正文
Lucene['lusen]最初是由Doug Cutting开发的,早先发布在作者自己的博客上,他贡献出Lucene的目标是为各种中小型应用程式加入全文检索功能。
后来发布在SourceForge的网站上提供下载。在2001年9月作为高质量的开源Java产品加入到Apache软件基金会的 Jakarta家族中。
随着每个版本的发布,这个项目得到明显的增强,也吸引了更多的用户和开发人员。
Lucene是apache软件基金会4 jakarta项目组的一个子项目,是一个开放源代码的全文检索引擎工具包,但它不是一个完整的全文检索引擎, 而是一个全文检索引擎的架构,提供了完整的查询引擎和索引引擎,部分文本分析引擎(英文与德文两种西方语言)。 Lucene的目的是为软件开发人员提供一个简单易用的工具包,以方便的在目标系统中实现全文检索的功能,或者是以此为基础建立起完整的全文检索引擎。 Lucene是一套用于全文检索和搜寻的开源程式库,由Apache软件基金会支持和提供。Lucene提供了一个简单却强大的应用程式接口,能够做全文索引和搜寻。 在Java开发环境里Lucene是一个成熟的免费开源工具。就其本身而言,Lucene是当前以及最近几年最受欢迎的免费Java信息检索程序库。 人们经常提到信息检索程序库,虽然与搜索引擎有关,但不应该将信息检索程序库与搜索引擎相混淆。
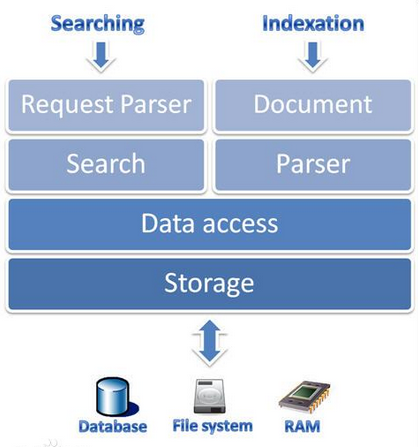
Lucene作为一个全文检索引擎,其具有如下突出的特点:
-
索引文件格式独立于应用平台。Lucene定义了一套以8位字节为基础的索引文件格式,使得兼容系统或者不同平台的应用能够共享建立的索引文件。
-
在传统全文检索引擎的倒排索引的基础上,实现了分块索引,能够针对新的文件建立小文件索引,提升索引速度。然后通过与原有索引的合并,达到优化的目的。
-
优秀的面向对象的系统架构,使得对于Lucene扩展的学习难度降低,方便扩充新功能。
-
设计了独立于语言和文件格式的文本分析接口,索引器通过接受Token流完成索引文件的创立,用户扩展新的语言和文件格式,只需要实现文本分析的接口。
-
已经默认实现了一套强大的查询引擎,用户无需自己编写代码即可使系统可获得强大的查询能力, Lucene的查询实现中默认实现了布尔操作、模糊查询(Fuzzy Search)、分组查询等等。
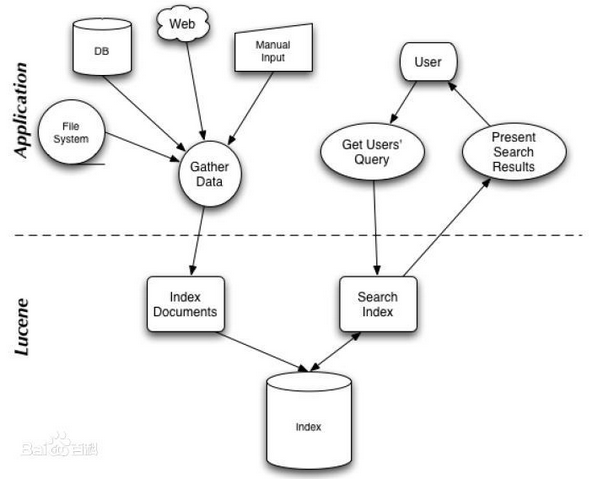
面对已经存在的商业全文检索引擎,Lucene也具有相当的优势:
-
它的开发源代码发行方式
-
Lucene秉承了开放源代码一贯的架构优良的优势,设计了一个合理而极具扩充能力的面向对象架构
-
转移到apache软件基金会后,借助于apache软件基金会的网络平台,程序员可以方便的和开发者、其它程序员交流,促成资源的共享,甚至直接获得已经编写完备的扩充功能
Lucene基本原理
Lucene 采用了基于倒排表的设计原理,可以非常高效地实现文本查找,在底层采用了分段的存储模式,使它在读写时几乎完全避免了锁的出现,大大提升了读写性能。
核心模块
Lucene 的写流程和读流程:
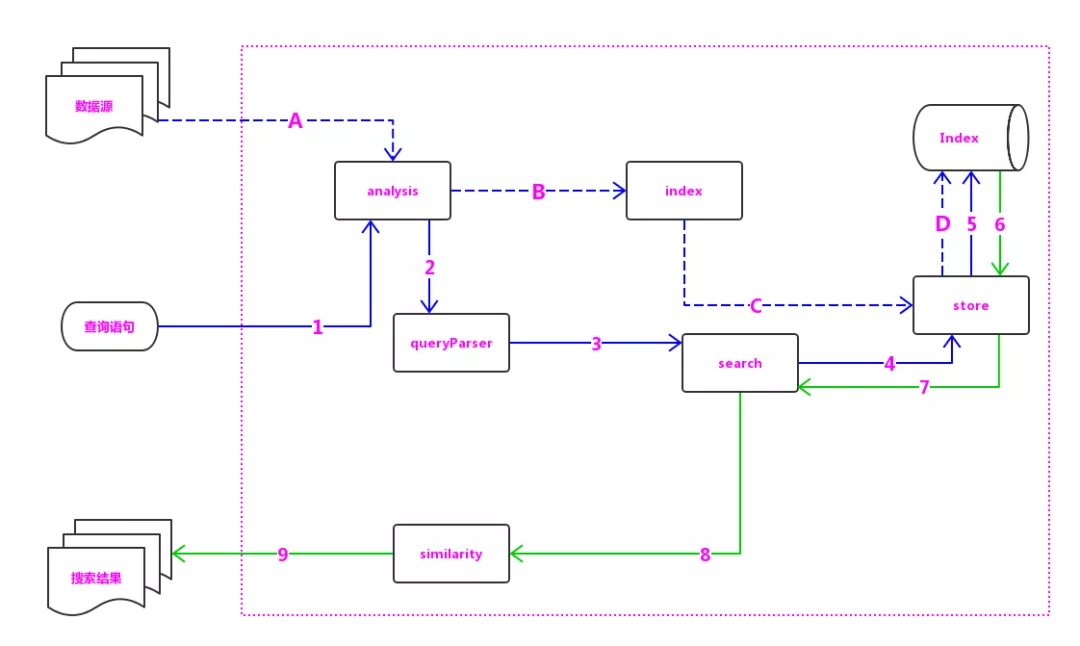
其中,虚线箭头(a、b、c、d)表示写索引的主要过程,实线箭头(1-9)表示查询的主要过程。
Lucene 中的主要模块及模块说明如下:
analysis:主要负责词法分析及语言处理,也就是我们常说的分词,通过该模块可最终形成存储或者搜索的最小单元 Term。
index 模块:主要负责索引的创建工作。
store 模块:主要负责索引的读写,主要是对文件的一些操作,其主要目的是抽象出和平台文件系统无关的存储。
queryParser 模块:主要负责语法分析,把我们的查询语句生成 Lucene 底层可以识别的条件。
search 模块:主要负责对索引的搜索工作。
similarity 模块:主要负责相关性打分和排序的实现。
核心术语
Term:是索引里最小的存储和查询单元,对于英文来说一般是指一个单词,对于中文来说一般是指一个分词后的词。
词典(Term Dictionary,也叫作字典):是 Term 的集合。词典的数据结构可以有很多种,每种都有自己的优缺点。
比如,排序数组通过二分查找来检索数据:HashMap(哈希表)比排序数组的检索速度更快,但是会浪费存储空间。
FST(finite-state transducer)有更高的数据压缩率和查询效率,因为词典是常驻内存的,而 FST 有很好的压缩率, 所以 FST 在 Lucene 的最新版本中有非常多的使用场景,也是默认的词典数据结构。
倒排序(Posting List):一篇文章通常由多个词组成,倒排表记录的是某个词在哪些文章中出现过。
正向信息:原始的文档信息,可以用来做排序、聚合、展示等。
段(Segment):索引中最小的独立存储单元。一个索引文件由一个或者多个段组成。在 Luence 中的段有不变性, 也就是说段一旦生成,在其上只能有读操作,不能有写操作。
倒排索引
反向索引又叫倒排索引,是根据文章内容中的关键字建立索引。
搜索引擎原理就是建立反向索引。
Elasticsearch 在 Lucene 的基础上进行封装,实现了分布式搜索引擎。
Elasticsearch 中的索引、类型和文档的概念比较重要,类似于 MySQL 中的数据库、表和行。
Elasticsearch 也是 Master-slave 架构,也实现了数据的分片和备份。
Elasticsearch 一个典型应用就是 ELK 日志分析系统。
ElasticSearch
Lucene是一个库,必须要懂一点搜索引擎原理的人才能用的好,所以后来又有人基于 Lucene 进行封装,写出了 Elasticsearch。
MySQL 索引
下面看一下MySQL InnoDB 引擎 索引实现的算法。
假设由我们自己来设计 MySQL 的索引,大概会有哪些选择呢?
-
散列表
-
有序数组
-
平衡二叉树
-
跳表
-
B+ 树
Lucene查询语法
Lucene查询语法以可读的方式书写,然后使用JavaCC进行词法转换,转换成机器可识别的查询。
-
Terms词语查询
-
Field字段查询
-
Term Modifier修饰符查询
WildCard Searches通配符查询
支持在单个单词或者语句中添加通配符:
?匹配单个字符
*匹配0个或多个字符
- Fuzzy Searches模糊词查询
支持搜索模糊词,如果想要搜索模糊词,需要在词语后面加上符号~
Proximity Searches邻近词查询
- Range Searches范围查询
支持范围搜索,可以指定最小值和最大值,会自动查找在这之间的文档。如果是单词,则会按照字典顺序搜索。
{}尖括号表示不包含最小值和最大值,可以单独使用
[]方括号表示包含最小值和最大值,可以单独使用
- Boosting a Term词语相关度查询
如果单词的匹配度很高,一个文档中或者一个字段中可以匹配多次,那么可以提升该词的相关度。使用符号^提高相关度。
- Boolean Operator布尔操作符
AND &&
OR ||
NOT && !
+
-
- Grouping分组
()
- Escaping Special Character转义字符
\
参考资料
Lucene知乎 https://www.zhihu.com/topic/19584038/top-answers
Lucene百度 https://baike.baidu.com/item/Lucene/6753302?fr=aladdin
终于有人把Elasticsearch原理讲透了 https://zhuanlan.zhihu.com/p/62892586
掌握它才说明你真正懂Elasticsearch https://zhuanlan.zhihu.com/p/65075215
Elasticsearch查询速度为什么这么快 https://zhuanlan.zhihu.com/p/280676094
Elasticsearch详解 https://www.jianshu.com/p/28fb017be7a7
图解 ElasticSearch 原理 https://zhuanlan.zhihu.com/p/339365195
Lucene查询语法详解 https://www.cnblogs.com/xing901022/p/4974977.html
数据结构与算法 https://www.cnblogs.com/xkzhangsanx/p/10888179.html
掌握它才说明你真正懂Elasticsearch https://zhuanlan.zhihu.com/p/65075215