的,可以直接调用了
}
func f1(a, b int) {
fmt.Printf("a:%d,b %d\n", a, b)
}
输出:
func(int, int)
0x77fb00
<nil>
0x77fb00
a:1,b 2
a:10,b 20
函数在Go语害中是复合类型,可以看做是一种特殊的变量。
函数名():调用返回结果
函数名:指向函数体的内存地址,一种特殊类型的指针变量
匿名函数
package main
import "fmt"
func main() {
//匿名函数就是没有名字的函数
f1()
f2 := f1
f2()
//匿名函数,函数体后增加一个()执行,通常只能执行一次
//func() {
// fmt.Println("我是一个匿名函数")
//}()
//将匿名函数赋值,单独进行调用
f3 := func() {
fmt.Println("我是一个匿名函数...")
}
f3()
//定义带参数的匿名函数
func(a, b int) {
fmt.Println(a, b)
}(1, 2)
//定义带返回值的匿名函数
r1 := func(a, b int) int {
return a + b
}(10, 20) //带了括号就是函数调用
fmt.Println(r1)
r2 := func(a, b int) int {
return a + b
} //将匿名函数赋值给了r2
fmt.Println(r2)
}
func f1() {
fmt.Println("我是f1函数")
}
输出:
我是f1函数
我是f1函数
我是一个匿名函数...
1 2
30
0xb1e0a0
Go语言是支持函数式编程:
- 将匿名函数作为另外一个函数的参数,回调函数
- 将匿名函数作为另外一个函数的返回值,可以形成闭包结构
回调函数
高阶函数:根据Go语言的数据类型的特点,可以将一个函数作为另外一个函数的参数。
fun1(), fun2()
将fun1函数作为fun2这个函数的参数
fun2函数:就叫做高阶函数,接收了一个函数作为参数的函数
fun1函数:就叫做回调函数,作为另外一个函数的参数
package main
import "fmt"
func main() {
//调用函数
r1 := add(1, 2)
fmt.Println(r1)
//高阶函数,add函数作为参数传递给oper函数
r2 := oper(10, 20, add)
fmt.Println(r2)
//尝试举一反三
r3 := oper(10, 20, sub)
fmt.Println(r3)
//匿名函数
fun1 := func(a, b int) int {
return a * b
}
r4 := oper(11, 22, fun1)
fmt.Println(r4)
//直接传递匿名函数
r5 := oper(4, 2, func(a int, b int) int {
if b == 0 {
fmt.Println("除数不能为0")
return 0
}
return a / b
})
fmt.Println(r5)
}
func add(a, b int) int {
return a + b
}
func oper(a, b int, fun func(int, int) int) int {
fmt.Println(a, b, fun) //打印参数查看
r := fun(a, b)
return r
}
func sub(a, b int) int {
return a - b
}
输出:
3
10 20 0x1ce060
30
10 20 0x1ce180
-10
11 22 0x1ce1a0
242
4 2 0x1ce1c0
2
闭包
package main
import "fmt"
/*
一个外层函数中,有内层函数,该内层函数中,会操作外层函数的局部变量
并且该外层函数的返回值就是这个内层函数。
这个内层函数和外层函数的局部变量,统称为闭包结构
局部变量的生命周期就会发生改变,正常的局部变量会随着函数的调用而创建,随着函数的结束而销毁
但是闭包结构中的外层函数的局部变量并不会随着外层函数的结束而销毁,因为内层函数还在继续使用
*/
func main() {
r1 := increment()
fmt.Println(r1)
v1 := r1()
fmt.Println(v1)
v2 := r1()
fmt.Println(v2)
fmt.Println(r1())
fmt.Println(r1())
fmt.Println(r1())
fmt.Println("----------------")
r2 := increment() //和r1指向同一个地址
fmt.Println(r2)
v3 := r2()
fmt.Println(v3)
fmt.Println(r1())
fmt.Println(r2())
}
// 自增
func increment() func() int { //外层函数
//定义一个局部变量
i := 0
//定义一个匿名函数,给变量自增并返回
fun := func() int { //内存函数 没有执行。
i++
return i
}
//返回该匿名函数
return fun
}
输出:
0x61e260
1
2
3
4
5
----------------
0x61e260
1
6
2
参考资料
golang基础教程-go语言快速入门 blibli https://www.bilibili.com/video/av94410029
【狂神说】Go语言零基础学习视频通俗易懂 https://www.bilibili.com/video/BV1ae41157o9
github:https://github.com/goflyfox/gostudy
gitee:https://gitee.com/goflyfox/gostudy
腾讯课堂教程地址:golang基础教程-快速入门go语言
bilibili教程地址:golang基础教程-快速入门go语言
西瓜视频教程地址:golang基础教程-快速入门go语言
win10系统环境变量怎么设置 https://jingyan.baidu.com/article/00a07f3876cd0582d128dc55.html
Go语言入门教程,Golang入门教程 http://c.biancheng.net/golang/ 比较详细
Go错误处理:深入理解fmt.Errorf, errors.Wrap和errors.Wrapf https://cloud.tencent.com/developer/article/2311646