分布式唯一 ID 特性
在业务开发中,会存在大量的场景都需要唯一 ID 来进行标识。比如,用户需要唯一身份标识;商品需要唯一标识;消息需要唯一标识; 事件需要唯一标识等等。尤其是在分布式场景下,业务会更加依赖唯一 ID。
分布式唯一 ID 的特性如下:
- 全局唯一:必须保证生成的 ID 是全局性唯一的,这是分布式 ID 的基本要求;
- 有序性:生成的 ID 需要按照某种规则有序,便于数据库的写入和排序操作;
- 可用性:需要保证高并发下的可用性。除了对 ID 号码自身的要求,业务还对 ID 生成系统的可用性要求极高;
- 自主性:分布式环境下不依赖中心认证即可自行生成 ID;
- 安全性:不暴露系统和业务的信息。在一些业务场景下,会需要 ID 无规则或者不规则。
常用分布式唯一 ID 生成方案
UUID
UUID(Universally Unique Identifier,即通用唯一标识码)算法的目的是生成某种形式的全局唯一 ID 来标识系统中的任一元素, 尤其是在分布式环境下,UUID 可以不依赖中心认证即可自动生成全局唯一 ID。
UUID 的标准形式为 32 个十六进制数组成的字符串,且分割为五个部分,例如:467e8542-2275-4163-95d6-7adc205580a9。
基于使用场景的不同,会存在以下几个不同版本的 UUID 以供使用,如下所示:
- 基于时间的 UUID:主要依赖当前的时间戳和机器 mac 地址。优势是能基本保证全球唯一性, 缺点是由于使用了 mac 地址,会暴露 mac 地址和生成时间;
- 分布式安全的 UUID:将基于时间的 UUID 算法中的时间戳前四位替换为 POSIX 的 UID 或 GID。 优势是能保证全球唯一性,缺点是很少使用,常用库基本没有实现;
- 基于随机数的 UUID:基于随机数或伪随机数生成。优势是实现简单,缺点是重复几率可计算;
- 基于名字空间的 UUID(MD5 版):基于指定的名字空间/名字生成 MD5 散列值得到。 优势是不同名字空间/名字下的 UUID 是唯一的,缺点是 MD5 碰撞问题,只用于向后兼容;
- 基于名字空间的 UUID(SHA1 版):将基于名字空间的 UUID(MD5 版)中的散列算法修改为 SHA1。 优势是不同名字空间/名字下的 UUID 是唯一的,缺点是 SHA1 计算相对耗时。
UUID 的优势是性能非常高,由于是本地生成,没有网络消耗。而其也存在一些缺陷,包括不易于存储,UUID 太长, 16 字节 128 位,通常以 36 长度的字符串表示;信息不安全,基于时间的 UUID 可能会造成机器的 mac 地址泄露; ID 作为 DB 主键时在特定的场景下会存在一些问题。UUID 的无序性可能会引起数据位置频繁变动,影响性能。
数据库自增 ID
数据库自增 ID 是最常见的一种生成 ID 方式。利用数据库本身来进行设置,在全数据库内保持唯一。 优势是使用简单,满足基本业务需求,天然有序;缺点是强依赖 DB,会由于数据库部署的一些特性而存在单点故障、数据一致性等问题。
如果分库分表了,当然不是简单地设置好 auto_increment_increment 和 auto_increment_offset 就行。
针对上面介绍的数据库自增 ID 的缺陷,会存在以下两种优化方案: 数据库水平拆分
设置不同的初始值和相同的步长。 比如有两台机器,设置步长 step 为 2。Server1 的初始值为 1(1, 3, 5, 7, 9, 11…),Server2 的初始值为 2(2, 4, 6, 8, 10…)。 这样可以有效的生成集群中的唯一 ID,也大大降低 ID 生成数据库操作的负载。
这种实现的缺陷:
- ID 没有了单调递增的特性,只能趋势递增。有些业务场景可能不符合;
- 数据库压力还是比较大,每次获取 ID 都需要读取数据库,只能通过多台机器提高稳定性和性能。
批量生成一批 ID
这样可以将数据库的压力减小到先前的 N 分之一,且数据库故障后仍可继续使用一段时间。此种方法详见下面的数据库号段模式介绍。
数据库自增 ID 方案的优势是非常简单,可利用现有数据库系统的功能实现;ID 号单调自增。 其缺陷包括强依赖 DB,当 DB 异常时整个系统将处于不可用的状态;ID 号的生成速率取决于所使用数据库的读写性能。
Redis 生成 ID
当使用数据库来生成 ID 性能不够的时候,可以尝试使用 Redis 来生成 ID。 主要使用 Redis 的 INCR 和 INCRBY 这样的自增原子命令来实现。 由于 Redis 单线程的特点,可以保证 ID 的唯一性和有序性。
优势是不依赖于数据库,使用灵活,性能也优于数据库; 而缺点则是可能要引入新的组件 Redis,如果 Redis 出现单点故障问题,则会影响序号服务的可用性。
这种实现方式,如果并发请求量上来后,就需要集群。不过集群后,又要和传统数据库一样,设置分段和步长。
- 优点:Redis 性能相对比较好,而且可以保证唯一性和有序性;
- 缺点:需要依赖 Redis 来实现,系统需要引入 Redis 组件。
Zookeeper 生成 ID
主要是利用 Zookeeper 的 znode 数据版本来生成序列号,可以生成 32 位和 64 位的数据版本号, 客户端可以使用这个版本号来作为唯一的序列号。 由于需要依赖 zookeeper,并且是多步调用 API,如果在竞争较大的情况下,可能需要考虑使用分布式锁, 故此种生成唯一 ID 的方法的性能在高并发的分布式环境下不甚理想。
Snowflake 算法
Snowflake(雪花算法)是一个开源的分布式 ID 生成算法,结果是一个 long 型的 ID。 Snowflake 算法将 64bit 划分为多段,分开来标识机器、时间等信息,具体组成结构如下图所示:

Snowflake 算法的核心思想是使用 41bit 作为毫秒数,10bit 作为机器的 ID(比如其中 5 个 bit 可作为数据中心, 5 个 bit 作为机器 ID),12bit 作为毫秒内的流水号(意味着每个节点在每毫秒可以产生 4096 个 ID), 最后还有一个符号位,永远是 0。
Snowflake 算法可以根据自身业务的需求进行一定的调整。比如估算未来的数据中心个数, 每个数据中心内的机器数,以及统一毫秒内的并发数来调整在算法中所需要的 bit 数。
- 优势:稳定性高,不依赖于数据库等第三方系统; 使用灵活方便,可以根据业务需求的特性来调整算法中的 bit 位; 单机上 ID 单调自增,毫秒数在高位,自增序列在低位,整个 ID 是趋势递增的。
- 缺陷:包括强依赖机器时钟,如果机器上时钟回拨,会导致发号重复或者服务处于不可用状态; ID 可能不是全局递增,虽然 ID 在单机上是递增的,但是由于涉及到分布式环境下的每个机器节点上的时钟, 可能会出现不是全局递增的场景。
PHP代码实现可以参考 https://ibaiyang.github.io/blog/php/2019/02/27/雪花ID相关.html
数据库号段模式
号段模式介绍
号段模式是当下分布式 ID 生成器的主流实现方式之一,号段模式可以理解成从数据库批量获取 ID,然后将 ID 缓存在本地, 以此来提高业务获取 ID 的效率。例如,每次从数据库获取 ID 时,获取一个号段,如(1,1000], 这个范围表示 1000 个 ID,业务应用在请求获取 ID 时,只需要在本地从 1 开始自增并返回, 而不用每次去请求数据库,一直到本地自增到 1000 时,才去数据库重新获取新的号段,后续流程循环往复。
建表结构如下:
CREATE TABLE id_generator (
id int(10) NOT NULL,
max_id bigint(20) NOT NULL COMMENT '当前最大id',
step int(20) NOT NULL COMMENT '号段的步长',
biz_type int(20) NOT NULL COMMENT '业务类型',
version int(20) NOT NULL COMMENT '版本号',
PRIMARY KEY (`id`)
)
biz_type:不同业务类型;version :版本号,就像 MVCC 一样,可以理解为乐观锁。
等 ID 都用完了,再去数据库获取,然后更改最大值:
update id_generator set max_id = #{max_id+step}, version = version + 1 where version = # {version} and biz_type = XXX;
- 优点:有比较成熟的方案,像美团 Leaf、滴滴 Tingid;
- 缺点:依赖于数据库实现。
美团 Leaf-segment 方案
Leaf 这个名字是来自德国哲学家、数学家莱布尼茨的一句话: There are no two identical leaves in the world “世界上没有两片相同的树叶”
Leaf 提供两种生成的 ID 的方式:号段模式(Leaf-segment)和 Snowflake 模式(Leaf-snowflake)。 你可以同时开启两种方式,也可以指定开启某种方式,默认两种方式为关闭状态。
Leaf-segment 号段模式是对直接用数据库自增 ID 充当分布式 ID 的一种优化, 减少对数据库的访问频率。相当于每次从数据库批量的获取自增 ID。
Leaf-server 采用了预分发的方式生成 ID,即可以在 DB 之上挂 N 个 Server,每个 Server 启动时, 都会去 DB 拿固定长度的 ID List。这样就做到了完全基于分布式的架构,同时因为 ID 是由内存分发, 所以也可以做到很高效。接下来是数据持久化问题,Leaf 每次去 DB 拿固定长度的 ID List, 然后把最大的 ID 持久化下来,也就是并非每个 ID 都做持久化,仅仅持久化一批 ID 中最大的那一个。其流程如下图所示:
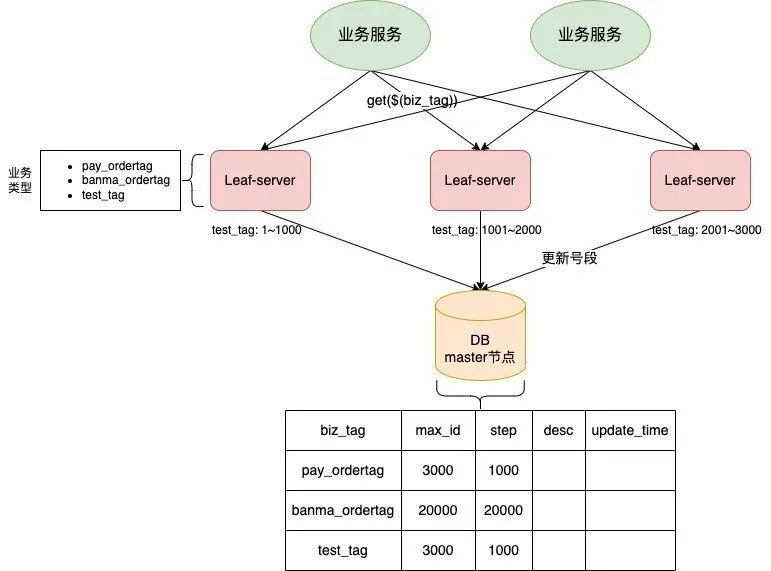
Leaf-server 中缓存的号段耗尽之后再去数据库获取新的号段,可以大大地减轻数据库的压力。 对 max_id 字段做一次 update 操作,update max_id = max_id + step,update 成功则说明新号段获取成功, 新的号段范围为(max_id, max_id + step]。
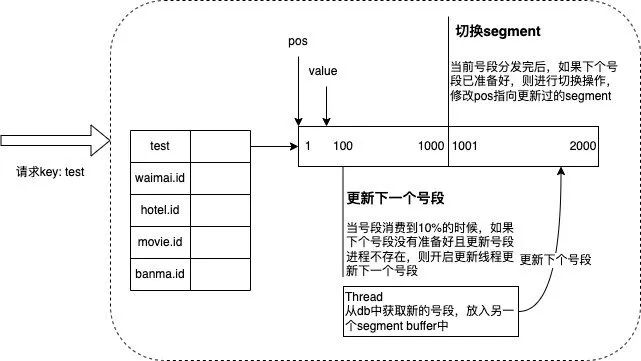
为了解决从数据库获取新的号段阻塞业务获取 ID 的流程的问题,Leaf-server 中采用了异步更新的策略, 同时通过双 buffer 的方式,如下图所示。通过这样一种机制可以保证无论何时 DB 出现问题, 都能有一个 buffer 的号段可以正常对外提供服务,只有 DB 在一个 buffer 的下发周期内恢复,都不会影响这个 Leaf 集群的可用性。
滴滴 Tingid 方案
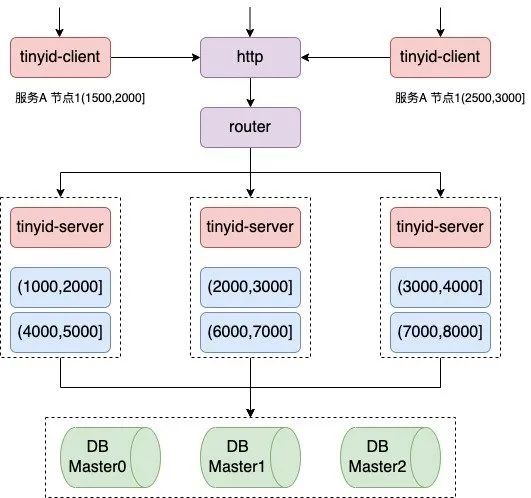
Tinyid 方案是在 Leaf-segment 的算法基础上升级而来,不仅支持了数据库多主节点模式, 还提供了 tinyid-client 客户端的接入方式,使用起来更加方便。
Tinyid 会将可用号段加载到内存中,并在内存中生成 ID,可用号段在首次获取 ID 时加载, 如当前号段使用达到一定比例时,系统会异步的去加载下一个可用号段,以此保证内存中始终有可用号段, 以便在发号服务宕机后一段时间内还有可用 ID。实现原理如下所示:
- 优点:方便集成,有成熟的方案和实现;
- 缺点:依赖 DB 稳定性,需要采用集群主从备份的方式提高 DB 可用性。
微信序列号生成方案
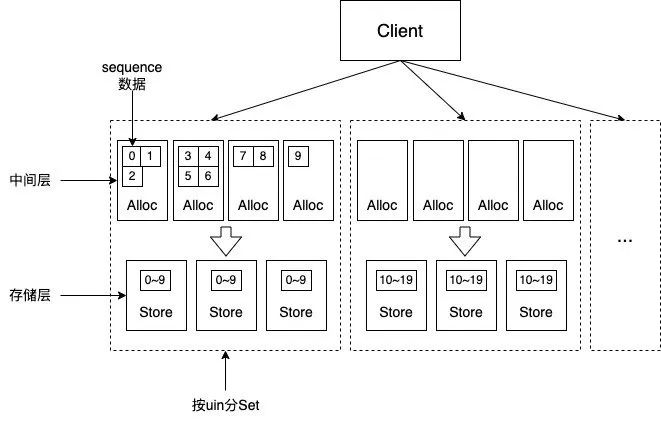
微信序列号跟用户 uin 绑定,具有以下性质:递增的 64 位整形;使用每个用户独立的 64 位 sequence 的体系, 而不是用一个全局的 64 位(或更高位) sequence ,很大原因是全局唯一的 sequence 会有非常严重的申请互斥问题, 不容易去实现一个高性能高可靠的架构。其实现方式包含如下两个关键点:
1)步进式持久化:增加一个缓存中间层,内存中缓存最近一个分配出现的 sequence:cur_seq,以及分配上限:max_seq; 分配 sequence 时,将 cur_seq++,与分配上限 max_seq 比较,如果 cur_seq > max_seq, 将分配上限提升一个步长 max_seq += step,并持久化 max_seq;重启时,读出持久化的 max_seq,赋值给 cur_seq。 此种处理方式可以降低持久化的硬盘 IO 次数,可以提升系统的整体吞吐量。
2)分号段共享存储:引入号段 section 的概念,uin 相邻的一段用户属于一个号段,共享一个 max_seq。 该处理方式可以大幅减少 max_seq 数据的大小,同时可以进一步地降低 IO 次数。
微信序列号服务的系统架构图如下图所示:
雪花模式
雪花模式介绍
雪花模式实现方式详见上面介绍的 snowflake 算法。
由于雪花算法强依赖于机器时间,如果时间上的时钟发生回拨,则可能引起生成的 id 冲突的问题。解决该问题的方案如下所示:
- 将 ID 生成交给少量服务器,然后关闭这些服务器的时钟回拨能力;
- 当遇到时钟回拨问题时直接报错,交给上层业务来处理;
- 如果回拨时间较短,在耗时要求范围内,比如 5ms,等待回拨时长后再生成 id 返回给业务侧;
- 如果回拨时间很长,无法等待,可以匀出少量位作为回拨位,一旦时间回拨,将回拨位加 1,可得到不一样的 ID, 2 位回拨可允许标记三次时钟较长时间的回拨,基本够使用。如果超过回拨次数,可以再选择报错或抛出异常。
美团 Leaf-snowflake 方案
Leaf-snowflake 方案沿用 snowflake 方案的 bit 位设计, 即”1+41+10+12“的方式组装 ID 号(正数位(占 1 比特)+ 时间戳(占 41 比特)
- 机器 ID(占 5 比特)+ 机房 ID(占 5 比特)+ 自增值(占 12 比特)),如下图所示:
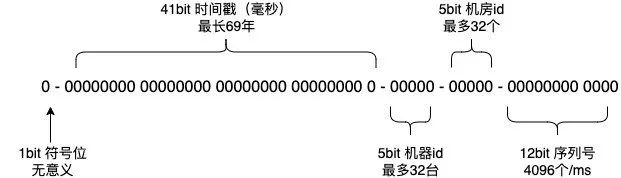
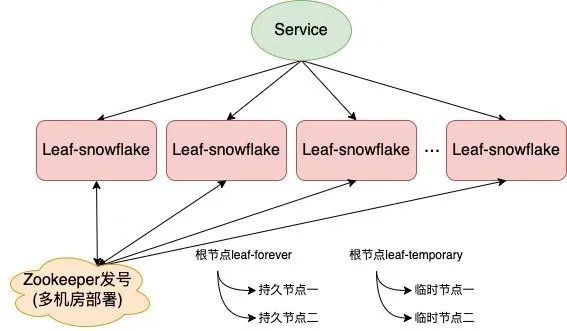
对于 workerID 的分配,当服务集群较小时,通过手动配置即可;当服务集群较大时,手动配置成本太高, 所以基于 zookeeper 持久顺序节点的特性引入 zookeeper 组件自动对 Snowflake 节点配置 workerID。部署架构如下图所示:
Leaf-snowflake 方案在处理时钟回拨问题的策略如下所示:
1)服务启动时
- 启动 Leaf-snowflake 服务,连接 Zookeeper,在 leaf_forever 父节点下检查自己是否已经注册过(是否有该顺序子节点);
- 如果注册过,则用自身系统时间与 leaf_forever/${self}节点记录时间做比较,若小于则认为机器时间发生了大步长回拨,服务启动失败并告警;
- 如果没有注册过,直接创建持久节点 leaf_forever/${self},并写入自身系统时间;
- 然后取 leaf_temporary 下的所有临时节点(所有运行中的 Leaf-snowflake 节点)的服务 IP:Port, 然后通过 RPC 请求得到所有节点的系统时间,计算 sum(time)/nodeSize;
- 如果若 abs( 系统时间-sum(time)/nodeSize ) < 阈值,认为当前系统时间准确,正常启动服务, 同时写临时节点 leaf_temporary/${self} 维持租约;否则认为本机系统时间发生大步长偏移,启动失败并报警;
- 每隔一段时间(3s)上报自身系统时间写入 leaf_forever/${self}。
2)服务运行时
- 会检查时钟回拨时间是否小于 5ms,若时钟回拨时间小于等于 5ms,等待时钟回拨时间后,重新产生新的 ID; 若时钟回拨时间大于 5ms,直接抛异常给到业务侧。
官网的流程图:
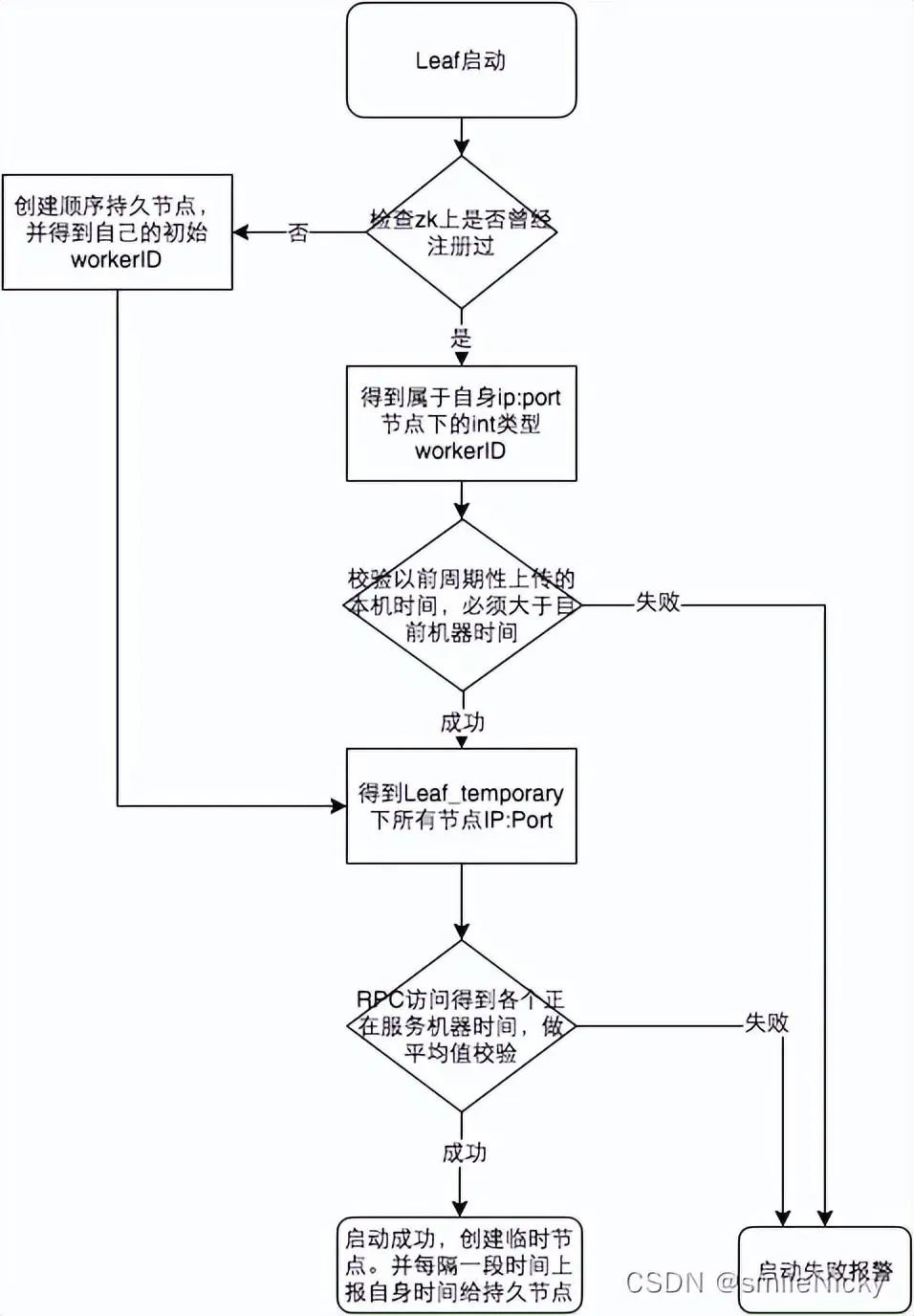
详细介绍请看官网:https://tech.meituan.com/2017/04/21/mt-leaf.html
百度 UidGenerator 方案
官网的解释: UidGenerator 是 Java 实现的, 基于 Snowflake 算法的唯一 ID 生成器。UidGenerator 以组件形式工作在应用项目中, 支持自定义 workerId 位数和初始化策略,从而适用于 docker 等虚拟化环境下实例自动重启、漂移等场景。 在实现上, UidGenerator 通过借用未来时间来解决 sequence 天然存在的并发限制;采用 RingBuffer 来缓存已生成的 UID, 并行化 UID 的生产和消费,同时对 CacheLine 补齐。避免了由 RingBuffer 带来的硬件级「伪共享」问题. 最终单机 QPS 可达 600 万。
UidGenerator 方案是基于 snowflake 算法的唯一 ID 生成器。其对雪花算法的 bit 位的分配做了微调,如下图所示:

UidGenerator 方案包含以下两种实现方式:
1)DefaultUidGenerator 实现方式
DefaultUidGenerator 方式的实现要点如下所示:
- delta seconds:在上图中用 28bit 部分表示,指当前时间与 epoch 时间的时间差,单位为秒。 epoch 时间指集成 DefaultUidGenerator 生成分布式 ID 服务第一次上线的时间,可配置。
- worker id:在上图中用 22bit 部分表示,在使用 DefaultUidGenerator 方式生成分布式 ID 的实例启动的时候, 往 db 中写入一行数据得到的自增 id 值。由于 worker id 默认 22 位, 允许集成 DefaultUidGenerator 生成分布式 id 的所有实例的重启次数不超过 4194303 次,否则会抛出异常
- sequence:在上图中用 13bit 部分表示,通过 synchronized 保证线程安全;如果时间有任何的回拨,直接抛出异常; 如果当前时间和上一次是同一秒时间,sequence 自增,如果同一秒内自增至超过 2^13-1,自旋等待下一秒; 如果是新的一秒,sequence 从 0 开始。
DefaultUidGenerator 方式在出现任何刻度的时钟回拨时都会直接抛异常给到业务层,实现比较简单粗暴。 故使用 DefaultUidGenerator 方式生成分布式 ID,需要根据业务情况和特点,调整各个字段占用的位数。
2)CachedUidGenerator 实现方式
CachedUidGenerator 的核心是利用 RingBuffer,本质上是一个数组,数组中每个项被称为 slot。 CachedUidGenerator 设计了两个 RingBuffer,一个保存唯一 ID,一个保存 flag。其实现要点如下所示:
- 自增列:UidGenerator 的 workerId 在实例每次重启时初始化,且就是数据库的自增 ID, 从而完美的实现每个实例获取到的 workerId 不会有任何冲突。
- RingBuffer:UidGenerator 不再在每次取 ID 时都实时计算分布式 ID, 而是利用 RingBuffer 数据结构预先生成若干个分布式 ID 并保存。
- 时间递增:UidGenerator 的时间类型是 AtomicLong,且通过 incrementAndGet()方法获取下一次的时间, 从而脱离了对服务器时间的依赖,也就不会有时钟回拨的问题。
官网说明:https://github.com/baidu/uid-generator/blob/master/README.zh_cn.md
基于多时间线改进的雪花算法
基于多时间线改进的雪花算法在 snowflake 基础上增加了时间线部分(1~2 位),可同时支持 2~4 条时间线并行。 其对雪花算法的 bit 位的分配做了微调,如下图所示:

基于多时间线改进的雪花算法生成 ID 过程如下所示:
- 初始时,所有时间线进度均为基准时间,随机选定一条时间线作为当前时间线;
- 在当前时间线上生成 ID,同时推进当前时间线进度;
- 一旦发生时钟回退,且回退距离小于一定阈值,等待时间推进直到回退前的时间,会到步骤 2 继续生成 ID;
- 如果回退距离大于阈值,暂停当前时间线进度,选择一条合适的时间线(进度<当前时间)并切换到该时间线, 回到步骤 2 继续生成 ID。如果找不到合适的时间线,报错返回。
该方案虽然通过设置时间线方式有效解决了时钟回退问题,但是削弱了 snowflake 的趋势递增特性。 比较适合对于一些频繁地、小步长的时钟回退情况,即能做到全局唯一,又能很好地兼顾递增趋势。
PHP 中雪花ID生成实例
PHP 中雪花ID生成的实例,可以参考 https://ibaiyang.github.io/blog/php/2019/02/27/雪花ID相关.html
PHP 批量生成兑换码实例
PHP 批量生成兑换码实例,可以参考 https://ibaiyang.github.io/blog/php/2022/10/17/PHP-批量生成兑换码实例.html
参考资料
分布式唯一 ID 生成方案浅谈 https://mp.weixin.qq.com/s?__biz=MzI3NDA4OTk1OQ==&mid=2649921108&idx=1&sn=d1cb839f61d31532dc68ed74857201f7
万亿级调用系统:微信序列号生成器架构设计及演变 https://blog.csdn.net/wzzfeitian/article/details/78756998
你会几种分布式 ID 生成方案? <hhttps://mp.weixin.qq.com/s/enQ9OAEtPBCZpT9_jjRuWw>