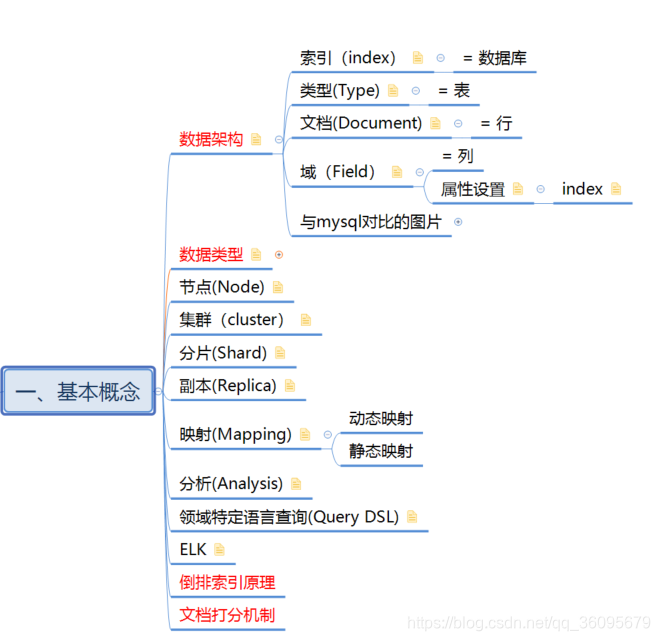
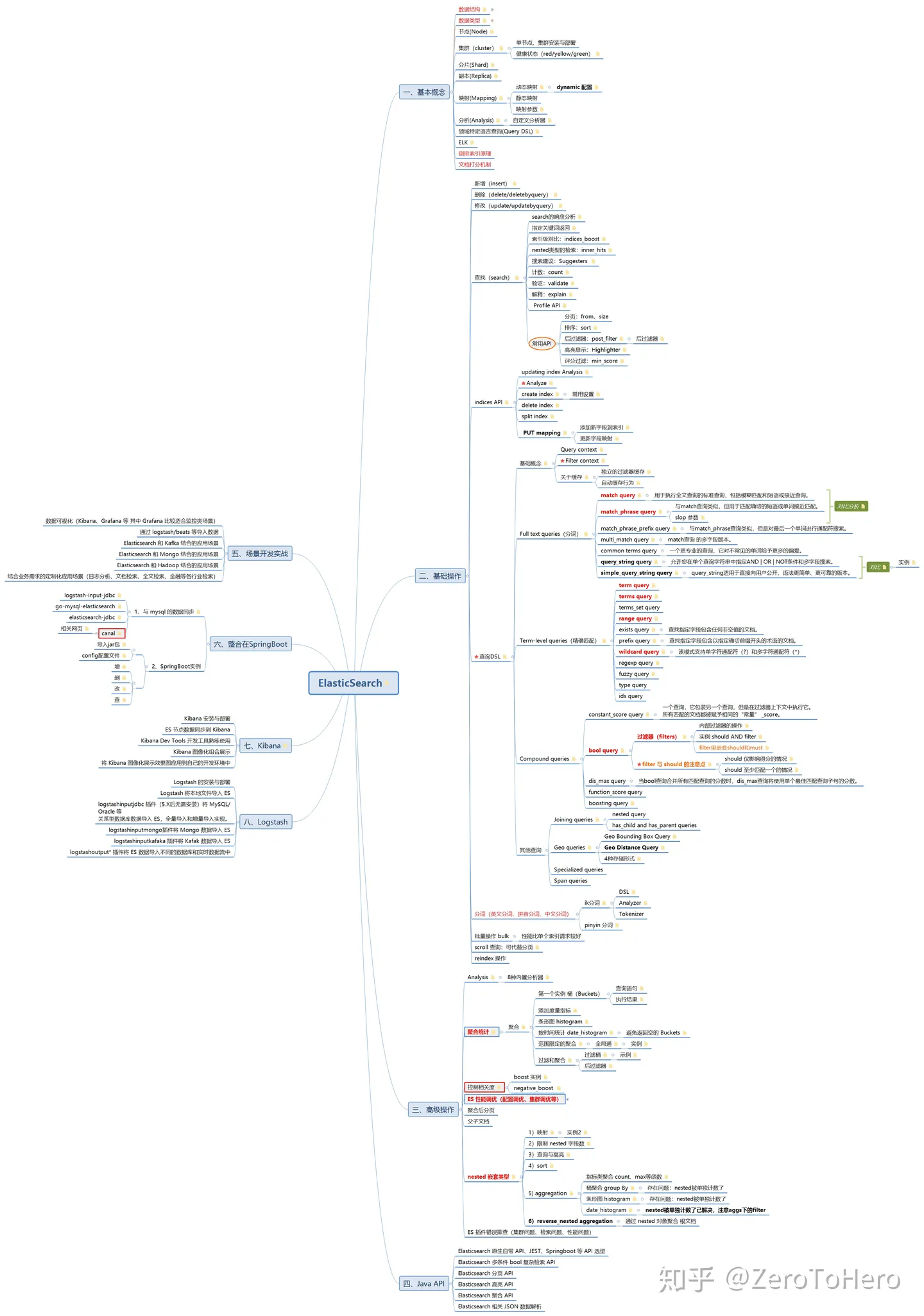
思维导图


基本操作
Elasticsearch 提供 RESTful 的 API 对文档的操作也是增删查改,语法设计的主要内容就是 HTTP 请求的动作, HTTP 请求的路径,请求体。
创建索引
直接运行:
curl -XPUT "localhost:9200/index_test"
会创建名为index_test的索引,ES会根据插入的数据自动创建type与mapping,可以通过配置文件关闭ES的自动创建mapping功能。
也可以手动指定mapping,请求方式如下:
curl -XPUT "localhost:9200/index_test" -d ' # 注意这里的'号
{
"settings": {
"index": {
"number_of_replicas": "1", # 设置复制数
"number_of_shards": "5" # 设置主分片数
}
},
"mappings": { # 创建mapping
"test_type": { # 在index中创建一个新的type(相当于table)
"properties": {
"name": { # 创建一个字段(string类型数据,使用普通索引)
"type": "string",
"index": "not_analyzed"
},
"age": {
"type": "integer"
}
}
}
}
}
查看mapping:
curl -XGET 'localhost:9200/index_test/_mapping/test_type'
删除mapping:
curl -XDELETE 'localhost:9200/index_test/_mapping/test_type'
删除该索引:
curl -XDELETE "localhost:9200/index_test"
增
Elasticsearch 中的增是由 HTTP PUT 方法完成的,路径指定使用的索引和文档 Id(索引无则自动创建,没有 Id 则随即生成), 请求体是文档体(以 json 形式)。
新增一条,使用 _doc 端点新增一个文档(books 即为文档归属的索引),1 即文档 Id
PUT books/_doc/1
{
"title":"Effective Java",
"author":"Joshua Bloch",
"release_date":"2001-06-01",
"amazon_rating":4.7,
"best_seller":true,
"prices": {
"usd":9.95,
}
}
批量新增多个文档:
POST _bulk
{"index":{"_index":"books","_id":"1"}}
{"title": "titlePHP,"author": "author1","edition": 11, "synopsis": "PHP synopsis","amazon_rating": 4.6,"release_date": "2018-08-27","tags": ["Programming Languages, PHP Programming"]}
{"index":{"_index":"books","_id":"2"}}
{"title": "titleJAVA","author": "author2", "edition": 3,"synopsis": "JAVA synopsis", "amazon_rating": 4.7, "release_date": "2017-12-27", "tags": ["Object Oriented Software Design"]}
注意这里的请求体并非是一个常规的 json,这里是使用 多个 json 组成的,每两个 json 为一组,前一个制定索引和 Id,后一个指定文档体。
查
计数
通过索引下的 _count 端点
GET /books/_count
根路径下的 _count 端点返回所有索引的文档数量。
通过 Id 查询文档
通过索引下的 _doc 或 _source 端点和文档 Id
GET /books/_doc/1
GET /books/_source/1
搜索文档(包括聚合)
通过索引下的 _search 端点和查询请求体。
Elasticsearch 存在许多复杂请求基本都是依靠请求体进行的。
查询指定属性:
GET books/_search
{
"query": {
"match": {
"author": "Joshua"
}
}
}
结构化查询(如查询age在18-60之间的文档):
GET books/_search
{
"query": {
"range":{
"age{
"gte":18,
"lte":60
}
}
}
}
也支持filter操作,速度比query快,需要结合布尔类型使用。
多个条件联合查询(如查找name中包含“一页书“且age为18的文档):
GET books/_search
{
"query": {
“bool”: {
"must":[
{
"match":{
"name":"一页书"
}
},
{
"filter":{
"term"{
"age":18
}
}
]
}
}
}
支持must(与)、should(或)、must not等逻辑运算。
match、macth_phrase、multi_match与term的区别
match对会先对query进行分词,只要文档里面包含一个query中一个词就会被搜出来;
macth_phrase也会对query进行分词,但一个文档必须包含query里面所有的词才会被搜出来,可以通过slop参数降低这种约束;
GET books/_search
{
"query": {
"match_phrase": {
"content" : {
"query" : "我的宝马多少马力",
"slop" : 1
}
}
}
}
multi_match对多个字段同时进行匹配;
term表示完全匹配,不对query进行分词,直接去匹配索引。
更新
修改整条数据(也可用PUT):
POST books/_doc/1
{
"title":"Effective Java",
"author":"Joshua Bloch",
"release_date":"2001-06-01",
"amazon_rating":4.7,
"best_seller":true,
"prices": {
"usd":9.95,
}
}
只修改里面的一部分字段(只能使用POST):
POST books/_update/1
{
"doc": {
"title":"JS"
}
}
删除
DELETE books/_doc/1
讲解一
1、Elasticsearch是什么
1.1 概念:
Elasticsearch是由]ava语言开发基于Lucene的一款开源的搜索、聚合分析和存储引擎。同时它也可以称作是一种非关系型文档数据库。
1.2 特点:
- 天生分布式、高性能、高可用、易扩展、易维护。
- 跨语言、跨平台:几乎支持所有主流编程语言,并且支持在”Linux、Windows、MacOS”多平台部署
- 支持结构化、非结构化、地理位置搜索等
1.3 适用场景:
- 海量数据的全文检索,搜索引擎、垂直搜索、站内搜索:
- 百度、知乎、微博、CSDN
- 导航、外卖、团购等软件
- 以京东、淘宝为代表的垂直搜索
- B站、抖音、爱奇艺、QQ音乐等音视频软件
- Github
- 数据分析和聚合查询
- 日志系统:ELK
2、mapping是什么,你知道es哪些数据类型?
2.1 概念:
ES中的mapping有点类似与RDB中“表结构”的概念,在MySQL中,表结构里包含了字段名称,字段的类型还有索引信息等。 在Mapping里也包含了一些属性,比如字段名称、类型、字段使用的分词器、是否评分、是否创建索引等属性, 并且在ES中一个字段可以有对个类型。分词器、评分等概念在后面的课程讲解。
2.2 ES数据类型
2.2.1 常见类型
1- 数字类型:long 、 integer 、 short 、byte 、 double 、 float 、 half_float 、 scaled_float 、unsigned_long
2- Keywords:
- keyword: 适用于索引结构化的字段,可以用于过滤、排序、聚合。keyword类型的字段只能过精确值(exact value)搜索到。 Id应该用keyword.。keyword字段通常用于排序,汇总和Term查询,例如term。
- constant keyword: 始终包含相同值的关键字字段
- wildcard: 可针对类似grep的通配符查询优化日志行和类似的关键字值
3- dates(时间类型):包括date和date_nanos,
4- alias: 为现有字段定义别名。
5- text: 当一个字段是要被全文搜索的,比如Email内容、产品描述,这些字段应该使用text类型。 设置text类型以后,字段内容会被分析,在生成倒排索引以前,字符串会被分析器分成一个一个词项。 text类型的字段不用于排序,很少用于聚合。(解释一下为啥不会为text创建正排索引:大量堆空间, 尤其是在加载高基数text字段时。字段数据一旦加载到堆中,就在该段的生命周期内保持在那里。 同样,加载字段数据是一个昂贵的过程,可能导致用户遇到延迟问题。这就是默认情况下禁用字段数据的原因)
2.2.2 对象关系类型
- object:用于单个JSON对象
- nested:用于JSON对象数组
- join: 为同一索引中的文档定义父/子关系。
2.2.3 结构化类型
- geo-point: 纬度/经度积分
- geo-shape: 用于多边形等复杂形状
- point: 笛卡尔坐标点
- shape: 笛卡尔任意几何图形
2.3 自动映射和手工映射
2.3.1 Dynamic field mapping:
整数 => long
浮点数 => float
true || false => boolean
日期 => date
数组 => 取决于数组中的第一个有效值
对象 => object
字符串类型 => 如果不是数字和日期类型,那会被映射为text和keyword两个
除了上述字段类型之外,其他类型都必须显示映射,也就是必须手工指定,因为其他类型ES无法自动识别。
2.3.2 Expllcit field mapping: 手动映射
PUT /product
{
"mappings": {
"properties": {
"field":{
"mapping_parameter": "parameter_value"
}
}
}
}
2.4 映射参数
- index:是否对创建对当前字段创建倒排索引,默认true,如果不创建索引,该字段不会通过索引被搜索到,但是仍然会在source元数据中展示
- analyzer:指定分析器(character filter、tokenizer、.Token filters)。
- boost:对当前字段相关度的评分权重,默认1
- coerce:是否允许强制类型转换 true “1” => 1 false “1” =< 1
- copy to:该参数允许将多个字段的值复制到组字段中,然后可以将其作为单个字段进行查询
- doc values:为了提升排序和聚合效率,默认true,如果确定不需要对字段进行排序或聚合,也不需要通过脚本访问字段值, 则可以禁用doc值以节省磁盘空间(不支持text和annotated text)
- dynamic:控制是否可以动态添加新字段
- 1.true新检测到的字段将添加到映射中。(默认)
- 2.false新检测到的字段将被忽略。这些字段将不会被索引,因此将无法搜索,但仍会出现在source返回的匹配项中。 这些字段不会添加到映射中,必须显式添加新字段。
- 3.strict如果检测到新字段,则会引发异常并拒绝文档。必须将新字段显式添加到映射中
- eager_global_ordinals:用于聚合的字段上,优化聚合性能。
- Frozen indices(冻结索引:有些索引使用率很高,会被保存在内存中,有些使用率特别低,宁愿在使用的时候重新创建, 在使用完毕后丢弃数据,Frozen indices的数据命中频率小,不适用于高搜索负载,数据不会被保存在内存中, 堆空间占用比普通索引少得多,Frozen indices是只读的,请求可能是秒级或者分钟级。*eager global ordinals?不适用于Frozen indices
- enable:是否创建倒排索引,可以对字段操作,也可以对索引操作,如果不创建索引,让然可以检索并在source元数据中展示,
通慎使用,该状态无法修改。fielddata:查询时内存数据结构,在首次用当前字段聚合、排序或者在脚本中使用时,
需要字段为fielddata数据结构,并且创建倒排索l保存到堆中
PUT my_index "mappings": "enabled":false - *fields:给field创建多字段,用于不同目的(全文检索或者聚合分析排序)
- format:格式化
"date": "type":"date", "format":"yyyy-MM-dd" - ignore above:超过长度将被忽略
- ignore malformed:忽路类型错误
- index options:控制将哪些信息添加到反向索引中以进行搜索和突出显示。仅用于text字段
- Index phrases:提升exact value查询速度,但是要消耗更多磁盘空间
- Index prefixes:前缀搜索
- 1.min chars:前缀最小长度,>0,默认2(包含)》
- 2.max chars:.前缀最大长度,<20,默认5(包含)】
- meta:附加元数据
- normalizer:
- norms:是否禁用评分(在filter和聚合字段上应该禁用)。
- null value:为null值设置默认值*
- position increment gap:
- proterties:除了mapping还可用于object的属性设置
- search analyzer:设置单独的查询时分析器:
- similarity:为字段设置相关度算法,支持BM25、claassic(TF-lDF)、boolean
- store:设置字段是否仅查询
- term vector:*运维参数
3、什么是全文检索
3.1 相关度
- 搜索:有明确的查询边界
- 检索:讲究相关度,无明确的查询条件边界
3.2 图解全文检索
倒排索引
切词:word segmentation
规范化:normalization
去重:distinct
字典序:sorted
相关度排名
4、ES支持哪些类型的查询
此题目答案不唯一,按照不同的分类方式,答案也不一样
4.1 按语言划分
4.1.1 Query DSL: Domain Specific Language
4.1.2 Script: 脚本查询
4.1.3 Aggregations: 聚合查询
4.1.4 SQL查询
4.1.5 EQL查询
4.2 按场景划分
4.2.1 Query String
- 查询所有:
GET /product/_search - 带参数:
GET /product/_search?q=name:xiaomi - 分页:
GET /product/_search?from=0&size=2&sort=price:asc - 精准匹配 exact value:
GET /product/_search?q=date:2021-06-01 _all搜索相当于在所有有索引的字段中检索:GET /product/_sexrch?q=2021-06-01
#验证a11搜索
PUT product
{
"mappings": {
"properties": {
"desc": {
"type":"text",
"index":false
}
}
}
}
#先初始化数据
POST /product/_update/5
{
"doc": {
"desc":"erji zhong de kendeji 2021-06-01"
}
}
4.2.2 全文检索 - Fulltext query
GET index/search
{
"query": {
***
}
}
- match: 匹配包含某个term的子句
- match_all: 匹配所有结果的子句
- multi_match: 多字段条件
- match_phrase: 短语查询
4.2.3 精准查询- Term query
term: 匹配和搜索词项完全相等的结果
- term 和 match phrasel区别:
- match phrase 会将检索关键词分词,match phrase 的分词结果必须在被检索字段的分词中都包含,而且顺序必须相同,而且默认必须都是连续的
- term 搜索不会将搜索词分词
- term 和 keyword 区别
- term 是对于搜索词不分词
- keyword 是字段类型,是对于 source data 中的字段值不分词
terms: 匹配和搜索词项列表中任意项匹配的结果
range: 范围查找
4.2.4 过滤器- Filter
GET _search
{
"query": {
"constant_score": {
"filter": {
"term": {
"status":"active"
}
}
}
}
}
- filter: query和filter的主要区别在:filter是结果导向的而query是过程导向。 query倾向于”当前文档和查询的语句的相关度”而filter倾向于”当前文档和查询的条件是不是相符”。 即在查询过程中,query:是要对查询的每个结果计算相关性得分的,而filter不会。另外filter有相应的缓存机制,可以提高查询效率。
4.2.5 组合查询- Bool query
bool: 可以组合多个查询条件,bool查询也是采用more matches is better的机制,因此满足must和should子句的文档将会合并起来计算分值
- must:必须满足子句(查询)必须出现在匹配的文档中,并将有助于得分。
- filter:过滤器不计算相关度分数,cache女子句(查询)必须出现在匹配的文档中。但是不像must查询的分数将被忽略。 Filter子句在filter上下文中执行,这意味着计分被忽略,并且子句被考虑用于缓存。
- should:可能满足or子句(查询)应出现在匹配的文档中。
- must not:必须不满足不计算相关度分数not子句(查询)不得出现在匹配的文档中。子句在过滤器上下文中执行, 这意味着计分被忽略,并且子句被视为用于缓存。由于忽略计分,0因此将返回所有文档的分数。
minimum_should_match: 参数指定should返回的文档必须匹配的子句的数量或百分比。如果bool查询包含至少一个should子句, 而没有must或filter子句,则默认值为1。否则,默认值为0
4.2.6 地理位置搜索
4.2.7 嵌套查询:Object 、 Nested 、 Join
4.3 按数据类型(准确度)划分
4.3.1 全文检索:match
4.3.2 精确查找:term
4.3.3 模糊查询:suggester、模糊查询、通配符、正则查找
5、term、natch有何区别,你还知道哪些检索类型
5.1 term 和 match
term: 对搜索词不分词,不影响源数据
match: 对搜索词分词,不影响源数据
5.2 term和keyword
term: 检索类型
keyword: 字段类型
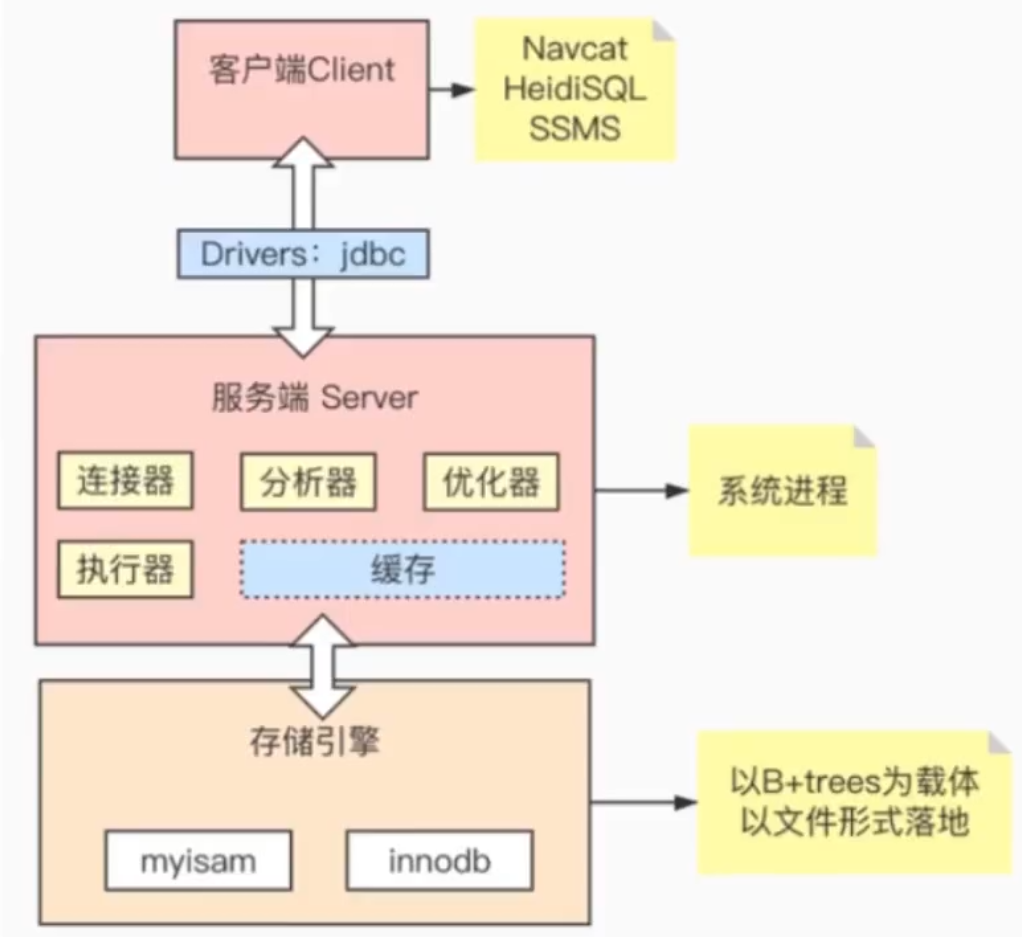
6、为什么MySQL(B+Trees)不适合做全文检索?
数据结构学习网站:https://www.cs.usfca.edu/~galles/visualization/Algorithms.html
文件页,最小 4KB
DataMapper 数据页
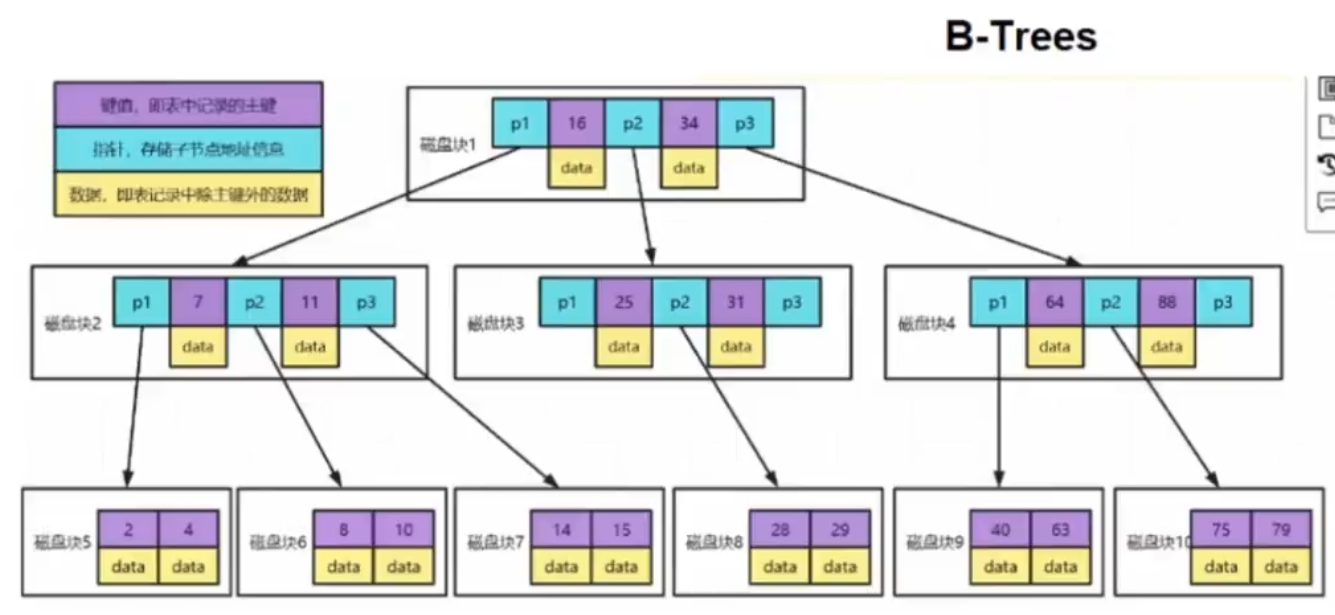
B-Trees:B树,最小 16KB
B+Trees:B加树
6.1 什么是索引
- 帮助快速检索
- 以数据结构为载体
- 以文件的形式落地
6.2 数据库的组成
6.3 B-Trees的数据结构
6.4 B+Trees的数据结构
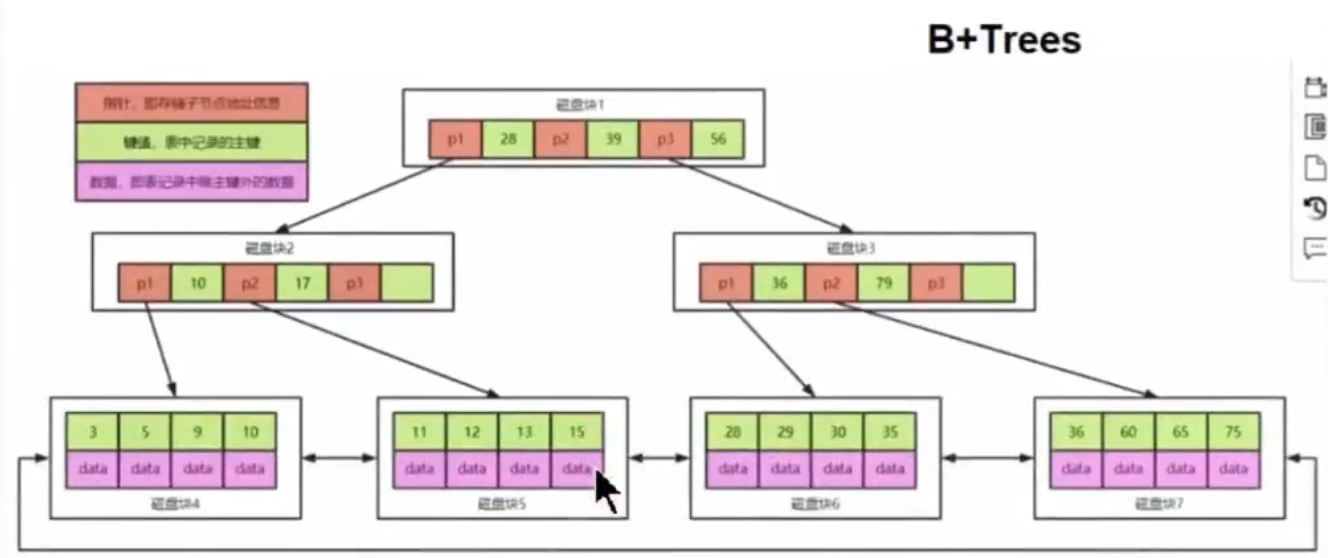
6.5 B+Trees做全文检索的弊端
1.索引往往字段很长,如果使用B+trees,树可能很深,IO很可怕
2.性能无法保证并且索引会失效
3.精准度差(相度低),并且无法和其他属性产生相关性
6.6、倒排索引的数据结构
索引:对Mysql来说,是B+树,对Elasticsearch/Lucene来说,是倒排索引。
为什么叫倒排索引?
在没有搜索引擎时,我们是直接输入一个网址,然后获取网站内容,这时我们的行为是:document -> to -> words 。 通过文章,获取里面的单词,此谓「正向索引」,forward index。 后来,我们希望能够输入一个单词,找到含有这个单词、或者和这个单词有关系的文章:word -> to -> documents 于是我们把这种索引,称为 inverted index,直译过来,应该叫「反向索引」,国内翻译成「倒排索引」。
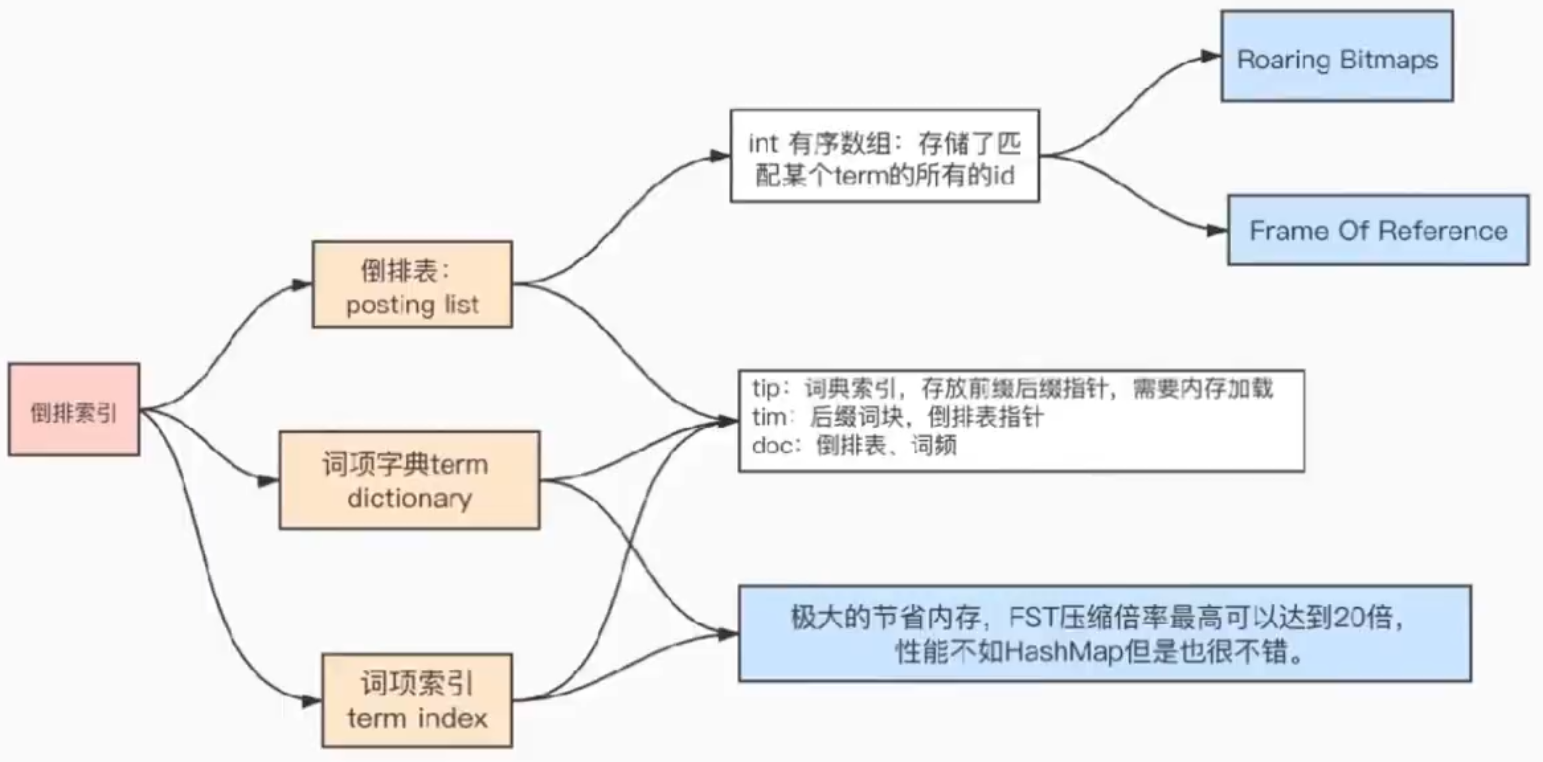
6.7、倒到排索的压缩算法
6.8、什么是字段树:trie
6.9、FST的构建原理
6.10、FST的构建过程和源码解析
视频
ES面试必问:Elasticsearch是什么? https://www.bilibili.com/video/BV1714y1c7Gh/?vd_source=14e623b3280938e774caf714015caa22
参考资料
ES面试必问:Elasticsearch是什么? https://www.bilibili.com/video/BV1714y1c7Gh
如何系统学习ElasticSearch、Kibana、Logstash (博主博客列表有好多可阅读的ElasticSearch相关内容) https://blog.csdn.net/qq_36095679/article/details/103144985
Elasticsearch 索引、修改、删除文档 https://zhuanlan.zhihu.com/p/378416938