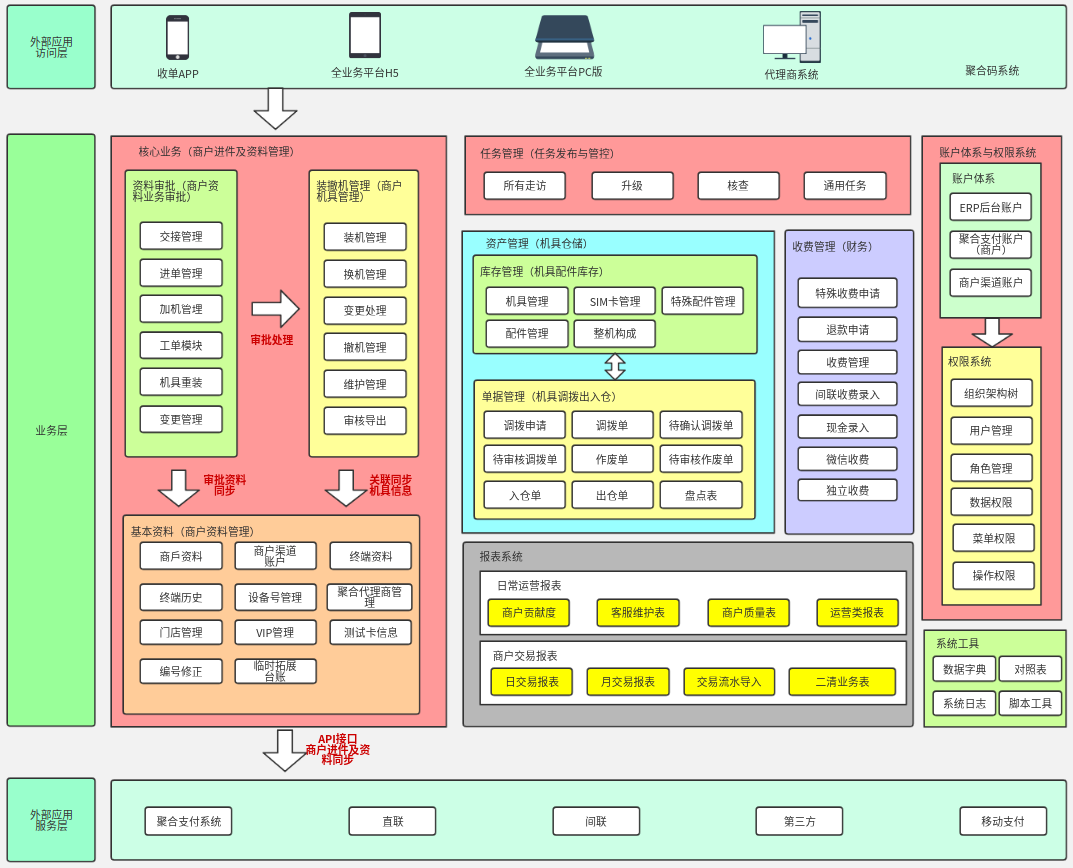
正文
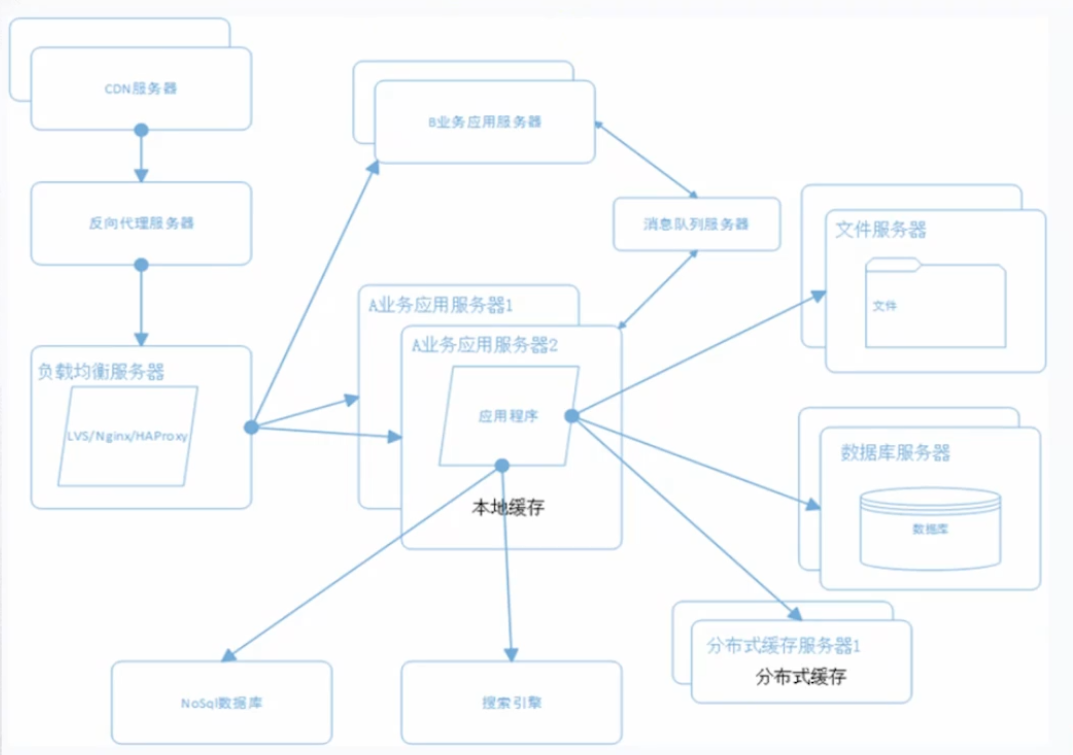
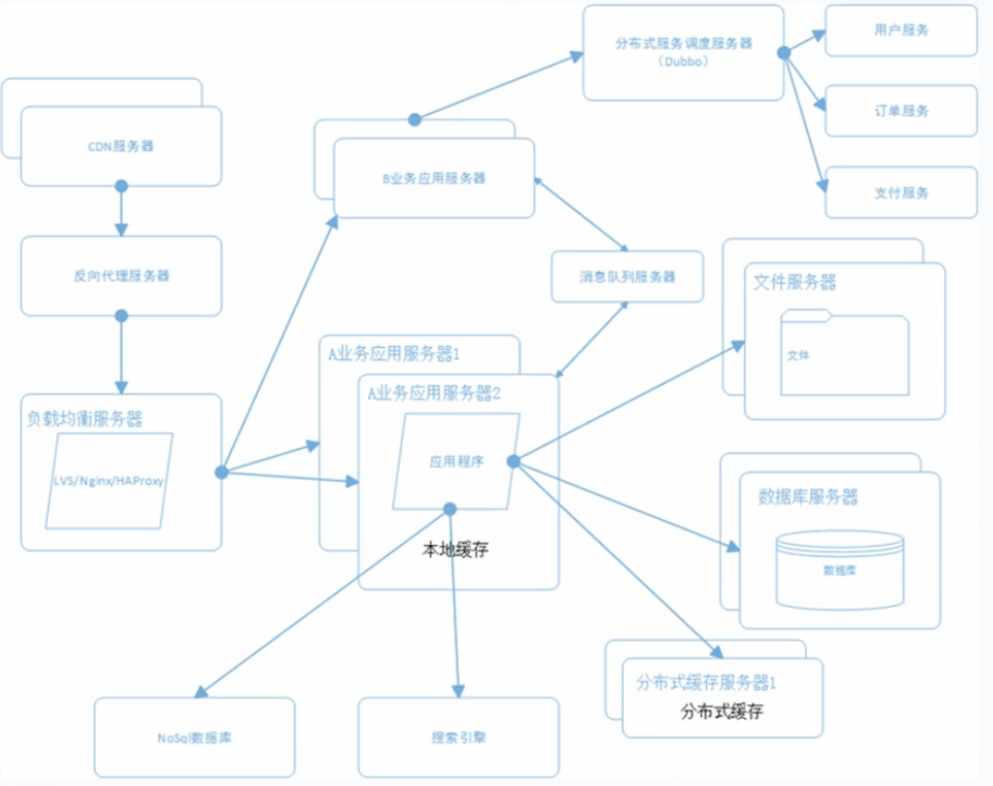
常见架构
1
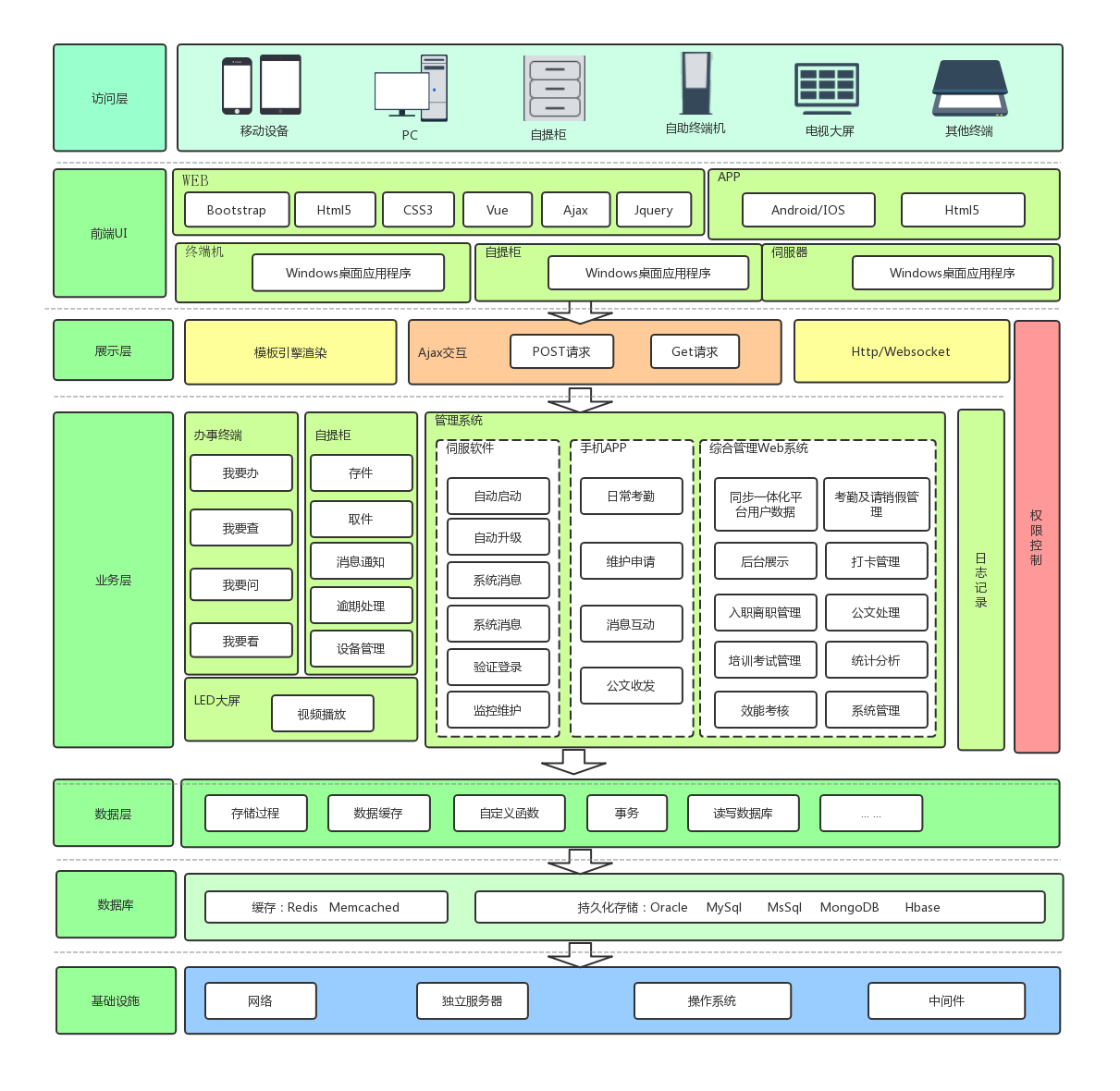
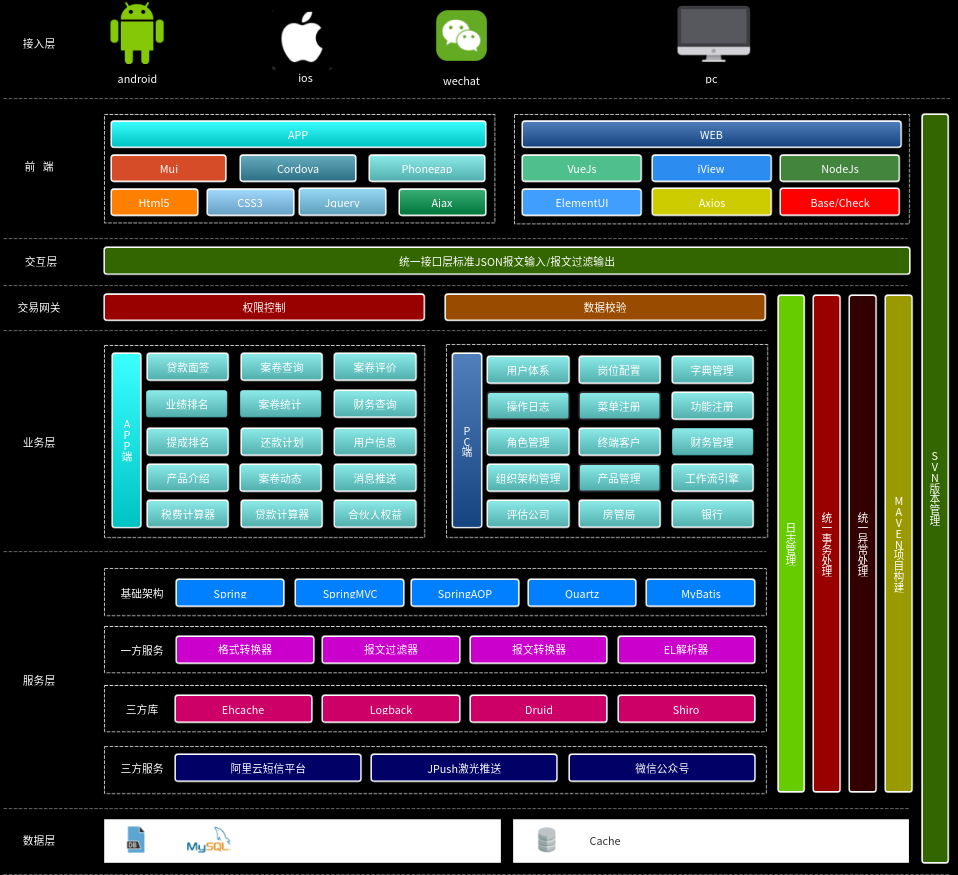
2
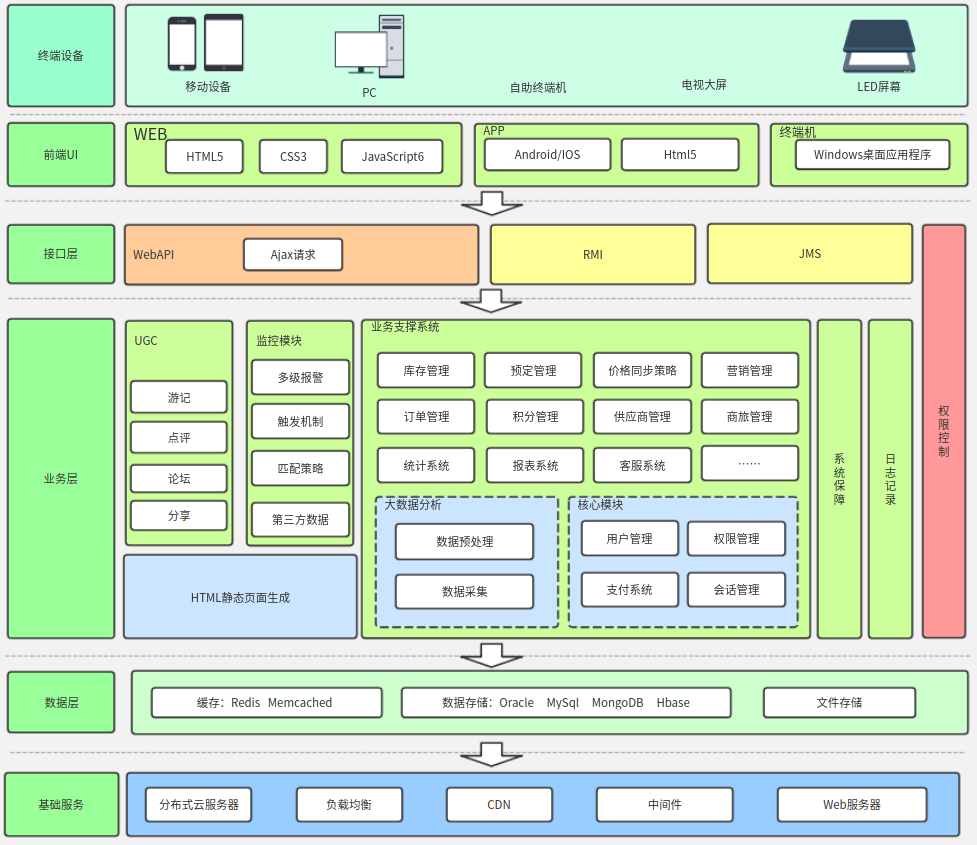
3
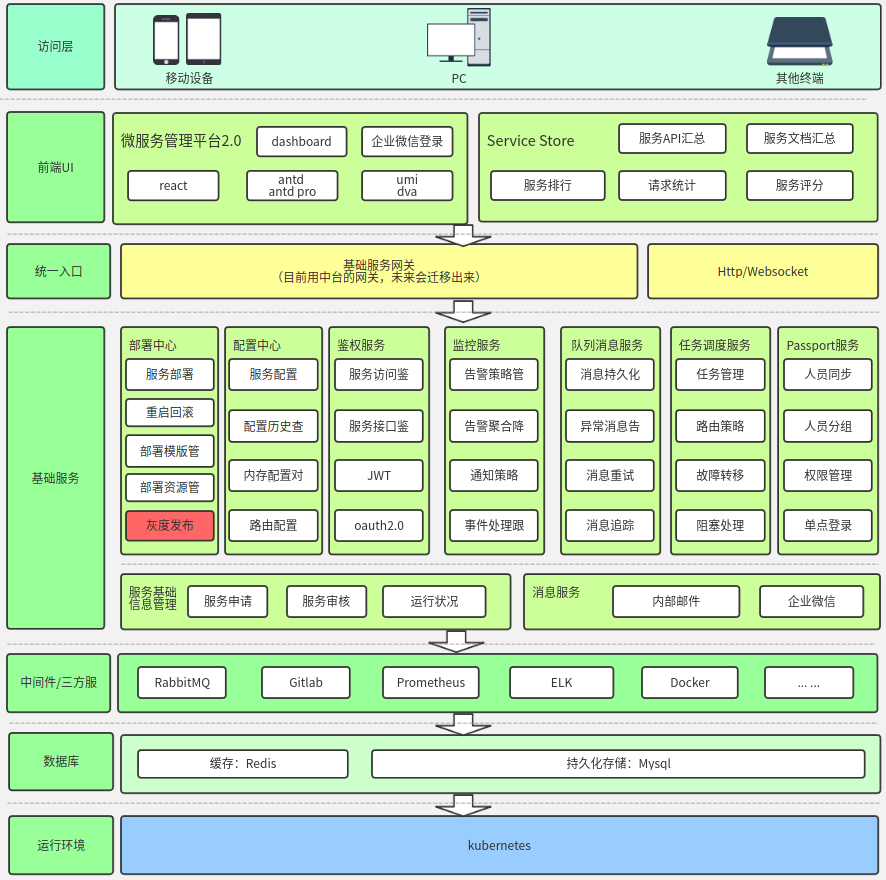
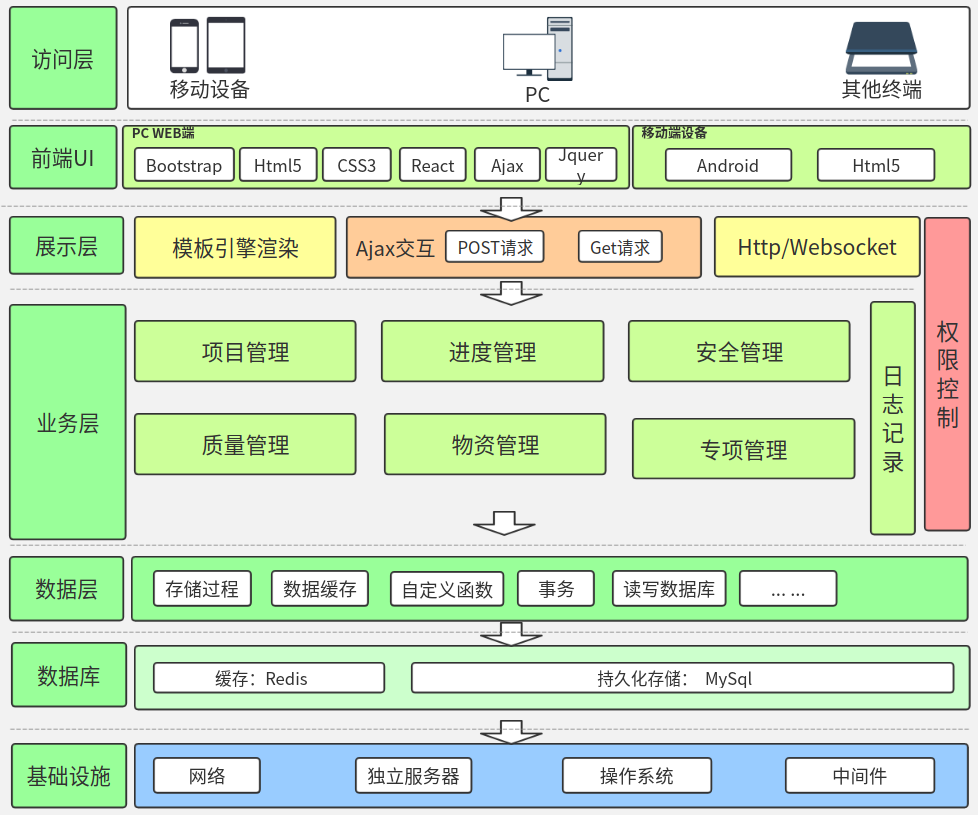
4
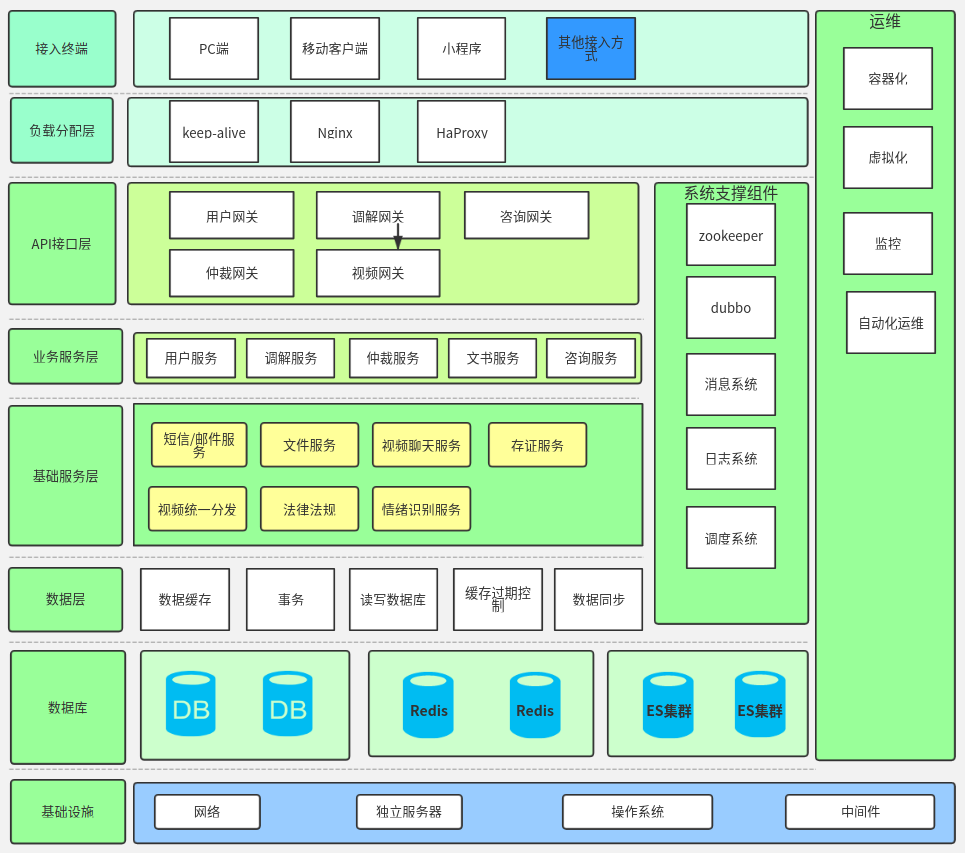
5
6
7
系统架构演变与高并发高可用原则
系统设计的定律
1 设计系统时——墨菲定律
墨菲定律,原文为:如果有两种或两种以上的方式去做某件事情,而其中一种选择方式将导致灾难,则必定有人会做出这种选择。 根本内容是:如果事情有变坏的可能,不管这种可能性有多小,它总会发生。
2 系统划分时——康威定律
第一定律
Communication dictates design
组织沟通方式会通过系统设计表达出来
第二定律
There is never enough time to do something right, but there is always enough time to do it over.
时间再多一件事情也不可能做的完美,但总有时间做完一件事情
第三定律
There is a homomorphism from the linear graph of a system to the linear graph of its design organization
线型系统和线型组织架构间有潜在的异质同态特性
第四定律
The structures of large systems tend to disintegrate during development, qualitatively more so than with small systems
大的系统组织总是比小系统更倾向于分解
系统架构的演变
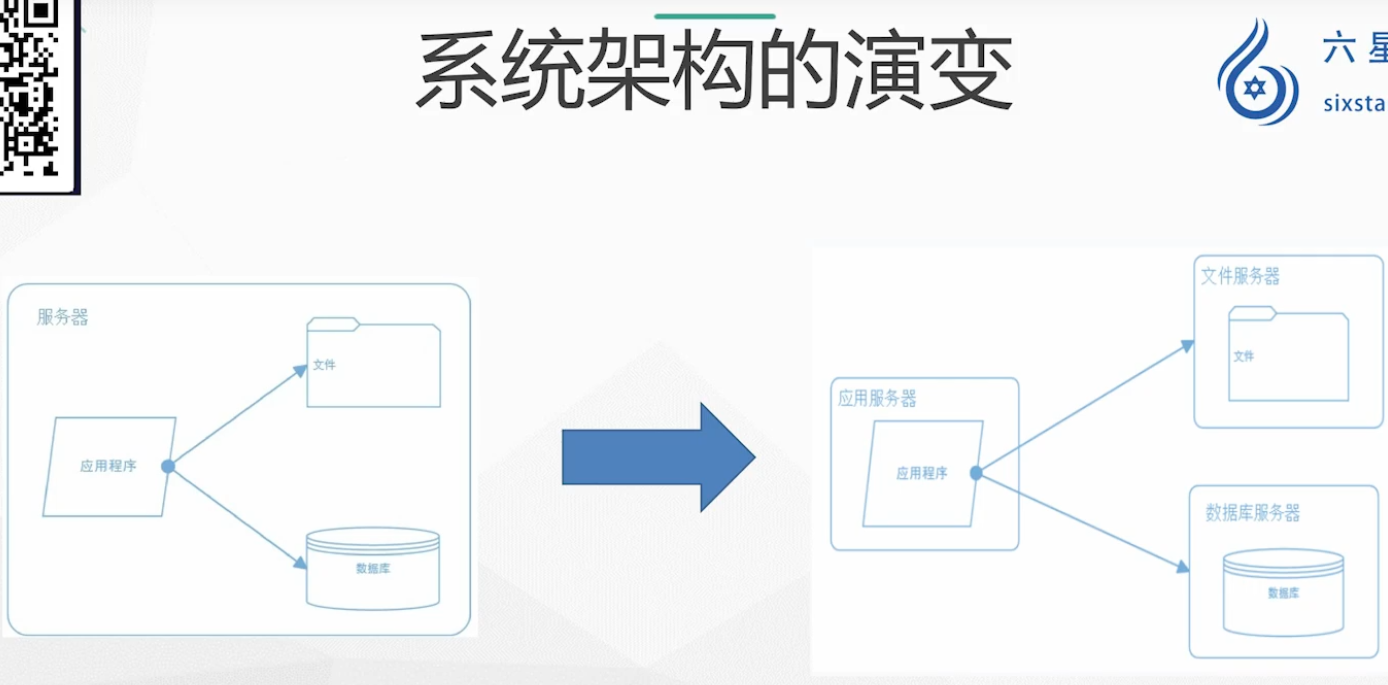
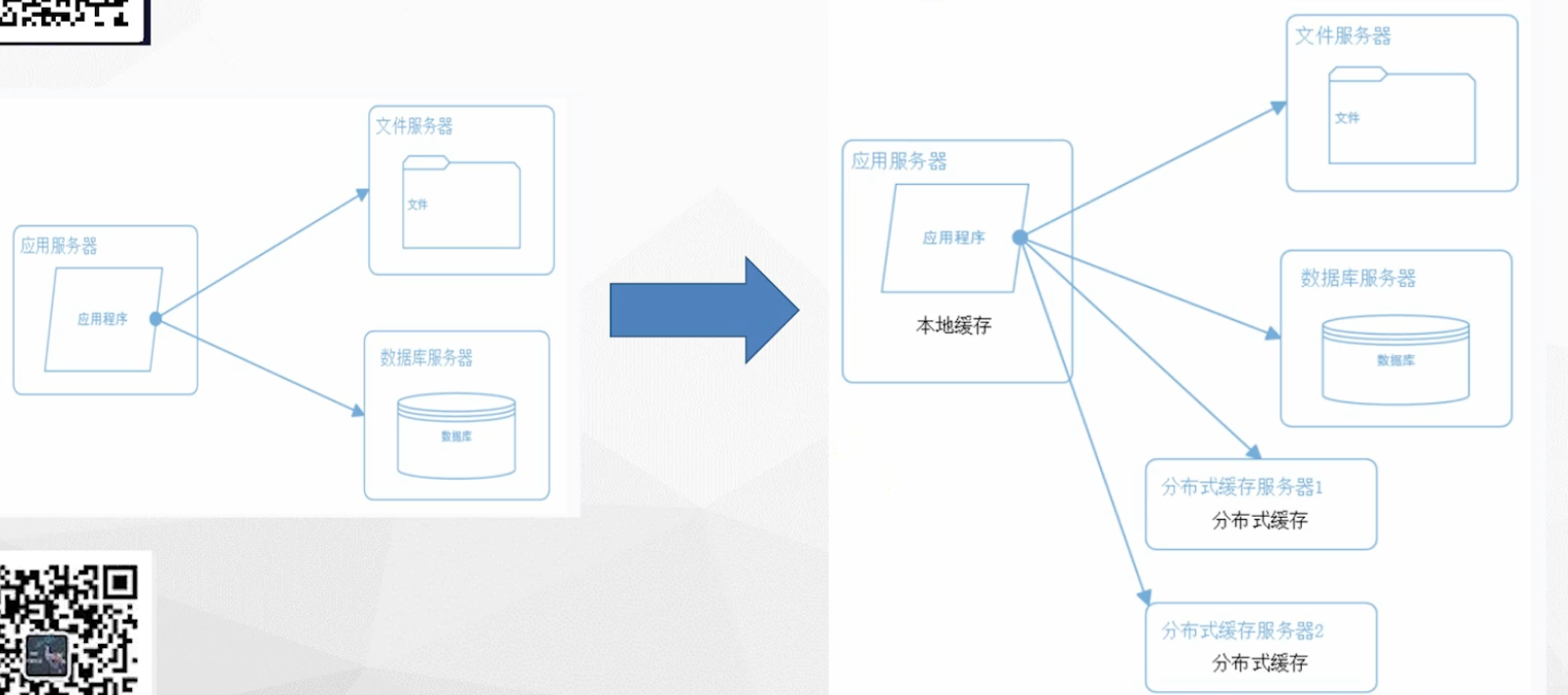
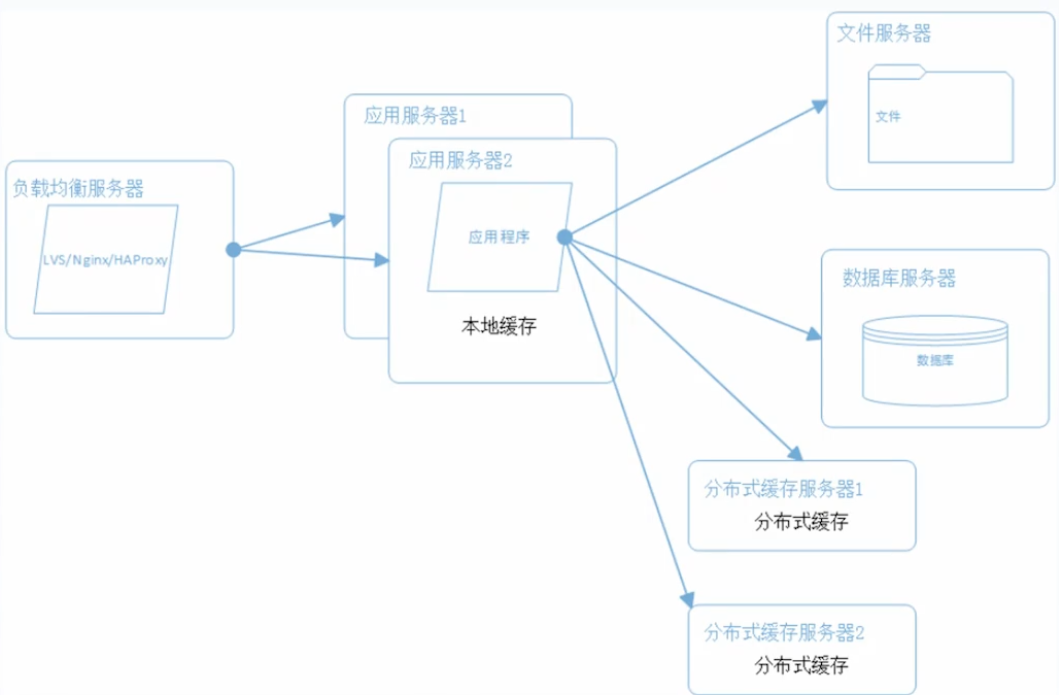
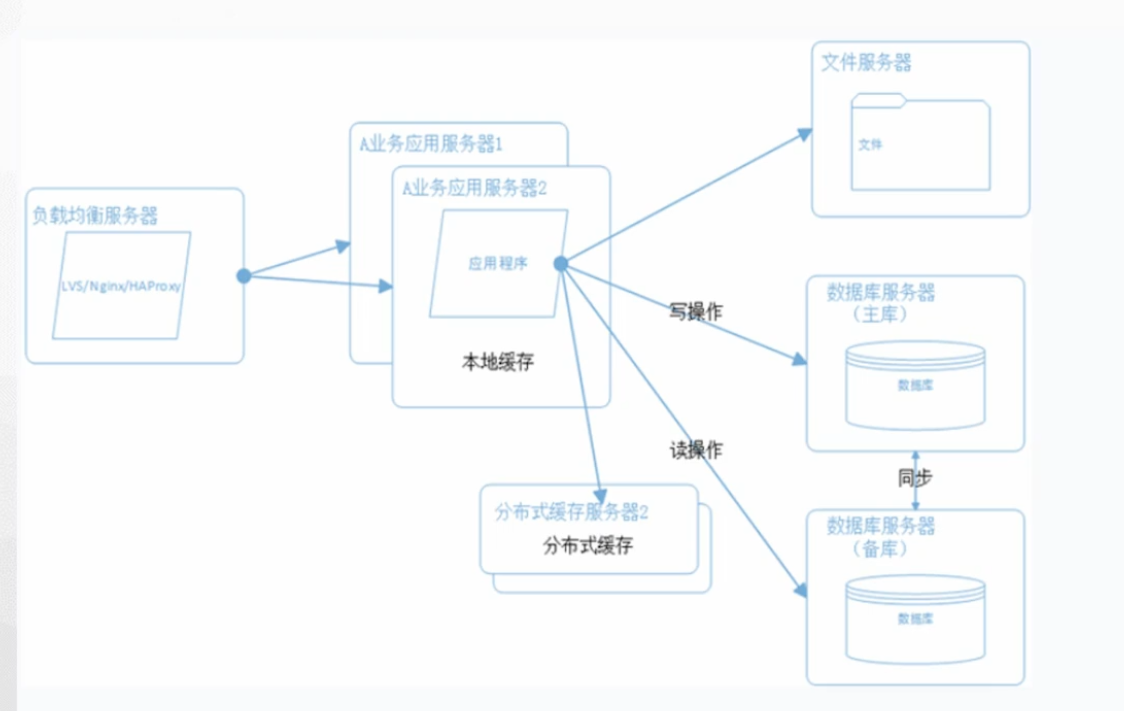
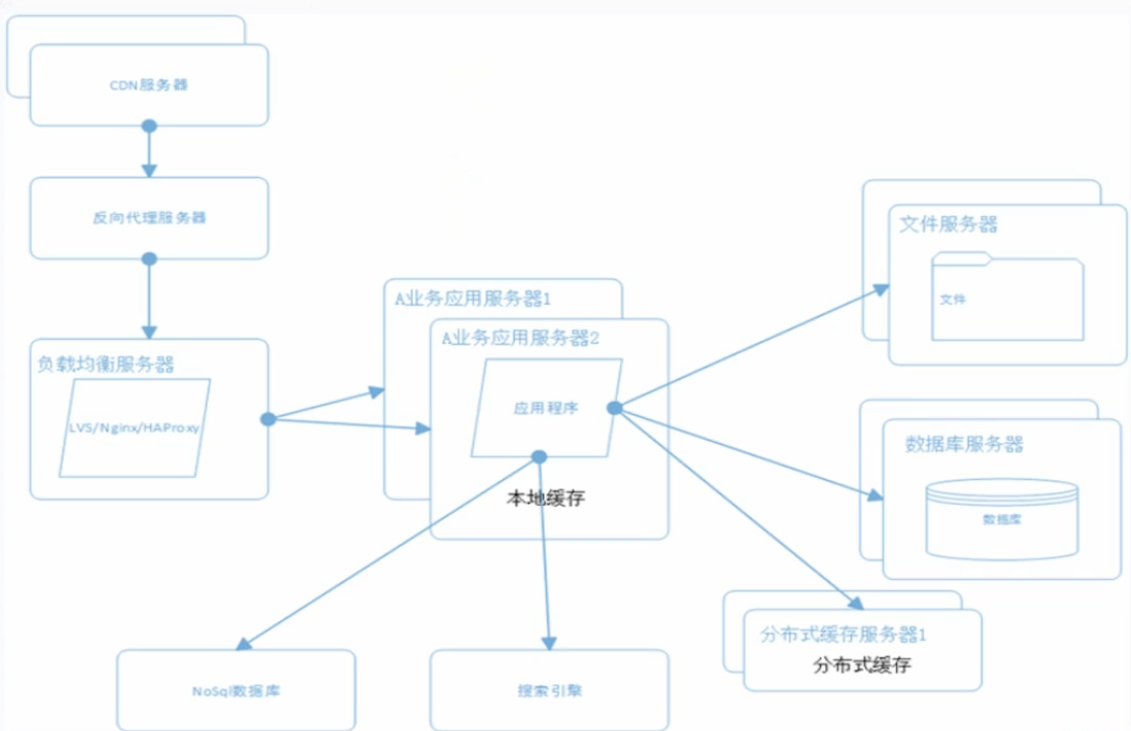
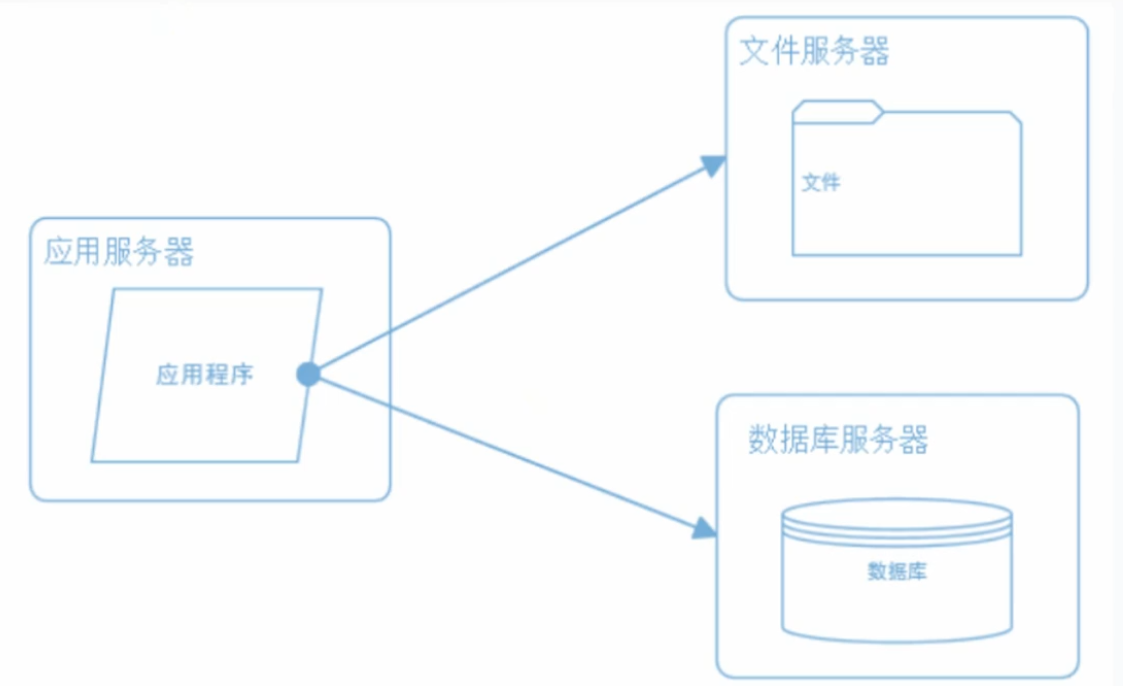
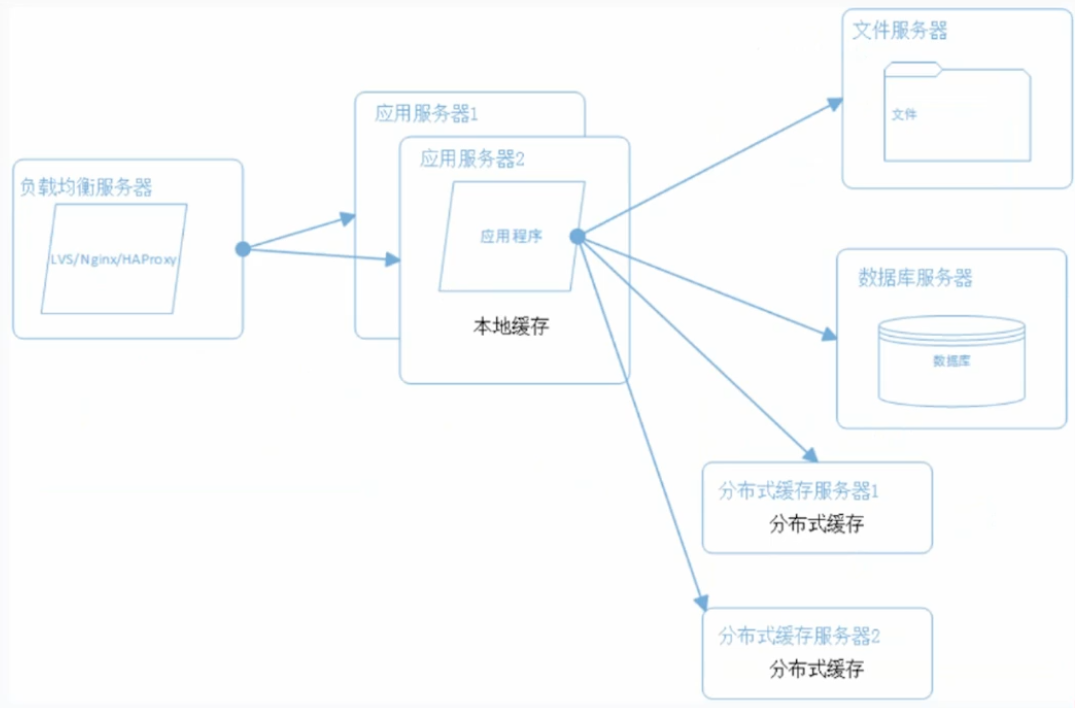
数据库拆分:
- 商品数据库
- 订单数据库
- 咨询数据库
- 等等
分布式与集群及微服务的区别
分布式
集群
微服务
组件
高并发的原则及处理
1 拆分
系统维度:商品、订单、支付、用户
功能维度:支付、优惠券 -> 创建、领取… 、用户
读写维度:商品 -> 读服务、写服务
模块维度:三层架构 web-controller、service、model
AOP维度:权限登入、配置
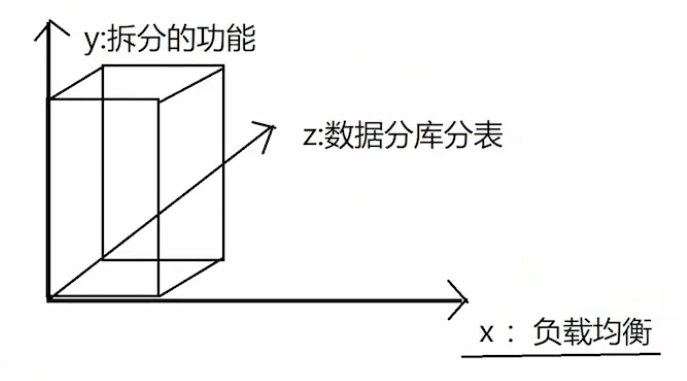
2 服务化与无状态
服务化:基于拆分之后的操作
相对独立、功能内聚的一组业务,数据自我包含;rpc、api
无状态:
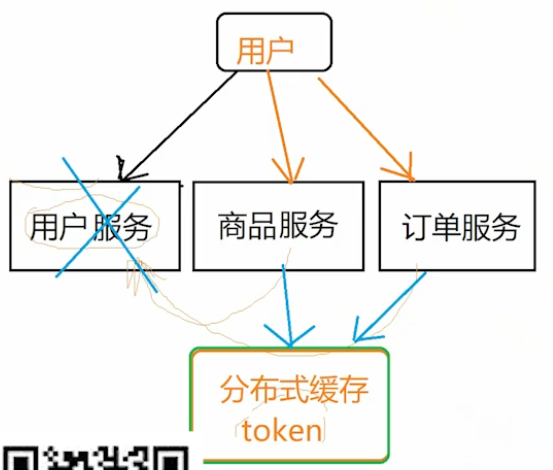
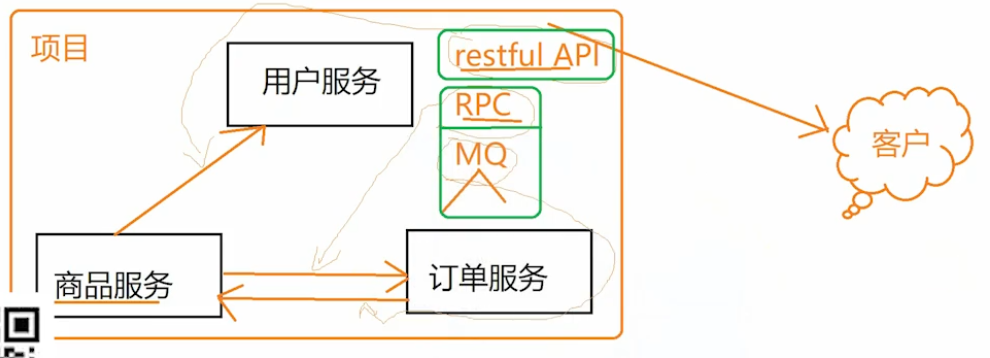
3 服务通信
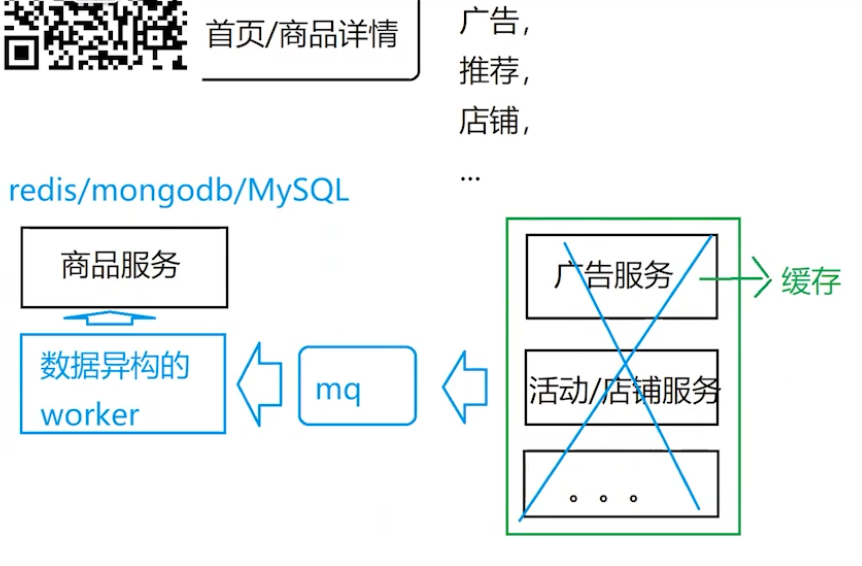
4 数据异构
5 缓存引导
客户端:浏览器、手机
cdn、镜像服务器、nginx、应用层、分布式缓存、静态化…
6 并发化
主要是针对不同的业务操作
- 广告信息
- 活动信息
- 店铺信息
- …
多进程/协程/多线程方式处理
高可用的原则及处理
- 限流
- 降级
- 熔断
- 切流量 (备机)
- 可回滚 (版本化)
九大场景
以下九大场景,80个架构问题:
第一章:技术选型
创业初期架构方案怎么选型?
- 要考虑业务的需求与特点,初期往往“快速实现”更重要,此时系统的特点是请求量小,数据量小,服务器资源也非常有限;
- 这个阶段最重要的选型依据是:合伙人熟悉什么技术栈,使用什么技术栈;
- 第一版往往采用ALL in one架构;
- 这个阶段研发主要在写CURD业务逻辑,引入DAO和ORM能极大提高工程效率;
画外音:什么是ALL in one架构?
如果硬要问我,会选择什么技术栈,我会二选一:
- PHP体系(Linux,Nginx,MySQL,PHP)
- Java体系(Linux,Tomcat,MySQL,Java)
使用开源框架组件还是自研?
我的观点是:
- 早期不建议自研;
- 随着规模的扩大,要控制技术栈;
- 要浅浅的封装一层;
- 适当的时候,造一些契合业务的轮子;
画外音:为什么要控制技术栈?为什么要封装一层?
什么情况下要进行容量评估?
至少在三种情况下,要进行容量评估:
- 新系统上线;
- 临时运营活动;
- 系统容量有质变性增长;
系统层面,要评估哪些重要指标?
主要评估网络带宽、CPU、内存容量、磁盘容量、磁盘IO等资源指标,系统层面主要看吞吐量指标。
画外音:容量设计五大步骤是啥?
创业初期,系统层面存在瓶颈的时候,优化原则是什么?
- 最低成本,初期最大的成本是时间成本;
- 用“钱”和“资源”快速解决系统问题,而不是过早的系统重构;
- 将ALL in one架构升级为伪分布式架构,是此阶段的最佳实践;
伪分布式的核心是什么?
伪分布式的本质是单机变多机,但又不是真正的高可用,其核心是垂直拆分:
- 业务垂直拆分;
- 代码垂直拆分;
- 数据库垂直拆分;
- 研发团队垂直拆分;
画外音:伪分布式的优化细节是啥?
第二章:接入层架构
如何解决接入层的扩展性问题?
引入反向代理。
最常见的反向代理是什么?
Nginx。
引入反向代理之后,要解决什么新的问题?
- 集群负载均衡;
- 反向代理高可用;
画外音:有哪些常见的负载均衡方法?如何保证反向代理高可用?
站点流量从小到大,接入层架构如何演进?
整体可以分为五个阶段:
- 有反向代理技术之前,单体架构要解决扩展性问题,可使用DNS轮询架构;
- 有反向代理技术之后,初期可以使用反向代理解决扩展性问题;
- 然后,需要升级为高可用反向代理架构;
- 多级反向代理,引入LVS&F5进一步扩充性能;
- 想要无限性能,必须用DNS轮询架构;
画外音:每个阶段的逻辑与细节到底是怎么样的?
Session,是接入层架构非常关注的问题,如何保证Session一致性?
通常有四种方案:
- 客户端层解决;
- 反向代理层解决;
- web-server层解决;
- 后端服务层解决
画外音:每种方案细节又是怎么样的?
CDN,是接入层不得不谈的问题,CDN架构有哪些要了解?
引入CDN架构,至少要考虑这五个问题:
- 什么样的资源适合静态加速;
- CDN的架构是怎么样的;
- CDN是怎么实现“就近访问的”;
- 如何保证源站和镜像站数据的一致性;
- 资源更新,是推还是拉?
画外音:学CDN,千万不要去百度“斯塔尔报告”。
TCP接入,架构上要考虑哪些问题?
至少要考虑这四个架构设计点:
- TCP如何快速实现接入;
- TCP如何快速实现扩展,以及高可用;
- TCP如何快速实现负载均衡;
- TCP如何保证扩展性与耦合性的平衡;
画外音:有没有综合方案,系统性解决负载均衡 + 高可用 + 可扩展 + 解耦合等一系列问题?
第三章:急速性能优化
在互联网公司发展早期,为了产品快速迭代,最常使用的架构是什么?
ALL in one架构。
如果此时业务发展很快,系统成了瓶颈,架构优化的方向是什么?
用最短时间,以对代码最小的冲击,极速扩充系统性能。
早期如何快速的扩充系统性能?
使用三大分离的性能优化方法。
早期系统容易“白屏”,如何快速的提升用户体验,消除白屏?
动静分离。
什么是动静分离?
动静分离,是“静态页面与动态页面,分开不同的系统访问”的架构设计方法。
画外音:如何来实施?分别对应怎样的技术点?
如果静态页面访问这么快,动态页面访问这么慢,能否将“原本需要动态生成的页面,提前生成静态页面”?
可以,这是“页面静态化”技术,能够100倍提升访问速度。
画外音:这个技术适用怎么样的业务场景?
早期系统的主要瓶颈,最容易出现在哪里?
数据库读性能扛不住。
如何快速提升数据库读性能?
读写分离,使用数据库分组架构,一主多从,主从同步,读写分离。
画外音:读写分离,水平切分都是使用数据库集群,有什么异同?
后台运营系统,复杂的SQL语句对数据库性能影响较大,怎么办?
前台与后台分离。
画外音:前后端分离,前台后台分离,是一回事么?如何快速实施前台与后台分离?
第四章:微服务架构
系统初期,哪类技术栈最为流行?
- PHP语言的LAMP栈;;
- Java语言的LiToMyJa栈;
业务快速发展,三层架构可能存在哪些问题?
- 代码频繁拷贝;
- 底层复杂性扩散;
- 公共库耦合;
- SQL质量不可控,数据库性能急剧下降;
- 数据库耦合,无法实现增加实例扩容;
可以通过什么架构方案解决上述1-5问题?
微服务架构。
如果要落地微服务架构,服务粒度可以如何选择?
常见的有以下四种粒度:
- 统一服务层;
- 按业务划分服务;
- 按库划分服务;
- 按接口划分服务(需要轻量级进程等语言层面支持);
微服务架构,可能带来什么问题?
可能带来的潜在问题有:
- 系统复杂性上升;
- 层次间依赖关系变得复杂;
- 运维,部署更麻烦;
- 监控变得更复杂;
- 定位问题更麻烦;
不要以为,引入一个RPC框架就是“微服务架构”了,微服务架构要解决很多问题。
微服务架构要解决哪些问题?
至少要解决高可用,无限性能扩展,负载均衡等众多架构基础问题。
如何解决高可用的问题?
每一层解决高可用问题的方案不一样,涉及虚IP,反向代理,集群,连接池,数据库分组,缓存冗余,故障转移等诸多技术。
画外音:高可用的方法论是什么?
如何解决无限性能扩展的问题?
每一层解决高可用问题的方案不一样,涉及Scale up,Scale out,DNS轮询,反向代理,连接池,水平切分等诸多技术。
画外音:无限性能的方法论是什么?
如何解决负载均衡的问题?
负载均衡分为两类:
- 同构均匀分摊;
- 异构按能力分摊;
异构服务器负载均衡,常见的这么几种方案:
- 静态权重法;
- 动态权重法,涉及“保险丝”算法;
同时,动态权重法还可以实现服务器的过载保护。
画外音:什么是“保险丝”算法?什么是过载保护?
哪一个组件,和高可用,无限性能扩展,负载均衡相关?
连接池。
连接池的核心是什么?
- 两个核心数据结构:连接数组,锁数据;
- 三个核心接口:初始化,拿出连接,放回连接;
画外音:如何快速掌握连接池内核?
第五章:数据库架构
工程上,数据库要设计一些什么?
- 根据“业务模式”设计表结构;
- 根据“访问模式”设计索引结构;
架构上,数据库还必须考虑什么?
- 读性能提升;
- 高可用;
- 一致性保障;
- 扩展性;
- 垂直拆分;
画外音:我C,我居然从来没考虑过这些问题。
提升系统读取速度,有哪几种常见方法?
- 建立索引;
- 增加从库;
- 增加缓存;
一个数据库分组集群,主从同步,读写分离,能不能在主库和从库建立不同的索引?
可以,例如:
- 主库只响应写请求,不建立索引;
- 线上从库,建立线上访问索引;
- 后台从库,建立后台访问索引;
如何保证数据库的高可用?
核心思想是:冗余+故障自动转移:
- 写库高可用,冗余写库;
- 读库高可用,冗余读库;
数据冗余会带来什么副作用?
会引发一致性问题:
- 两个写库数据可能不一致;
- 主库和从库数据可能不一致;
写库高可用,两个写库相互同步数据,自增ID可能冲突导致数据不一致,有什么优化方案?
- 为每个写库指定不同的初始值,相同的增长步长;
- 生成不同的ID;
- 一个写库提供服务,一个写库作为高可用影子主;
主从延时,有什么优化方案?
- 业务容忍;
- 强制读主;
- 在从库有可能读到旧数据时,选择性读主(非常帅气的方案);
底层表结构变更,水平扩展分库个数发生变化,底层存储引擎升级,数据库如何平滑过度?
如果业务能够接受,可以停服扩展。
否则,可以使用以下三种方法:
- 追日志平滑扩容法,平滑过度;
- 双写平滑扩容法,平滑过度;
- 秒级平滑扩容法(非常帅气的方案);
画外音:如何在秒级,实现读写实例加倍?容量加倍?
数据库垂直拆分的最佳实践是什么?
数据库垂直拆分,尽量把:
- 长度短;
- 访问频率高;
- 经常一起访问; 的数据放在主表里。
第六章:缓存架构
工程上,缓存一般有几种使用方式?
- 进程内缓存;
- 进程外缓存,也就是缓存服务;
如果有多个服务使用进程内缓存,如何保证一致性?
常见的有三种方法:
- 服务节点同步通知;
- MQ异步通知;
- 牺牲少量一致性,定期后端更新;
绝大部分情况,还是应该使用缓存服务,缓存的使用,有什么注意点?
以下几点,应该要注意:
- 服务与服务之间不要通过缓存传递数据;
- 如果缓存挂掉,可能导致雪崩,此时要做高可用缓存,或者水平切分;
- 调用方不宜再单独使用缓存存储服务底层的数据,容易出现数据不一致,以及反向依赖;
- 不同服务,缓存实例要做垂直拆分,不宜共用缓存;
互联网缓存操作细节,最佳实践是什么?
Cache Aside Pattern。
Cache Aside Pattern的细节是什么?
它分为读缓存最佳实践,以及写缓存最佳实践。
读缓存最佳实践是:先读缓存,命中则返回;未命中则读数据库,然后设置缓存。
写缓存最佳实践是:
- 淘汰缓存,而不是修改缓存;
- 先操作数据库,再操作缓存;
画外音:为什么呢?
缓存的本质是“冗余了数据库中的数据”,可能存在什么问题?
缓存与数据库数据不一致。
什么场景下容易出现不一致?
写后立即读业务场景。
画外音:为什么呢?
出现不一致时,优化思路是什么?
及时把缓存中的脏数据淘汰掉。
具体要怎么淘汰,保证缓存与数据库中数据的一致性呢?
- 服务同步二次淘汰法;
- 服务异步二次淘汰法;
- 线下异步二次淘汰法;
画外音:二次淘汰法,是很常见的一种实践。
目前缓存服务最常用的是什么?
Redis和memcache。
什么时候选择使用Redis?
以下场景优先使用Redis:
- 需要支持复杂数据结构;
- 需要支持持久化;
- 需要天然高可用;
- value存储内容比较大;
如果只是纯KV,可以使用memcache。
画外音:纯KV场景,为什么memcache会更快呢?
第七章:架构解耦
配置文件,是互联网架构中不可缺少的一环。依赖(调用)某个下游服务集群,将下游集群信息放在自身配置文件里是一种惯用做法,该做法可能导致什么问题?
可能导致上下游严重耦合:
- 上游痛:扩容的是下游,改配置重启的是上游;
画外音:架构设计中典型的反向依赖。
- 下游痛:不知道谁依赖于自己,难以实施服务治理,按调用方限流;
为了解决上述问题,常见的配置架构演进是怎么样的?
- “配置私藏”架构;
- “全局配置文件”架构;
- “配置中心”架构;
除了配置中心,消息总线MQ也是互联网架构中的常见解耦利器。
一般来说,什么时候不使用MQ?
上游实时关注执行结果时,通常不使用MQ,而使用RPC调用。
什么情况下,可以使用MQ来解耦?
以下四种情况,可以使用MQ来解耦:
- 数据驱动的任务依赖;
- 上游不关心执行结果;
- 上游关注结果,但执行时间很长,例如跨公网调用第三方服务;
- 削峰填谷,流量控制,保护下游;
上下游IP耦合,可以如何解耦?
使用内网域名来代替内网IP。
多个模块,因为公共库而耦合在一起,可以如何解耦?
粗暴方案:代码各自拷贝一份(不太推荐)。
优化方案:
- 垂直拆分,个性业务代码“上浮”;
- 服务化,共性业务代码“下沉”;
多个模块,因为数据库而耦合在一起,可以如何解耦?
数据库耦合,需要对架构进行调整:
- 第一步,公共数据访问服务化,数据私藏;
- 第二步,个性数据访问,自己家的数据自己管理;
画外音:数据库耦合,当数据库成为瓶颈时,增加数据库实例也难以拆分扩容,非常头疼。
微服务拆分不完全,导致耦合,可以如何解耦?
- 底层微服务功能要尽量通用;
- 杜绝底层switch case不同业务类型的业务逻辑代码;
- 个性化代码上浮,公共代码下沉,是更古不变的架构解耦准则;
画外音:架构复杂时,微服务是好事,但拆分不彻底反而会有坑。
第八章:架构分层
为什么互联网系统架构分层会越来越多?
当系统越来越复杂的时候,为了:
- 让上游更高效的获取与处理数据,必须复用;
- 让下游能屏蔽数据的获取细节,必须封装。
上述复用和封装,在系统架构上的呈现,就是“分层”。
每次都要连接数据库获取数据,编码非常低效,有什么痛点?
每次数据库访问,都需要:
- 创建连接,创建资源;
- 拼装SQL;
- 执行SQL并获取结果集;
- 通过游标遍历结果集,拿到每一行,分析行数据,拿到每一列;
- 关闭连接,回收资源;
很多重复的代码要编写,效率很低。
怎么优化?
分层抽象,分离DAO层。
单体架构,编码非常低效,有什么痛点?
每次数据获取,都需要:
- 关注缓存细节(Redis?MC?);
- 关注存储引擎细节(MySQL?);
- 关注分库分表;
- 关注数据路由规则;
很多重复的代码要编写,效率很低。
怎么优化?
分层抽象,分离基础服务层(微服务)。
微服务架构,编码非常低效,有什么痛点?
每次数据获取,都需要:
- 要访问很多RPC接口,获取很多公共的数据;
- 站点层与基础服务层之间的连接关系非常复杂;
- 不同垂直业务之间有需要共性业务,代码要冗余很多次;
很多重复的代码要编写,效率很低。
怎么优化?
分层抽象,分离共性业务服务层。
画外音:可以先简单理解为“中台业务服务”。
PC/H5/APP多端业务,编码非常低效,有什么痛点?
每次数据获取,都需要:
- 大部分业务逻辑相同,只有少量展现/交互不一样;
- 一旦一个服务RPC接口升级,多端都要升级;
- 一旦一个服务bug出现,多端都要升级;
- PC/H5/APP多端相同的逻辑存在大量代码拷贝;
很多重复的代码要编写,效率很低。
怎么优化?
分层抽象,前后端分离。
大数据量,高并发量的微服务架构,编码非常低效,有什么痛点?
数据库侧数据获取,往往:
- 根据业务进行数据路由,水平切分;
- 不确定路由的接口,要遍历全库;
- 有时候要多个库拿数据,然后到内存排序,例如跨库分页需求;
- …
很多微服务有很多重复的代码要编写,效率很低。
怎么优化?
分层抽象,数据库中间件。
可以看到,架构分层,对研发效率的提升,与复杂性的屏蔽,至关重要。
第九章:架构进阶
负载均衡、数据收集、服务发现、调用链跟踪。这些非业务的功能,一般是谁实现的呢?
- 互联网公司一般会有一个“架构部”,研发框架、组件、工具与技术平台;
- 业务研发部门直接使用相关框架、组件、工具与技术平台,享受各种“黑科技”带来的便利;
对于上述“黑科技”的使用与推广,存在什么问题?
框架、组件、工具与技术平台的使用与推广,往往会遇到以下一些问题:
- 业务研发团队,需要花大量时间去学习、使用基础框架与各类工具;
- 架构部,对于“黑科技”不同语言客户端的支持,往往要开发C-client,Python-client,go-client,Java-client多语言版本;
- 架构部,“黑科技” client要维护m个版本, server要维护n个版本,兼容性要测试m*n个版本;
- 每次“黑科技”的升级,都需要推动上下游进行升级,这个周期往往是以季度、半年、又甚至更久,整体效率极低;
画外音:每次fastjson漏洞升级,要1个月。
如何来进行优化?
一个思路是,解耦,将业务服务拆分成两个进程:
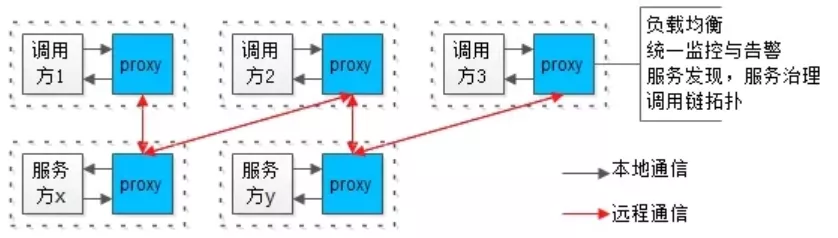
- 一个进程实现业务逻辑(不管是调用方,还是服务提供方),biz,即上图白色方块;
- 一个进程实现底层技术体系,proxy,即上图蓝色方块;
画外音:负载均衡、监控告警、服务发现与治理、调用链…等诸多基础设施,都放到这一层实现。
他们之间有这样一些特点:
- biz和proxy共同诞生,共同消亡,互为本地部署,即上图虚线方框;
- biz和proxy之间,为本地通讯,即上图黑色箭头;
- 所有biz之间的通讯,都通过proxy之间完成,proxy之间才存在远端连接,即上图红色箭头;
这样就实现了“业务的归业务,技术的归技术”,实现了充分解耦,如果所有节点都实现了解耦,整个架构会演变为:
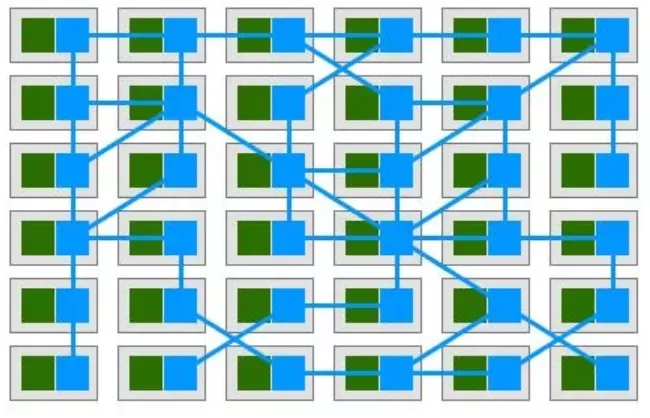
- 绿色为biz;
- 蓝色为proxy;
整个服务集群变成了网格状,这就是Service Mesh服务网格的由来。
Service Mesh的行业开源最佳实践是什么?
Istio。
Istio的架构核心是什么?
Istio架构分为两层:
- 数据平面(data plane);
- 控制平面(control plane);
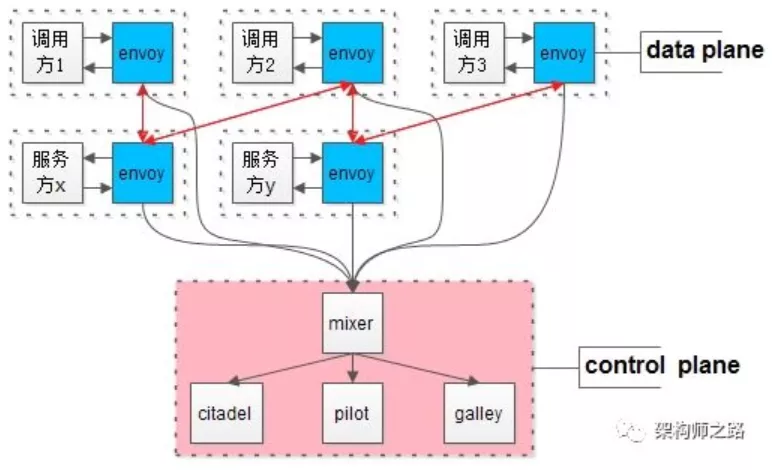
其架构核心方法论是:控制与实施分离。
画外音:具体envoy,mixer,citadel,pilot和galley的职责与细节,见《大专栏》。
前面所有章节讲的都是单机房架构,单机房架构的特点是什么?
架构分层之间,是全连接。
理想化的多机房架构,特点是什么?
架构分层之间,是同连接,即:站点,服务,数据全部单元化,仅连接同机房。
理想化的多机房架构,存在什么问题?
- 并非所有的业务都能“单元化”;
- 如果不能“单元化”,跨机房的数据同步存在较大延时;
有什么折衷方案?
可以实施“折衷多机房架构”。
什么是“折衷多机房架构”?
站点,服务,数据做不到全量单元化,做不到“只”连接同机房,但可以“最小化”跨机房连接,整个架构,可以只有两个地方跨机房:
- 数据库写库(相比读,写的比例较小);
- 数据库一处主从同步(本来就有延时);
折衷多机房架构,有什么优点?
机房区分主次,落地性强,对原有架构冲击较小,业务几乎不需要进行单元化改造。
画外音:更多多机房架构细节,详见《大专栏》。
架构师之路
架构原理
《互联网分层架构的本质》1.5W+
《互联网分层架构,为啥要前后端分离?》1.4W+
《业务层,到底需不需要服务化?》1W+
《Google的锁,才是分布式锁?》1.8W+
《MySQL双主架构,原来能这么玩》1.3W+
《七夕之夜,如何保证私密信息不泄露?》1.2W+
《框架组件,究竟要不要自研?》1.3W+
架构实践
《究竟如何保证,session一致性?》1.9W+
《三方服务挂了,服务如何不受影响?》2W+
《改了配置,却不想重启,怎么整?》1.9W+
《TCP接入层的负载均衡+高可用架构》1.1W+
《DNS,居然还能这么用?》1W+
《无锁缓存,每秒10万并发,怎么实现?》2.6W+
《P站,架构实践》2.7W+
画外音:技术,向PornHub学习。
《用户中心,1亿数据,架构如何设计?》1.5W+
《帖子中心,1亿数据,架构如何设计?》1.4W+
《好友中心,百亿关系链,架构如何设计?》1.3W+
《订单中心,1亿数据,架构如何设计?》1.9W+
画外音:不同业务,架构设计不同。
《好友状态,群友状态,推还是拉?》1W+
《网页端收消息,推还是拉?》1W+
《群消息已读回执(这个屌),推还是拉?》1.6W+
自动化
《这一步都没做,还想搞自动化运维?》1.1W+
《如何在12个小时,搞定http监控?》1.4W+
《如何在12个小时,搞定日志监控?》1.4W+
《怎样的监控,才真正说明系统有问题?》1.5W+
《不想凌晨上线,如何进行无损发布?》1.3W+
《服务挂了,怎么自动恢复?》1.3W+
多机房架构
《当年,我们是如何平滑上云的》1.1W+
《多机房多活,架构怎么玩?》1.2W+
《不停服,自顶向下的上云架构方案》1W+
MQ相关
《MQ如何实现,延时消息?》2.4W+
《MQ如何实现,消息必达?》2.4W+
《MQ如何实现,消息幂等?》1.1W+
《MQ如何实现,削峰填谷?》1.3W+
开源学习
《单机40万QPS,WF框架,今年最值得学习的开源代码》3W+
《每秒几万次MySQL交互,这个纯异步MySQL客户端开源了》1.7W+
一分钟系列
《数据库如何,垂直拆分?》1W+
《究竟什么是,动静分离?》1.1W+
《究竟什么是,读写分离?》1.5W+
《究竟什么是,前台后台分离?》2W+
《或许你不知道的12条SQL技巧》1.9W+
找工作与面试
《候选人,都是如何把面试官聊崩溃的?》1.6W+
《面试官,都是如何把候选人聊崩溃的?》2W+
《如何做一个80分的面试官?》1.4W+
画外音:今年行情不太好,跳槽务必慎重。
职场
《我是如何看管理的?》1.1W+
《管理者,别总以为自己比员工聪明》1W+
《你是老板,会不会踢了这样的员工?》1.6W+
《抢功,甩锅,如何立于不败之地?》3.6W+
画外音:带团队,比写代码更不容易。
《为什么说着说着,就骂起来了?》1.3W+
《为什么这么多人怼我?》1.2W+
《技术人,学历到底有多重要?》1.2W+
《公司发了期权,我被坑了吗?》1.9W+
画外音:职场发展类的文章,欢迎交流。
技术书籍推荐
《技术人写MySQL书籍有多难?》1.2W+
《技术人必看的技术书籍》1.8W+
画外音:不乏“七天找到女朋友”这类神作。
引人深思的
《为什么要和靠谱的人在一起?》1.3W+
《真正内心强大的人是什么样子?》1.4W+
《为什么我愿意来北上广打拼?》1.2W+
《傅盛:我为什么不顾一切的努力?》1.7W+
《男生更看重女生的身材脸蛋,还是思想?》 1.6W+
《为什么你不回我微信了》 2.1W+
《怎么判断,自己在不在一家好公司?》2.9W+
《别做被大公司毁掉的年轻人》4.3W+
画外音:把每家公司,都当成自己上升的平台。
几篇关于产品的 《滴滴的产品经理,麻烦进来看一下》1.7W+
《如何判断一个人是不是产品高手?》1W+
一篇关于war3的
《网易,这次你让粉丝们失望了》5.7W+
参考资料
系统设计面试课程(英语版) https://highscalability.com/