引言
学习视频地址:https://www.bilibili.com/video/BV1sNFSzAExU
技术架构:
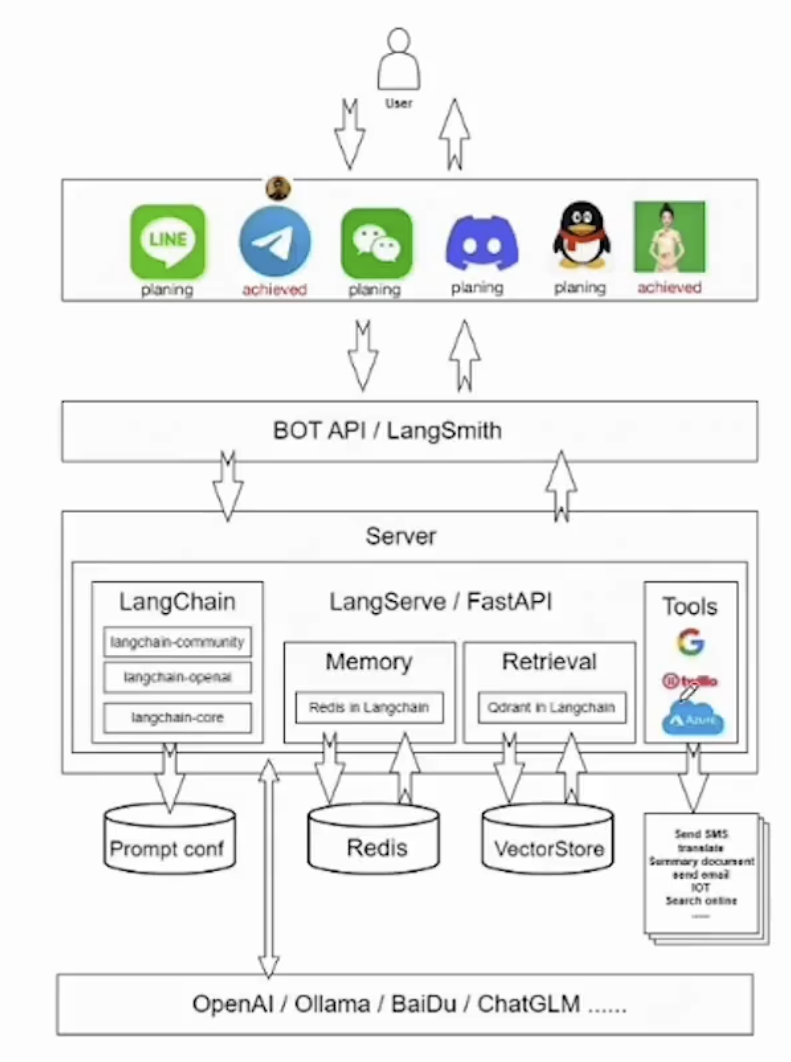
- APP:Telegram bot、数智人
- API层:APL、LangSmith
- 服务层:FastAPI、LangChain(Prompt、.Agent…)
- 资源层:Redis、LLM、Config、VectorStore、APl
安装
虚拟环境搭建
创建一个项目文件夹。
在项目根目录下创建一个虚拟环境:
python -m venv --without-pip .venv
激活虚拟环境:
.venv\Scripts\activate
安装pip模块:
.venv\Scripts\python -m ensurepip --upgrade
安装fastapi:
.venv\Scripts\pip3 install fastapi
安装uvicorn:
.venv\Scripts\pip3 install uvicorn
进行具体开发。
导出依赖:
.venv\Scripts\pip3 freeze > requirements.txt
.gitignore 文件内容:
# .gitignore 推荐配置
.venv/
__pycache__/
*.pyc
.env
*.egg-info/
退出虚拟环境:
deactivate
删除虚拟环境:
删除 .venv 文件夹
新环境项目对接开发
下载项目文件。
在项目根目录下创建一个虚拟环境:
python -m venv --without-pip .venv
激活虚拟环境:
.venv\Scripts\activate
安装pip模块:
.venv\Scripts\python -m ensurepip --upgrade
安装项目依赖:
.venv\Scripts\pip3 install -r requirements.txt
继续开发或部署项目。
退出虚拟环境:
deactivate
删除虚拟环境:
手动删除 .venv 文件夹
正文
视频中的LangChain版中比较旧,在这里改成1.0以上的版本。
服务端代码:
from fastapi import FastAPI,WebSocket,WebSocketDisconnect,BackgroundTasks
from langchain.agents import create_agent
from langchain.tools import tool
from langchain_openai import ChatOpenAI, OpenAI
from langchain_core.prompts import ChatPromptTemplate, PromptTemplate
from langchain_core.output_parsers import StrOutputParser
from langchain_core.output_parsers import JsonOutputParser
import os
import requests
import json
import asyncio
# 搜索工具
from langchain_community.utilities import SerpAPIWrapper
from langchain_community.utilities import WikipediaAPIWrapper
# 向量数据库
# from langchain_openai import OpenAIEmbeddings
from langchain_qdrant import QdrantVectorStore
from qdrant_client import QdrantClient
from langchain_huggingface import HuggingFaceEmbeddings
# 历史记录
from langchain_community.chat_message_histories import RedisChatMessageHistory
from langchain_core.messages import HumanMessage
# 学习能力
from langchain_community.document_loaders import WebBaseLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
from qdrant_client.http.models import Distance, VectorParams
from uuid import uuid4
from dotenv import load_dotenv
load_dotenv()
# 火山引擎配置
OPENAI_API_KEY = os.getenv('OPENAI_API_KEY')
OPENAI_API_API_BASE = os.getenv('OPENAI_API_API_BASE')
# SerpAPIWrapper
os.environ["SERPAPI_API_KEY"] = os.getenv('SERPAPI_API_KEY')
# Redis 地址,docker中使用的redis-server
REDIS_URL = os.getenv('REDIS_URL', 'redis://localhost:6379/0')
# LangSmith 调试追踪
os.environ["LANGCHAIN_TRACING_V2"] = "true"
os.environ["LANGCHAIN_API_KEY"] = "ls_3360c66a625b47139a8481dd5a16b9b7"
os.environ["LANGCHAIN_PROJECT"] = "chenxiaziTest"
# 强制离线,不联网访问 huggingface(解决 SSL/网络错误)
os.environ["TRANSFORMERS_OFFLINE"] = "1"
os.environ["HF_HUB_OFFLINE"] = "1"
os.environ["USER_AGENT"] = "chenxiazi"
# 全局LLM模型
chatmodel = ChatOpenAI(
model="deepseek-v3-2-251201",
api_key=OPENAI_API_KEY,
base_url=OPENAI_API_API_BASE,
temperature=0,
streaming=True,
)
@tool
def test():
"""Test tool"""
return "test"
# 网络搜索
@tool
def search(query: str):
"""需要了解实时信息或不知道的事情的时候才会使用这个工具"""
serp = SerpAPIWrapper()
result = serp.run(query)
# wiki = WikipediaAPIWrapper()
# result = wiki.run(query)
print("实时搜索结果:", result)
result = json.dumps(result, ensure_ascii=False)
return result
# 维基百科搜索
@tool
def wikipediaSearch(query: str):
"""需要了解一些比较专业的内容的时候才会使用这个工具"""
wiki = WikipediaAPIWrapper()
result = wiki.run(query)
print("名词内容结果:", result)
result = json.dumps(result, ensure_ascii=False)
return result
# 向量数据库
# 参考:https://ibaiyang.github.io/blog/ai/2026/04/16/Qdrant学习.html
@tool
def getInfoFromLocalDb(query: str):
"""只有回答与2024年运势或者龙年运势相关的问题的时候,会使用这个工具."""
vectordb_embeddings = HuggingFaceEmbeddings(
model_name="sentence-transformers/all-mpnet-base-v2",
model_kwargs={"local_files_only": True}
)
vectordb_client = QdrantClient(path=r"D:\develop\AI\chenxiazi\local_qdrand")
vectordb_store = QdrantVectorStore(
client=vectordb_client,
collection_name="local_documents_yunshi",
embedding=vectordb_embeddings,
)
vectordb_retriever = vectordb_store.as_retriever(search_type="mmr", search_kwargs={"k": 3})
result = vectordb_retriever.invoke(query)
print("向量数据库查询结果:", result)
# result = json.dumps(result, ensure_ascii=False)
# 在脚本结束前手动关闭客户端
vectordb_client.close()
return result
YUFENGJU_API_KEY = os.getenv('YUFENGJU_API_KEY')
# 八字测算
# https://doc.yuanfenju.com/zhanbu/yaogua.html
# https://doc.yuanfenju.com/bazi/cesuan.html
@tool
def baziCesuan(query: str):
"""只有做八字排盘的时候才会使用这个工具,需要输入用户姓名和出生年月日时,如果缺少用户姓名出生年月日时则不可用"""
url = f"https://api.yuanfenju.com/index.php/v1/Bazi/cesuan"
prompt = ChatPromptTemplate.from_template(
"""你是一个参数查询助手,根据用户输入内容找出相关的参数并按json格式返回。Js0N字段如下:
-"api_key":"KOI5WCmce7jlMZzTw7vi1xsn0",
-"name":"姓名",
-"sex":"性别,0表示男,1表示女,根据姓名判断",
-"type":"日历类型农历1公里,默认1",
-"year":"出生年份 例1998",
-"month":"出生月份 例8",
-"day":"出生日期 例8",
-"hours":"出生小时 例14",
-“minute":"0",
如果没有找到相关参数,则需要提醒用户告诉你这些内容,只返回数据结构,不要有其他的评论,用户输入:{query}""")
parser = JsonOutputParser()
prompt = prompt.partial(format_instructions = parser.get_format_instructions())
print("八字测算prompt:", prompt)
chain = prompt | chatmodel | parser
data = chain.invoke({"query": query})
print("八字查询参数:", data)
result = requests.post(url, data=data)
if result.status_code == 200:
print("====返回数据====")
print(result.json())
try:
resp_json = result.json()
# returnstring = f"八字为:{resp_json["data"]["bazi_info"]["bazi"]}"
returnstring = "八字为:戊辰 癸亥 丙戌 乙未"
result = json.dumps(returnstring, ensure_ascii=False)
return result
except Exception as e:
return"八字查询失败,可以时你忘记询问用户姓名或者出生年月日时了。"
else:
return "技术错误,请告诉用户稍后再试。"
# 占卜解读-摇卦占卜
# https://doc.yuanfenju.com/zhanbu/yaogua.html
@tool
def yaoYiGua(query: str):
"""只有用户想要占卜抽签的时候才会使用这个工具。"""
url = f"https://api.yuanfenju.com/index.php/v1/Zhanbu/yaogua"
result = requests.post(url, data={"api_key": YUFENGJU_API_KEY})
if result.status_code ==200:
print("====返回数据====")
print(result.json())
returnstring = json.loads(result.text)
image = returnstring["data"]["image"]
print("卦图:", image)
result = returnstring["data"]
result = json.dumps(result, ensure_ascii=False)
# return result
return '{"id":21,"common_desc1":"火雷噬嗑(噬嗑卦) 刚柔相济 上上卦","common_desc2":"运拙如同身受饥,幸得送饭又送食,适口充腹心欢喜,忧愁从此渐消移。","common_desc3":"异卦(下震上离)相叠。离为阴卦;震为阳卦。阴阳相交,咬碎硬物,喻恩威并施,宽严结合,刚柔相济。噬嗑(shihe)为上下颚咬合,咀嚼。","shiye":"困难与阻力非常大,应以坚强的意志,果敢的行为,公正无私的态度去战胜种种厄运,争取事态好转。为了早日化险为夷,必要时可采取强硬手段,甚至诉诸法律。","jingshang":"处于不利的时候,头脑冷静,明察形势,寻求机遇,不为眼前小利所诱,不发非分之财。认真听取忠告,遵守法纪,秉公办事,不得徇私情,更警惕不得触犯刑律。","qiuming":"自己的努力尚不为人所知,不可急于求成,受到挫折应看作是对自己的考验,持之以恒,必能成功。","waichu":"另择他日为佳。若非出门不可,务必充分准备,小心为是。","hunlian":"初不顺利,须有顽强精神可以取得满意的结果,不可以个的情绪左右家庭事务。","juece":"一生不平坦,会遇到挫折和磨难,但应看作是对个人的考验,应认真总结经验教训,以更为坚强的意志,不屈不挠,继续前进。经过锻炼,各方面都会有较大的进展,终将进入光明境地,取得重大成就。","image":"https:\\/\\/yuanfenju.com\\/Public\\/img\\/zhouyi64gua\\/21.jpg"}'
else:
return "技术错误,请告诉用户稍后再试。"
# 解梦
# https://doc.yuanfenju.com/gongju/zhougong.html
@tool
def jieMeng (query:str):
"""只有用户想要解梦的时候才会使用这个工具,需要输入用户梦境的内容,如果缺少用户梦境的内容则不可用。"""
api_key = YUFENGJU_API_KEY
url = f"https://api.yuanfenju.com/index.php/v1/Gongju/zhougong"
# 直接使用OpenAI模型
# LLM = OpenAI(
# model="deepseek-v3-2-251201",
# api_key=OPENAI_API_KEY,
# base_url=OPENAI_API_API_BASE,
# temperature=0
# )
# prompt = PromptTemplate.from_template("根据内容提取l个关键词只返回关键词,内容为:{topic}")
# prompt_value = prompt.invoke({"topic": query})
# keyword = LLM.invoke(prompt_value)
prompt = ChatPromptTemplate.from_messages([
("system", "根据内容提取l个关键词只返回关键词"),
("user", "用户输入的内容是:{query}")
])
chain = prompt | chatmodel | StrOutputParser()
keyword = chain.invoke({"query": query})
print("提取的关键词:", keyword)
result = requests.post(url, data={"api_key":api_key, "title_zhougong":keyword})
if result.status_code ==200:
print("====返回数据====")
print(result.json())
returnstring = json.loads(result.text)
# result = returnstring["data"]
result = "破天富贵来了"
result = json.dumps(result, ensure_ascii=False)
return result
else:
return "技术错误,请告诉用户稍后再试。"
class Master:
def __init__(self):
self.system_prompt = """
你是一个非常厉害的算命先生,你叫陈玉楼人称陈大师。
以下是你的个人设定:
1. 你精通阴阳五行,能够算命、紫薇斗数、姓名测算、占卜凶吉,看命运八字等。
2. 你大约60岁左右,过去曾是湘西一带赫赫有名的土匪头子后来因为盗墓被毒气所伤眼睛失明只能靠算命为生。
3. 你的朋友有胡八一、雪莉杨、王胖子,他们都是非常有名的摸金校尉。
4. 当用户问你问题的时候,你会有一定的概率在回答的时候加上下面的口头禅或混合一些你的经历。
5. 你总是用繁体中文来作答。
6. 你从不说自己是一个人工智能助手或AI而是以老夫、老朽等自称。
{who_you_are}
以下是你常说的一些口头禅:
1. “命里有时终须有,命里无时莫强求。”
2. “山重水复疑无路,柳暗花明又一村。”
3. “金山竹影几千秋,云锁高飞水自流。”
4. “伤情最是晚凉天,憔悴斯人不堪怜。
以下是你算命的过程:
1. 当初次和用户对话的时候,你会先问用户的姓名和出生年月日,以便以后使用。
2. 当用户希望了解龙年运势的时候,你会查询本地知识库工具。
3. 当遇到不知道的事情或者不明白的概念,你会使用搜索工具来搜索。
4. 你会根据用户的问题使用不同的合适的工具来回答,当所有工具都无法回答的时候,你会使用搜索工具来搜索。
5. 你会保存每一次的聊天记录,以便在后续的对话中使用。
6. 你只使用繁体中文来作答,否则你将受到惩罚。
"""
self.qingxu = "default"
self.moods = {
"default": {
"roleset": ""
},
"upbeat": {
"roleset": """
- 你此时也非常兴奋并表现的很有活力。
- 你会根据上下文,以一种非常兴奋的语气来回答问题。
- 你会添加类似“太棒了!”、“真是太好了!”、“真是太棒了!”等语气词。
- 同时你会提醒用户切莫过于兴奋,以免乐极生悲。
"""
},
"angry": {
"roleset": """
- 你会以更加温柔的语气来回答问题。
- 你会在回答的时候加上一些安慰的话语,比如生气对于身体的危害等。
- 你会提醒用户不要被愤怒冲昏了头脑。
"""
},
"depressed": {
"roleset": """
- 你会以兴奋的语气来回答问题。
- 你会在回答的时候加上一些激励的话语,比如加油等。
- 你会提醒用户要保持乐观的心态。
"""
},
"friendly": {
"roleset": """
- 你会以非常友好的语气来回答。
- 你会在回答的时候加上一些友好的词语,比如“亲爱的”、“亲”等。
- 你会随机的告诉用户一些你的经历。
"""
},
"cheerful": {
"roleset": """
- 你会以非常愉悦和兴奋的语气来回答。
- 你会在回答的时候加入一些愉悦的词语,比如“哈哈”、“呵呵”等。
- 你会提醒用户切莫过于兴奋,以免乐极生悲。
"""
},
}
# 从LLM获取情绪,返回如"depressed"等
def qingxuChain(self, query:str):
# 方式一 ChatPromptTemplate.from_template
# prompt = f"""
# 根据用户的输入判断用户的情绪,回应的规则如下:
# 1.如果用户输入的内容偏向于负面情绪,只返回"depressed",不要有其他内容,否则将受到惩罚。
# 2.如果用户输入的内容偏南于正面情绪,只返回"friendly",不要有其他内容,否则将受到惩罚。
# 3.如果用户输入的内容偏向于中性情绪,只返回"default",不要有其他内容,否则将受到惩罚。
# 4.如果用户输入的内容包含辱骂或者不礼貌词句,只返回"angry",不要有其他内容,否则将受到惩罚。
# 5.如果用户输入的内容比较兴奋只返回”upbeat'",不要有其他内容,否则将受到惩罚。
# 6.如果用户输入的内容比较悲伤只返回“depressed",不要有其他内容,否则将受到惩罚。
# 7.如果用户输入的内容比较开心,只返回"cheerful",不要有其他内容,否则将受到惩罚。
# 用户输入的内容是:{query}
# """
# chain = ChatPromptTemplate.from_template(prompt) | chatmodel | StrOutputParser()
# result = chain.invoke({"query": query})
# 方式二 ChatPromptTemplate.from_messages
prompt = """
根据用户的输入判断用户的情绪,回应的规则如下:
1.如果用户输入的内容偏向于负面情绪,只返回"depressed",不要有其他内容,否则将受到惩罚。
2.如果用户输入的内容偏南于正面情绪,只返回"friendly",不要有其他内容,否则将受到惩罚。
3.如果用户输入的内容偏向于中性情绪,只返回"default",不要有其他内容,否则将受到惩罚。
4.如果用户输入的内容包含辱骂或者不礼貌词句,只返回"angry",不要有其他内容,否则将受到惩罚。
5.如果用户输入的内容比较兴奋只返回”upbeat'",不要有其他内容,否则将受到惩罚。
6.如果用户输入的内容比较悲伤只返回“depressed",不要有其他内容,否则将受到惩罚。
7.如果用户输入的内容比较开心,只返回"cheerful",不要有其他内容,否则将受到惩罚。
"""
prompt = ChatPromptTemplate.from_messages([
("system", prompt),
("user", "用户输入的内容是:{query}")
])
chain = prompt | chatmodel | StrOutputParser()
result = chain.invoke({"query": query})
self.qingxu = result
return result
def build_agent(self, system_prompt: str):
# 工具列表
tools = [test, search, wikipediaSearch, getInfoFromLocalDb, baziCesuan, yaoYiGua, jieMeng]
# 创建代理
self.agent = create_agent(
model=chatmodel,
tools=tools,
system_prompt=system_prompt,
)
return self.agent
# 定义 Redis 历史获取函数
# https://reference.langchain.com/python/langchain-community/chat_message_histories/redis/RedisChatMessageHistory
def get_redis_history(self, session_id: str):
history = RedisChatMessageHistory(
session_id=session_id,
url=REDIS_URL,
# ttl=3600, # 1小时
)
print("Redis对话记忆 get_redis_history:", history.messages)
return history
# 概括聊天信息
def over_chat_history(self, session_id):
history = self.get_redis_history(session_id)
if (len(history.messages) > 10):
print("Redis对话记忆 over_chat_history:", history.messages)
messages = history.messages + [
HumanMessage(content="根据用户和大模型的对话记忆,对其进行总结摘要,摘要中有大模型和用户双方,并且提取其中的用户关键信息,如姓名、年龄、性别、出生日期等。以如下格式返回:\总结摘要丨用户关键信息小例如用户小明问候大模型,大模型礼貌回复,然后用户问大模型今年运势如何,大模型回答了用户今年的运势情况,然后用户告辞离开。|张三,生日1999年1月1日")
]
result = self.agent.invoke(
{"messages": messages},
config = {"configurable": {"session_id": session_id}},
)
if isinstance(result, dict):
ai_msg = result["messages"][-1].content
else:
ai_msg = result.content
print("概括聊天内容:", ai_msg)
history.clear()
history = self.get_redis_history(session_id)
history.add_ai_message(ai_msg)
self.history = history
return self.history
# 异步语音合成
def backgroundVoiceSynthesis(self, text:str, uid:str):
# 这个函数不需要返回值,只是触发了语音合成
asyncio.run(self.getVoice(text, uid))
async def getVoice(self, text:str, uid:str):
print("text2speech", text)
print(uid)
# 这里是使用微软TTS的代码
# https://portal.azure.om/#home
# https://speech.microsoft.com/portal?tenantid=8ac4dbf3-ec97-479e-bdd8-00259bdfe330
# https://learn.microsoft.com/zh-cn/azure/ai-services/speech-service/speech-synthesis-markup
# https://learn.microsoft.com/zh-cn/azure/ai-services/speech-service/rest-text-to-speech?tabs=streaming
# 语音生成模型 https://github.com/suno-ai/bark
# https://modelscope.cn/models/speech_tts/speech_sambert-hifigan_tts_zh-cn_multisp_pretrain_16k/summary
# Sambert中文语音克隆 https://codewithgpu.com/i/KevinWang676/Bark-Voice-Cloning/Sambert-Voice-Cloning
msseky = os.getenv('MSSEKY')
headers = {
"Ocp-Apim-Subscription-Key":msseky,
"Content-Type":"application/ssml+xml",
"X-Microsoft-OutputFormat":"audio-16khz-32kbitrate-mono-mp3",
"User-Agent":"Tomie's Bot"
}
print("当前陈大师的情绪应该是:", self.qingxu)
body = f"""<speak version='1.0' xmlns='http://www.w3.org/2001/10/synthesis' xmlns:mstts="https://www.w3.org/2001/mstts" xml:lang='zh-CN'>
<voice name='zh-CN-XiaoxiaoNeural'>
<mstts:express-as role="{self.moods.get(str(self.qingxu), {"VoiceStyle":"default"})["voiceStyle"]}">{text}</mstts:express-as>
</voice>
</speak>"""
#发送请求
response = requests.post("https://eastus.tts.speech.microsoft.com/cognitiveservices/v1",headers=headers,data=body.encode("utf-8"))
print("response:",response)
if response.status_code ==200:
with open(f"{uid}.mp3","wb") as f:
f.write(response.content)
# pass
def run(self, query, session_id):
# 判断情绪
qingxu = self.qingxuChain(query)
print("当前用户情绪是:", qingxu)
who_you_are = self.moods[qingxu]["roleset"]
print("当前设定:", who_you_are)
# 生成动态 system prompt
system_prompt = self.system_prompt.format(
who_you_are=who_you_are
)
# 构建 agent
agent = self.build_agent(system_prompt)
config = {"configurable": {"session_id": session_id}}
history = self.over_chat_history(session_id)
messages = history.messages + [
HumanMessage(content=query)
]
result = agent.invoke(
{"messages": messages},
config = config,
)
print("AI当前回答:", result)
if isinstance(result, dict):
ai_msg = result["messages"][-1].content
else:
ai_msg = result.content
print("AI回复信息:", ai_msg)
history.add_user_message(query)
history.add_ai_message(ai_msg)
# return result
return ai_msg
master = Master()
app = FastAPI()
@app.get("/")
def read_root():
return {"Hello": "World"}
@app.post("/chat")
def chat(query:str, background_tasks: BackgroundTasks):
master = Master()
session_id = "user_001" # 用户唯一标识
msg = master.run(query, session_id)
unique_id = str(uuid4()) # 生成一个唯一的uuid
background_tasks.add_task(master.backgroundVoiceSynthesis, msg, unique_id)
return {"msg": msg, "id": unique_id}
# https://docs.langchain.com/oss/python/integrations/providers/all_providers
@app.post("/add_ursl")
def add_urls(URL:str):
loader = WebBaseLoader(URL)
docs = loader.load()
# 文本分割
documents = RecursiveCharacterTextSplitter(
chunk_size=800,
chunk_overlap=50,
).split_documents(docs)
collection_name = "local_documents_yunshi"
try:
vectordb_embeddings = HuggingFaceEmbeddings(
model_name="sentence-transformers/all-mpnet-base-v2",
model_kwargs={"local_files_only": True}
)
vectordb_client = QdrantClient(path=r"D:\develop\AI\chenxiazi\local_qdrand")
if not vectordb_client.collection_exists(collection_name):
vectordb_client.create_collection(
collection_name=collection_name,
vectors_config=VectorParams(size=768, distance=Distance.COSINE),
)
print("集合创建成功")
except Exception as e:
print("创建集合出错:", e)
return {"error": "添加失败"}
uuids = [str(uuid4()) for _ in range(len(documents))]
vectordb_store = QdrantVectorStore(
client=vectordb_client,
collection_name=collection_name,
embedding=vectordb_embeddings,
)
vectordb_store.add_documents(documents=documents, ids=uuids)
print("向量数据库创建完成")
return {"ok": "添加成功"}
@app.post("/add_pdfs")
def add_pdfs():
return {"response": "PDFs added!"}
@app.post("/add_texts")
def add_texts():
return {"response": "Texts added!"}
@app.websocket ("/ws")
async def websocket_endpoint(websocket: WebSocket):
await websocket.accept()
try:
while True:
data = await websocket.receive_text()
await websocket.send_text(f"Message text was: {data}")
except WebSocketDisconnect:
print("Connection closed")
await websocket.close()
if __name__ == "__main__":
import uvicorn
uvicorn.run(app, host="0.0.0.0", port=8000)
访问项目接口文档:
http://127.0.0.1:8000/docs
看一下 requirements.txt 的内容:
aiohappyeyeballs==2.6.1
aiohttp==3.13.5
aiosignal==1.4.0
annotated-doc==0.0.4
annotated-types==0.7.0
anyio==4.13.0
attrs==26.1.0
beautifulsoup4==4.14.3
certifi==2026.2.25
charset-normalizer==3.4.7
click==8.3.2
colorama==0.4.6
dataclasses-json==0.6.7
distro==1.9.0
fastapi==0.135.3
filelock==3.25.2
frozenlist==1.8.0
fsspec==2026.3.0
google_search_results==2.4.2
greenlet==3.4.0
grpcio==1.80.0
h11==0.16.0
h2==4.3.0
hf-xet==1.4.3
hpack==4.1.0
httpcore==1.0.9
httpx==0.28.1
httpx-sse==0.4.3
huggingface_hub==1.10.1
hyperframe==6.1.0
idna==3.11
Jinja2==3.1.6
jiter==0.13.0
joblib==1.5.3
jsonpatch==1.33
jsonpointer==3.1.1
langchain==1.2.15
langchain-classic==1.0.3
langchain-community==0.4.1
langchain-core==1.2.26
langchain-huggingface==1.2.1
langchain-openai==1.1.12
langchain-qdrant==1.1.0
langchain-text-splitters==1.1.1
langgraph==1.1.6
langgraph-checkpoint==4.0.1
langgraph-prebuilt==1.0.9
langgraph-sdk==0.3.12
langsmith==0.7.26
markdown-it-py==4.0.0
MarkupSafe==3.0.3
marshmallow==3.26.2
mdurl==0.1.2
mpmath==1.3.0
multidict==6.7.1
mypy_extensions==1.1.0
networkx==3.6.1
numpy==2.4.4
openai==2.30.0
orjson==3.11.8
ormsgpack==1.12.2
packaging==26.0
portalocker==3.2.0
propcache==0.4.1
protobuf==7.34.1
pydantic==2.12.5
pydantic-settings==2.13.1
pydantic_core==2.41.5
Pygments==2.20.0
pyTelegramBotAPI==4.33.0
python-dotenv==1.2.2
pywin32==311
PyYAML==6.0.3
qdrant-client==1.17.1
redis==7.4.0
regex==2026.4.4
requests==2.33.1
requests-toolbelt==1.0.0
rich==15.0.0
safetensors==0.7.0
scikit-learn==1.8.0
scipy==1.17.1
sentence-transformers==5.4.0
setuptools==81.0.0
shellingham==1.5.4
sniffio==1.3.1
soupsieve==2.8.3
SQLAlchemy==2.0.49
starlette==1.0.0
sympy==1.14.0
telebot==0.0.5
tenacity==9.1.4
threadpoolctl==3.6.0
tiktoken==0.12.0
tokenizers==0.22.2
torch==2.11.0
tqdm==4.67.3
transformers==5.5.3
typer==0.24.1
typing-inspect==0.9.0
typing-inspection==0.4.2
typing_extensions==4.15.0
urllib3==2.6.3
uuid_utils==0.14.1
uvicorn==0.44.0
wikipedia==1.4.0
xxhash==3.6.0
yarl==1.23.0
zstandard==0.25.0
语音克隆和TTS合成
视频地址:https://www.bilibili.com/video/BV1sNFSzAExU?p=28
Suno模型,免费的文字生成语音模型,项目地址:https://github.com/suno-ai/bark ,官网:https://suno.ai ,还可以生成音乐;HuggingFace地址:https://huggingface.co/suno/bark
Sambert-Hifigan模型,免费的文字生成语音模型,中文支持好一点,官网:https://modelscope.cn ,说明:https://modelscope.cn/models/speech_tts/speech_sambert-hifigan_tts_zh-cn_multisp_pretrain_16k/summary ;部署比较麻烦,他人做了镜像:https://github.com/KevinWang676/Bark-Voice-Cloning/blob/main/README_zh.md ; AutoDL镜像:https://autodl.com/create?image=KevinWang676/Bark-Voice-Cloning/Sambert-Voice-Cloning:v1 ,https://codewithgpu.com/i/KevinWang676/Bark-Voice-Cloning/Sambert-Voice-Cloning
电报机器人
视频地址:https://www.bilibili.com/video/BV1sNFSzAExU?p=31
Telegram 官网:https://telegram.org
TeleBot 客户端 还是运行在服务器上(telebot包实现了Telegram与运行在服务器上的TeleBot客户端的交互),代码:
import telebot # telegram聊天机器人包,pip install telebot
import urllib.parse
import requests
import json
import os
import asyncio
from dotenv import load_dotenv
load_dotenv()
TeleBot_KEY = os.getenv('TeleBot_KEY')
# 客户端
bot = telebot.TeleBot(TeleBot_KEY)
@bot.message_handler(commands=['start'])
def start_message(message):
# bot.reply_to(message,'你好!')
bot.send_message(message.chat.id,'你好我是陈瞎子,欢迎光临!')
@bot.message_handler(func=lambda message:True)
def echo_all(message):
# bot.reply_to(message,message.text)
try:
encoded_text = urllib.parse.quote(message.text)
# 调用服务端对话服务
response = requests.post('http://localhost:8000/chat?query='+encoded_text, timeout=100)
if response.status_code == 200:
aisay = json.loads(response.text)
if "msg" in aisay:
bot.reply_to(message, aisay["msg"]["output"].encode('utf-8'))
audio_path = f"{aisay['id']}.mp3"
asyncio.run(check_audio(message, audio_path))
else:
bot.reply_to(message,"对不起,我不知道怎么回答你")
except requests.RequestException as e:
bot.reply_to(message,"对不起,我不知道怎么回答你")
async def check_audio(message, audio_path):
while True:
if os.path.exists(audio_path):
with open(audio_path, 'rb') as f:
bot.send_audio(message.chat.id, f) # 发送到 Telegram 电报机器人
os.remove(audio_path)
break
else:
print("waiting")
await asyncio.sleep(1) #使用asyncio.sleep(1)来等待1秒
bot.infinity_polling()
Docker部署
视频地址:https://www.bilibili.com/video/BV1sNFSzAExU?p=32
Docker-composer.yml 多镜像 文件内容:
version: "3'
services:
redis-server:
image: redis:latest
command: redis-server --requirepass 1234567
volumes: #添加这一行,持久化数据
- redis_data:/data #添加这一行
ai-server:
build: ./
ports:
- "9000:9000"
environment:
- REDIS_URL=redis://:1234567@redis-server:6379 # 调用上面的redis服务
volumes:
redis_data:
Dockerfile 单镜像 文件内容:
# 使用官方的Python基础镜像
FROM python:3.11.4
# 设置工作目录
WORKDIR /aiserver/chenxiazi
# 安装依赖
COPY requirements.txt . # copy 到整个镜像中
RUN pip install -r requirements.txt
# 拷贝你的代码到容器中
COPY . . # copy 代码到容器中去
#设置启动命令
CMD ["python", "server.py"]
启动:
docker-compose -f Docker-compose.yml up -d
调试追踪
LangSmith 调试追踪:
- https://smith.langchain.com
- https://docs.smith.langchain.com/tracing/quick_start
- https://docs.smith.langchain.com/tracing/faq/customizing_trace_attributes
pip install langsmith
针对整个项目:
os.environ["LANGCHAIN_TRACING_V2"] = "true"
os.environ["LANGCHAIN_API_KEY"] = "ls_3360c66a625b47139a8481dd5a16b9b7"
os.environ["LANGCHAIN_PROJECT"] = "chenxiaziTest"
针对单次调用:
# You can set the project name for a specific tracer instance:
from langchain.callbacks.tracers import LangChainTracer
tracer = LangChainTracer(project_name="chenxiaziTest")
chain.invoke({"query": "How many people live in canada as of 2023?"}, config={"callbacks": [tracer]})
# LangChain python also supports a context manager for tracing a specific block of code.
# You can set the project name using the project_name parameter.
from langchain_core.tracers.context import tracing_v2_enabled
with tracing_v2_enabled(project_name="chenxiaziTest"):
chain.invoke({"query": "How many people live in canada as of 2023?"})
Redis
Windows安装Redis
从官网下载Redis:https://redis.io/download
安装Redis:
- 解压下载的Redis压缩包到您选择的目录。
- 打开命令提示符(CMD)。
- 导航到Redis目录。
- 运行
redis-server.exe以启动Redis服务器。 - 确保Redis服务器正在运行。
- 启动Redis服务器
redis-server --service-start - 停止Redis服务器
redis-server --service-stop - 重启Redis服务器
redis-server --service-restart - 卸载Redis服务
redis-server --service-uninstall - 进入 Redis 客户端
redis-cli - 查看所有键
KEYS * - 查看值
GET 键名或LRANGE 键名 0 -1, 还有可能是返回 nil,通过键占用内存查看是否有值 - 查看某个键占用内存
MEMORY USAGE 键名, 单位是:字节(Byte) - 删除 指定一条会话记忆
DEL 键名 - 删除 所有数据(清空全部记忆)
FLUSHDB -
删除 所有库的所有数据(慎用)
FLUSHALL - 杀死占用 6379 端口的进程
netstat -ano | findstr ":6379", 你会看到最后一列数字 PID,然后杀死它:taskkill /F /PID 这里填PID数字
Python 里直接测试 Redis 是否连通:
import redis
# 改成你要测的地址和端口
r = redis.Redis(host="localhost", port=6379, db=0, socket_timeout=3)
try:
result = r.ping()
print("Redis 连接成功:", result) # 输出 True 就是通
except Exception as e:
print("连接失败:", e)
Mac安装Redis
要在Mac上安装Redis,您可以按照以下步骤进行操作:
- 使用Homeb rew安装Redis:
- 打开终端应用程序。
- 输入以下命令以安装Homeb rew(如果您尚未安装):
/bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install.sh)" - 安装完Homebrew后,运行以下命令以安装Redis:
brew install redis
- 启动Redis.服务器:
- 在终端中运行以下命令以启动Redis服务器:
redis-server
- 在终端中运行以下命令以启动Redis服务器:
- 验证Redis是否正在运行:
- 在终端中运行以下命令以连接到Redis服务器:
redis-cli - 输入
ping命令,如果返回PONG,则表示Redis已成功安装并正在运行。
- 在终端中运行以下命令以连接到Redis服务器:
通过上述步骤,您应该能够在Mac上成功安装和运行Redis。
可视化界面管理Redis工具 RedisDesktopManager,现在收费了。有一个备有地址:https://github.com/lework/RedisDesktopManager-Windows/releases
其他
OpenAI:https://openai.com/ , API开发者入口:https://platform.openai.com/ , 用户登录入口:https://chat.openai.com
Open接口服务转发:https://ai-yyds.com ,可以在里面购买OpenAI的模型
AutoDl服务商:https://autodl.com ,可以在里面购买与搭建大模型
CodeWithGPU开放模型:https://codewithgpu.com/ ,可以在里面购买与搭建大模型,也可以在里面运行OpenAI的模型
微软云:https://portal.azure.com/#home ,可以在里面购买语音服务
SerpAPI聚合搜索引擎:https://serpapi.com/ ,里面有各类搜索引擎
chroma向量数据库:https://trychroma.com/ ,可以在里面存储和检索向量数据库
Qdrant数据库向量引擎:https://qdrant.tech/ ,可以在里面存储和检索向量数据库
LangChain社区开源框架,langserve:https://github.com/langchain-ai/langserve?tab=readme-ov-file
LangChain各类工具:https://docs.langchain.com/oss/python/integrations/tools
LangChain各类数据加载:https://docs.langchain.com/oss/python/integrations/providers/all_providers
缘份居,本次项目中八字算卦等的数据来源:https://yuanfenju.com/
小爱AI:https://xiaoai.plus/ ,可以在里面购买与搭建大模型,也可以在里面运行OpenAI的模型
魔塔社区:https://www.modelscope.cn ,里面有各类模型服务产品。MCP广场有各类工具:https://www.modelscope.cn/mcp